This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
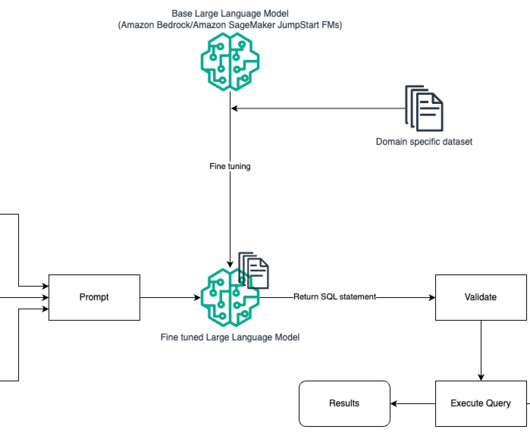
In this post, we provide an introduction to text to SQL (Text2SQL) and explore use cases, challenges, design patterns, and bestpractices. Today, a large amount of data is available in traditional data analytics, data warehousing, and databases, which may be not easy to query or understand for the majority of organization members.
In this post, we will continue to build on top of the previous solution to demonstrate how to build a private API Gateway via Amazon API Gateway as a proxy interface to generate and access Amazon SageMaker presigned URLs. The user invokes createStudioPresignedUrl API on API Gateway along with a token in the header.
Customers can use the SageMaker Studio UI or APIs to specify the SageMaker Model Registry model to be shared and grant access to specific AWS accounts or to everyone in the organization. It also helps achieve data, project, and team isolation while supporting software development lifecycle bestpractices.
It allows developers to build and scale generative AI applications using FMs through an API, without managing infrastructure. You can choose from various FMs from Amazon and leading AI startups such as AI21 Labs, Anthropic, Cohere, and Stability AI to find the model that’s best suited for your use case.
Managing bias, intellectual property, prompt safety, and data integrity are critical considerations when deploying generative AI solutions at scale. Because this is an emerging area, bestpractices, practical guidance, and design patterns are difficult to find in an easily consumable basis.
Make sure to use bestpractices for rate limiting, backoff and retry, and load shedding. This pattern achieves a statically stable architecture, which is a resiliency bestpractice. Although generative AI applications have some interesting nuances, the existing resilience patterns and bestpractices still apply.
By following bestpractices for your digital transformation framework, you also get the benefit of flexibility so you can add and subtract digital tools as your company’s needs change. 10 BestPractices to Develop a Framework for Digital Transformation. What Is a Digital Transformation Framework?
The underlying technologies of composability include some combination of artificial intelligence (AI), machine learning, automation, container-based architecture, bigdata, analytics, low-code and no-code development, Agile/DevOps deployment, cloud delivery, and applications with open APIs (microservices).
Open APIs: An open API model is advantageous in that it allows developers outside of companies to easily access and use APIs to create breakthrough innovations. At the same time, however, publicly available APIs are also exposed ones. billion GB of data were being produced every day in 2012 alone!)
To achieve these operational benefits, they implemented a number of bestpractice processes, including a fast data iteration and testing cycle, and parallel testing to find optimal data combinations. We can then call a Forecast API to create a dataset group and import data from the processed S3 bucket.
This solution uses an Amazon Cognito user pool as an OAuth-compatible identity provider (IdP), which is required in order to exchange a token with AWS IAM Identity Center and later on interact with the Amazon Q Business APIs. Amazon Q uses the chat_sync API to carry out the conversation.
In the era of bigdata and AI, companies are continually seeking ways to use these technologies to gain a competitive edge. At the core of these cutting-edge solutions lies a foundation model (FM), a highly advanced machine learning model that is pre-trained on vast amounts of data. tar czvf model.tar.gz -C deepspeed.
Agents automatically call the necessary APIs to interact with the company systems and processes to fulfill the request. The App calls the Claims API Gateway API to run the claims proxy passing user requests and tokens. Claims API Gateway runs the Custom Authorizer to validate the access token.
