This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. This results in an imbalanced class distribution for training and test datasets.
Overview of Pixtral 12B Pixtral 12B, Mistrals inaugural VLM, delivers robust performance across a range of benchmarks, surpassing other open models and rivaling larger counterparts, according to Mistrals evaluation. Performance metrics and benchmarks Pixtral 12B is trained to understand both natural images and documents, achieving 52.5%
GraphStorm is a low-code enterprise graph machine learning (GML) framework to build, train, and deploy graph ML solutions on complex enterprise-scale graphs in days instead of months. allows you to define multiple training targets on different nodes and edges within a single training loop. Specifically, GraphStorm 0.3
Sonnet currently ranks at the top of S&P AI Benchmarks by Kensho , which assesses large language models (LLMs) for finance and business. For example, there could be leakage of benchmark datasets’ questions and answers into training data. Anthropic Claude 3.5 Kensho is the AI Innovation Hub for S&P Global.
In this post, we describe the enhancements to the forecasting capabilities of SageMaker Canvas and guide you on using its user interface (UI) and AutoML APIs for time-series forecasting. While the SageMaker Canvas UI offers a code-free visual interface, the APIs empower developers to interact with these features programmatically.
Amazon Bedrock , a fully managed service offering high-performing foundation models from leading AI companies through a single API, has recently introduced two significant evaluation capabilities: LLM-as-a-judge under Amazon Bedrock Model Evaluation and RAG evaluation for Amazon Bedrock Knowledge Bases. 0]}-{evaluator_model.split('.')[0]}-{datetime.now().strftime('%Y-%m-%d-%H-%M-%S')}"
Each models tokenization strategy is defined by its provider during training and cant be modified. Consider benchmarking your user experience to find the best latency for your use case, considering that most humans cant read faster than 225 words per minute and therefore extremely fast response can hinder user experience.
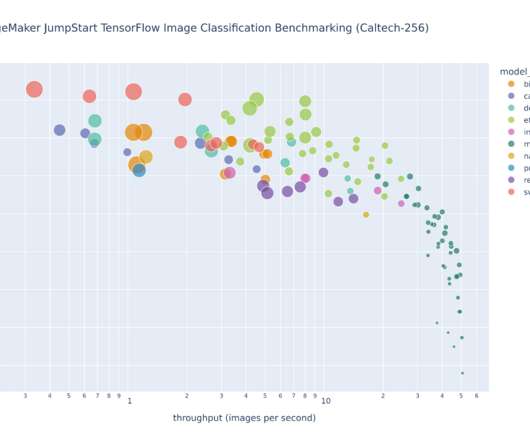
This post explores these relationships via a comprehensive benchmarking of LLMs available in Amazon SageMaker JumpStart, including Llama 2, Falcon, and Mistral variants. We provide theoretical principles on how accelerator specifications impact LLM benchmarking. Additionally, models are fully sharded on the supported instance.
Performance metrics and benchmarks According to Mistral, the instruction-tuned version of the model achieves over 81% accuracy on Massive Multitask Language Understanding (MMLU) with 150 tokens per second latency, making it currently the most efficient model in its category. It doesnt support Converse APIs or other Amazon Bedrock tooling.
Discover how the fully managed infrastructure of SageMaker enables high-performance, low cost ML throughout the ML lifecycle, from building and training to deploying and managing models at scale. AWS Trainium and AWS Inferentia deliver high-performance AI training and inference while reducing your costs by up to 50%.
NVIDIA Nemotron-4 is now available on Amazon SageMaker JumpStart , significantly expanding the range of high-quality, pre-trained models available to our customers. This integration provides a powerful multilingual model that excels in reasoning benchmarks. Mixtral 8x7B Instruct v0.1:
Amazon Bedrock is a fully managed service that offers a choice of high-performing Foundation Models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon via a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
Many use cases involve using pre-trained large language models (LLMs) through approaches like Retrieval Augmented Generation (RAG). Fine-tuning is a supervised training process where labeled prompt and response pairs are used to further train a pre-trained model to improve its performance for a particular use case.
Amazon SageMaker is a fully-managed service for ML, and SageMaker model training is an optimized compute environment for high-performance training at scale. SageMaker model training offers a remote training experience with a seamless control plane to easily train and reproduce ML models at high performance and low cost.
Training these gigantic models is challenging and requires complex distribution strategies. Data scientists and machine learning engineers are constantly looking for the best way to optimize their training compute, yet are struggling with the communication overhead that can increase along with the overall cluster size. on 256 GPUs.
This text-to-video API generates high-quality, realistic videos quickly from text and images. Trained on the Amazon SageMaker HyperPod , Dream Machine excels in creating consistent characters, smooth motion, and dynamic camera movements. Luma AI’s recently launched Dream Machine represents a significant advancement in this field.
However, training these gigantic networks from scratch requires a tremendous amount of data and compute. For smaller NLP datasets, a simple yet effective strategy is to use a pre-trained transformer, usually trained in an unsupervised fashion on very large datasets, and fine-tune it on the dataset of interest. training script.
You can also either use the SageMaker Canvas UI, which provides a visual interface for building and deploying models without needing to write any code or have any ML expertise, or use its automated machine learning (AutoML) APIs for programmatic interactions.
The plentiful and jointly trained parameters of DL models have a large representational capacity that brought improvements in numerous customer use cases, including image and speech analysis, natural language processing (NLP), time series processing, and more. The challenge with DL training.
Modern model pre-training often calls for larger cluster deployment to reduce time and cost. At the server level, such training workloads demand faster compute and increased memory allocation. As models grow to hundreds of billions of parameters, they require a distributed training mechanism that spans multiple nodes (instances).
Certain machine learning (ML) workloads, such as training computer vision models or reinforcement learning, often involve combining the GPU- or accelerator-intensive task of neural network model training with the CPU-intensive task of data preprocessing, like image augmentation. Performance benchmark results.
Model training forms the core of any machine learning (ML) project, and having a trained ML model is essential to adding intelligence to a modern application. Generally speaking, training a model from scratch is time-consuming and compute intensive. Model training in Studio. This post showcases the results of the study.
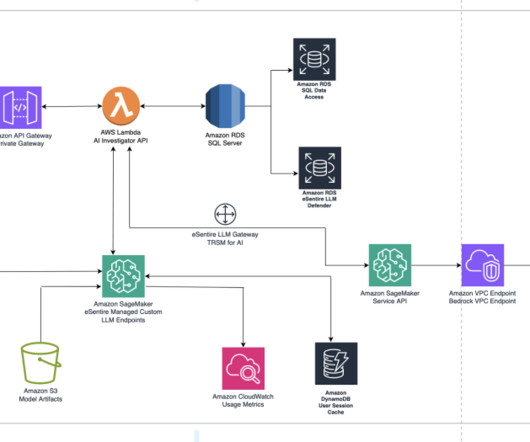
The solution focuses on the fundamental principles of developing an AI/ML application workflow of data preparation, model training, model evaluation, and model monitoring. It is already trained on tens of millions of images across many categories. API Gateway calls the Lambda function to obtain the pet attributes.
A common way to select an embedding model (or any model) is to look at public benchmarks; an accepted benchmark for measuring embedding quality is the MTEB leaderboard. The Massive Text Embedding Benchmark (MTEB) evaluates text embedding models across a wide range of tasks and datasets. on reranking tasks, for example.
They enable applications requiring very low latency or local data processing using familiar APIs and tool sets. Through comparative benchmarking tests, we illustrate how deploying FMs in Local Zones closer to end users can significantly reduce latencya critical factor for real-time applications such as conversational AI assistants.
Amazon SageMaker is a fully managed service that enables developers and data scientists to quickly and easily build, train, and deploy machine learning (ML) models at scale. SageMaker makes it easy to deploy models into production directly through API calls to the service. SageMaker provides a variety of options to deploy models.
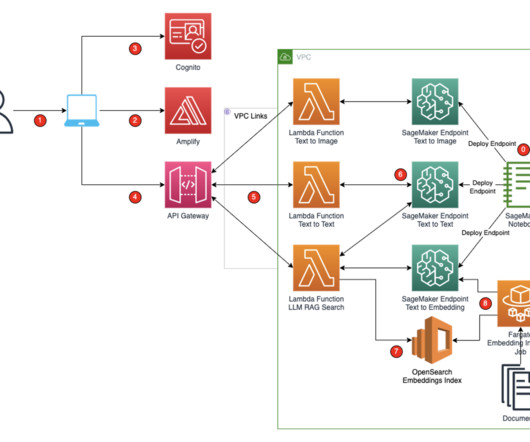
It’s powered by large language models (LLMs) that are pre-trained on vast amounts of data and commonly referred to as foundation models (FMs). These SageMaker endpoints are consumed in the Amplify React application through Amazon API Gateway and AWS Lambda functions. You access the React application from your computer.