Applications and services can call the deployed endpoint directly or through a deployed serverless Amazon API Gateway architecture. To learn more about real-time endpoint architectural bestpractices, refer to Creating a machine learning-powered REST API with Amazon API Gateway mapping templates and Amazon SageMaker.
In this post, we address these limitations by implementing the access control outside of the MLflow server and offloading authentication and authorization tasks to Amazon API Gateway , where we implement fine-grained access control mechanisms at the resource level using Identity and Access Management (IAM). Adds an IAM authorizer.
Join leading smart home service provider Vivint’s Ben Austin and Jacob Miller for an enlightening session on how they have designed and utilized automated speech analytics to extract KPI targeted scores and route those critical insights through an API to their own customized dashboard to track and coach on agent scoring/behaviors.
It stores history of ML features in the offline store (Amazon S3) and also provides APIs to an online store to allow low-latency reads of most recent features. With purpose-built services, the Amp team was able to release the personalized show recommendation API as described in this post to production in under 3 months. Conclusion.
With some of the best FMs available at their fingertips within Amazon Bedrock, customers are experimenting and innovating faster than ever before. With over 35 patents granted across various technology domains, she has a passion for continuous innovation and using data to drive business outcomes.
To test the model output, we use a Jupyter notebook to run Python code to detect custom labels in a supplied image by calling Amazon Rekognition APIs. The solution workflow is as follows: Store satellite imagery data in Amazon S3 as the input source. Store satellite imagery data in Amazon S3 as an input source.
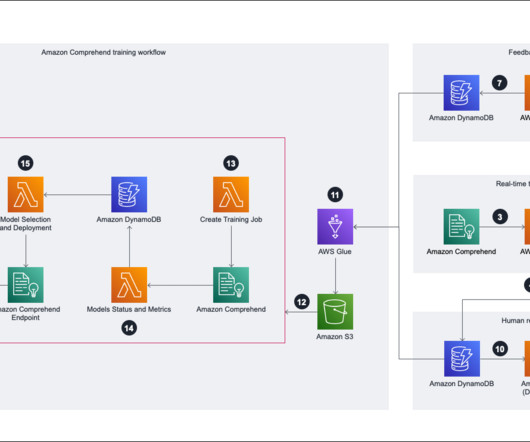
In this post, we explore how AWS customer Pro360 used the Amazon Comprehend custom classification API , which enables you to easily build custom text classification models using your business-specific labels without requiring you to learn machine learning (ML), to improve customer experience and reduce operational costs.
As you scale your models, projects, and teams, as a bestpractice we recommend that you adopt a multi-account strategy that provides project and team isolation for ML model development and deployment. They provide a fact sheet of the model that is important for model governance. Solutions Architect at Amazon Web Services (AWS).
We set the OutputFormat to mp3 , which tells Amazon Polly to generate an audio stream for this API call. We again use the start_speech_synthesis_task method but specify OutputFormat to json , which tells Amazon Polly to generate speech marks for this API call. Anil Kodali is a Solutions Architect with Amazon Web Services.
When the message is received by the SQS queue, it triggers the AWS Lambda function to make an API call to the Amp catalog service. The Lambda function retrieves the desired show metadata, filters the metadata, and then sends the output metadata to Amazon Kinesis Data Streams. Data Engineer for Amp on Amazon.
This example notebook demonstrates the pattern of using Feature Store as a central repository from which data scientists can extract training datasets. In addition to creating a training dataset, we use the PutRecord API to put the 1-week feature aggregations into the online feature store nightly. Nov-01,22:01:00 1 74.99 …9843 99.50
They use bigdata (such as a history of past search queries) to provide many powerful yet easy-to-use patent tools. In this section, we show how to build your own container, deploy your own GPT-2 model, and test with the SageMaker endpoint API. implement the model and the inference API. gpt2 and predictor.py
You can change the configuration later from the SageMaker Canvas UI or using SageMaker APIs. Staying up to date with the latest developments and bestpractices can be challenging, especially in a public forum. He helps customers implement bigdata, machine learning, analytics solutions, and generative AI implementations.
Edge is a term that refers to a location, far from the cloud or a bigdata center, where you have a computer device (edge device) capable of running (edge) applications. How do I eliminate the need of installing a big framework like TensorFlow or PyTorch on my restricted device? Edge computing.
After ingestion, images can be searched via the Amazon Kendra search console, API, or SDK. You can then search for images using natural language queries, such as “Find images of red roses” or “Show me pictures of dogs playing in the park,” through the Amazon Kendra console, SDK, or API.
Refer to Operating model for bestpractices regarding a multi-account strategy for ML. When a new version of the model is registered in the model registry, it triggers a notification to the responsible data scientist via Amazon SNS. The central model registry could optionally be placed in a shared services account as well.
The underlying technologies of composability include some combination of artificial intelligence (AI), machine learning, automation, container-based architecture, bigdata, analytics, low-code and no-code development, Agile/DevOps deployment, cloud delivery, and applications with open APIs (microservices).
Prior to our adoption of Kubeflow on AWS, our data scientists used a standardized set of tools and a process that allowed flexibility in the technology and workflow used to train a given model. This means that user access can be controlled on the Kubeflow UI but not over the Kubernetes API via Kubectl.
But modern analytics goes beyond basic metricsit leverages technologies like call center data science, machine learning models, and bigdata to provide deeper insights. Predictive Analytics: Uses historical data to forecast future events like call volumes or customer churn. What is contact center bigdata analytics?
SaaS works well for a variety of general use cases, including: Data backup. Bigdata analytics. Flexibility – SaaS uses an open API (application programming interface) technology. BestPractices to Align Your Sales and Support Teams. It doesn’t discriminate! Email platforms. Disaster recovery.
With all the available customer data companies have at their disposal to enhance the performance of customer service, sales, and marketing efforts, a remarkable 73% of companies still do not use it effectively. And out of those who do practise data collection, only 12% analyze it. BestPractices of Customer Data Management.
The statement labeled RemoveErrorMessagesFromConsole can be removed without affecting the ability to get into Studio, but will result in API errors on the console UI. An example IAM policy for an ML administrator may look like the following code. Note that the following policy locks down Studio domain creation to VPC only.
Despite significant advancements in bigdata and open source tools, niche Contact Center Business Intelligence providers are still wed to their own proprietary tools leaving them saddled with technical debt and an inability to innovate from within. Together, we can develop bestpractices and sharable templates for the entire industry.
As you scale your models, projects, and teams, as a bestpractice we recommend that you adopt a multi-account strategy that provides project and team isolation for ML model development and deployment. They provide a fact sheet of the model that is important for model governance. Solutions Architect at Amazon Web Services (AWS).
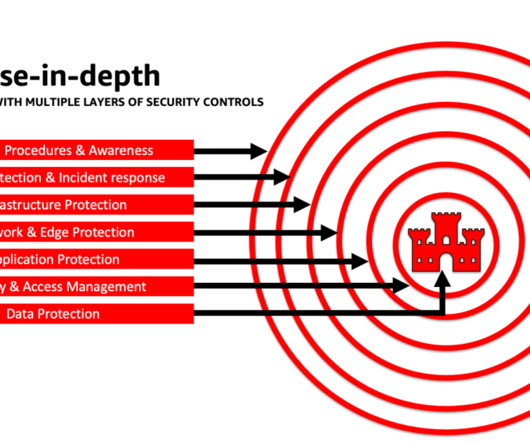
The goal of this post is to empower AI and machine learning (ML) engineers, data scientists, solutions architects, security teams, and other stakeholders to have a common mental model and framework to apply security bestpractices, allowing AI/ML teams to move fast without trading off security for speed.
The Senior Back-End Software Engineer will have demonstrated practical experience in building high-performance and reliable systems and possess a love for Git and all that version control provides (we can also accept a love/hate relationship with Git). Maintain and develop Stratifyd’s API layer and/or analytics pipeline.