Together, these AI-driven tools and technologies aren’t just reshaping how brands perform marketing tasks; they’re setting new benchmarks for what’s possible in customer engagement. It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing data pipelines.
As shown in the preceding figure, the ML paradigm is learning (training) followed by inference. In terms of resulting speedups, the approximate order is programming hardware, then programming against PBA APIs, then programming in an unmanaged language such as C++, then a managed language such as Python.
To date, we have developed over 70 internal and external offerings, tools, and mechanisms that support responsible AI, published or funded over 500 research papers, studies, and scientific blogs on responsible AI, and delivered tens of thousands of hours of responsible AI training to our Amazon employees.
And an ML researcher may ask questions like: “How can I generate my own fair comparison of multiple model architectures against a specified dataset while controlling training hyperparameters and computer specifications, such as GPUs, CPUs, and RAM?” swin-large-patch4-window7-224 195.4M efficientnet-v2-imagenet21k-ft1k-l 118.1M
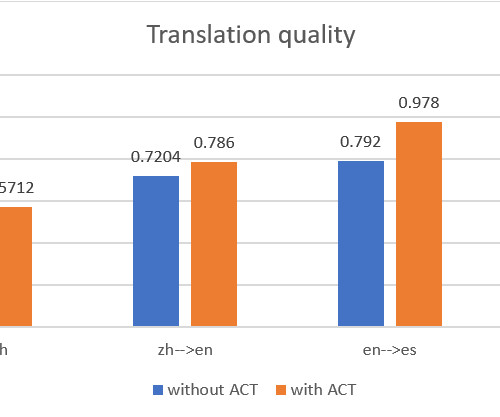
We demonstrate how to use the AWS Management Console and Amazon Translate public API to deliver automatic machine batch translation, and analyze the translations between two language pairs: English and Chinese, and English and Spanish. First, we put the source documents, reference documents, and parallel data training set in an S3 bucket.
RAG is the process of optimizing the output of a large language model (LLM) so it references an authoritative knowledge base outside of its training data sources before generating a response. What is RAG? Long input-context length – Jina Embeddings v2 models support 8,192 input tokens.
Use APIs and middleware to bridge gaps between CPQ and existing enterprise systems, ensuring smooth data flow. Automate Price Calculations and Adjustments Utilize real-time pricing engines within CPQ to dynamically calculate prices based on market trends, cost fluctuations, and competitor benchmarks.
Building ML models involves preparing the data for training, extracting features, and then training and fine-tuning the model using the features. The procedure is further simplified with the use of Inference Recommender , a right-sizing and benchmarking tool built inside SageMaker. large two-core machine.
A foundation model (FM) is an LLM that has undergone unsupervised pre-training on a corpus of text. A foundation model (FM) is an LLM that has undergone unsupervised pre-training on a corpus of text. This further step updates the FM by training with data labeled by security experts (such as Q&A pairs and investigation conclusions).
An approach to product stewardship with generative AI Large language models (LLMs) are trained with vast amounts of information crawled from the internet, capturing considerable knowledge from multiple domains. However, their knowledge is static and tied to the data used during the pre-training phase.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models from leading AI companies and Amazon via a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. The GSM8K train set comprises 7,473 records.
Foundation models are large deep learning models trained on a vast quantity of data at scale. The most prominent category is large-language models (LLM), including auto-regressive models such as GPT variants trained to complete natural text. FlashAttention is introduced in Dao et al. 24xlarge instances.
For example, you can immediately start detecting entities such as people, places, commercial items, dates, and quantities via the Amazon Comprehend console , AWS Command Line Interface , or Amazon Comprehend APIs. Amazon Comprehend simplifies your model training work significantly. Dataset preparation.
Because the hyper-personalization of models requires unique models to be trained and deployed, the number of models scales linearly with the number of clients, which can become costly. In addition, deployments are now as simple as calling Boto3 SageMaker APIs and attaching the proper auto scaling policies.
We train an XGBoost model for a classification task on a credit card fraud dataset. An advanced job is a custom load test job that allows you to perform extensive benchmarks based on your ML application SLA requirements, such as latency, concurrency, and traffic pattern. Deploy the trained model to a SageMaker real-time endpoint.
This is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API. When summarizing healthcare texts, pre-trained LLMs do not always achieve optimal performance.
Snowflake Arctic is a family of enterprise-grade large language models (LLMs) built by Snowflake to cater to the needs of enterprise users, exhibiting exceptional capabilities (as shown in the following benchmarks ) in SQL querying, coding, and accurately following instructions.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content