From our experience, artifact server has some limitations, such as limits on artifact size (because of sending it using REST API). Environment variables : Set environment variables, such as model paths, API keys, and other necessary parameters. The main parts we use are tracking the server and model registry.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
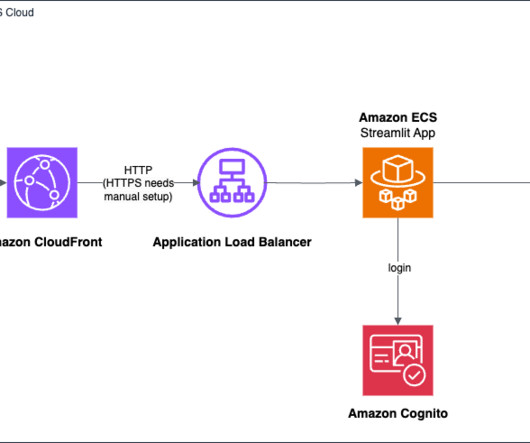
Before using this application in a production environment, you should thoroughly review and implement appropriate security measures, such as configuring HTTPS on the load balancer and following AWS bestpractices for securing your resources. See the README.md file in the GitHub repository for more information.
Because SageMaker Model Cards and SageMaker Model Registry were built on separate APIs, it was challenging to associate the model information and gain a comprehensive view of the model development lifecycle. We walk through an example notebook to demonstrate how you can use this unification during the model development data science lifecycle.
Some key considerations include: Scalability and performance For handling large volumes of proposals and concurrent users, a serverless architecture using AWS Lambda , Amazon API Gateway , DynamoDB, and Amazon Simple Storage Service (Amazon S3) would provide improved scalability, availability, and reliability.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















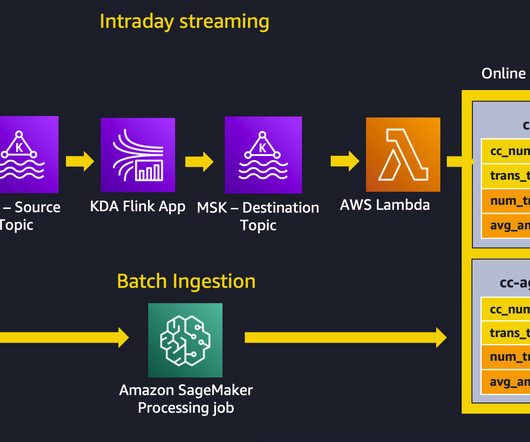




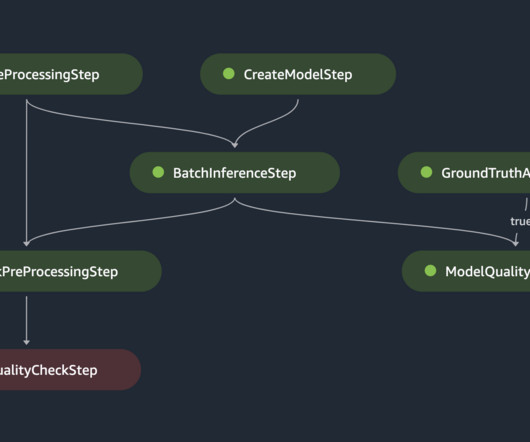






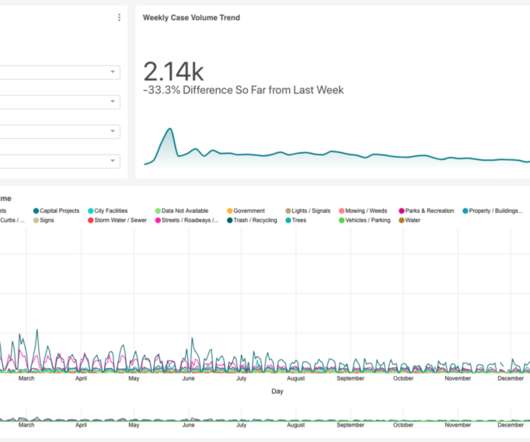













Let's personalize your content