This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
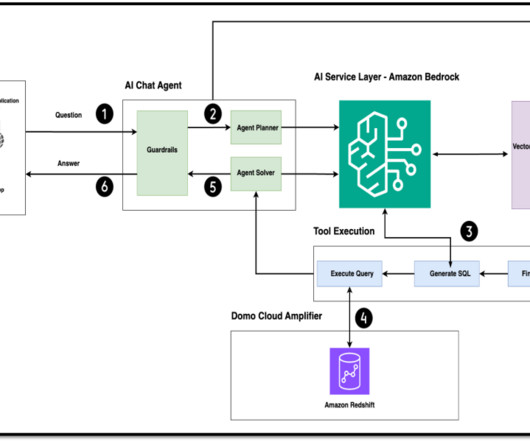
Amazon Bedrock announces the preview launch of Session Management APIs, a new capability that enables developers to simplify state and context management for generative AI applications built with popular open source frameworks such as LangGraph and LlamaIndex. Building generative AI applications requires more than model API calls.
Fine-tuning pre-trained language models allows organizations to customize and optimize the models for their specific use cases, providing better performance and more accurate outputs tailored to their unique data and requirements. Amazon Bedrock prioritizes security through a comprehensive approach to protect customer data and AI workloads.
Implementing RAG-based applications requires careful attention to security, particularly when handling sensitive data. The protection of personally identifiable information (PII), protected health information (PHI), and confidential business data is crucial because this information flows through RAG systems.
Better data Automated data collection and analysis means fewer mistakes and more consistent results. Security is paramount, and we adhere to AWS bestpractices across the layers. API Gateway plays a complementary role by acting as the main entry point for external applications, dashboards, and enterprise integrations.
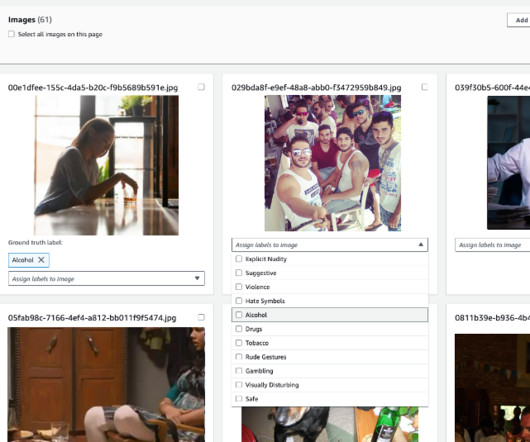
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. For the multiclass classification problem to label support case data, synthetic data generation can quickly result in overfitting.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. API Gateway is serverless and hence automatically scales with traffic. API Gateway also provides a WebSocket API. At this point, you need to consider the use case and data isolation requirements.
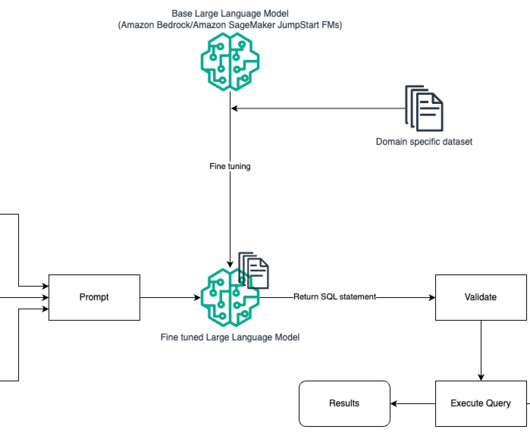
One such area that is evolving is using natural language processing (NLP) to unlock new opportunities for accessing data through intuitive SQL queries. Instead of dealing with complex technical code, business users and data analysts can ask questions related to data and insights in plain language.
Concerns about legal implications, accuracy of AI-generated outputs, data privacy, and broader societal impacts have underscored the importance of responsible AI development. This can be useful when you have requirements for sensitive data handling and user privacy.
Recently, we’ve been witnessing the rapid development and evolution of generative AI applications, with observability and evaluation emerging as critical aspects for developers, data scientists, and stakeholders. This feature allows you to separate data into logical partitions, making it easier to analyze and process data later.
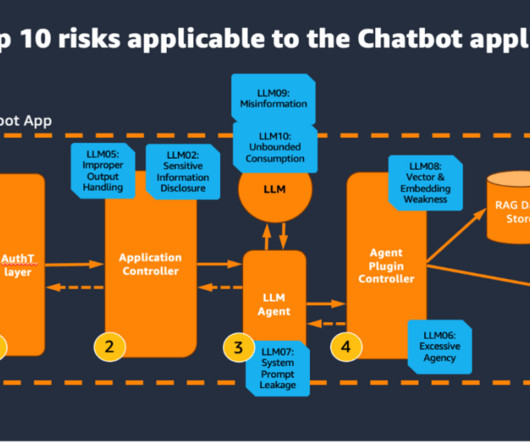
These steps might involve both the use of an LLM and external data sources and APIs. Agent plugin controller This component is responsible for the API integration to external data sources and APIs. Amazon Cognito complements these defenses by enabling user authentication and data synchronization.
Generative AIpowered assistants such as Amazon Q Business can be configured to answer questions, provide summaries, generate content, and securely complete tasks based on data and information in your enterprise systems. This capability supports various use cases such as IT, HR, and help desk.
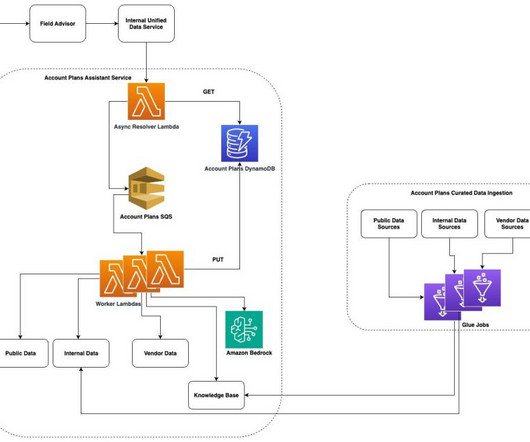
Business use cases The account plans draft assistant serves four primary use cases: Account plan draft generation: Using Amazon Bedrock, weve made internal and external data sources available to generate draft content for key sections of the APs. Lets explore how we built this AI assistant and some of our future plans.
Amazon Bedrock Knowledge Bases offers a fully managed Retrieval Augmented Generation (RAG) feature that connects large language models (LLMs) to internal data sources. We provide the upstream components, including document ingestion and query formatting, as static data instead of code.
Some customers entrust Amazon Transcribe with data that is confidential and proprietary to their business. In other cases, audio content processed by Amazon Transcribe may contain sensitive data that needs to be protected to comply with local laws and regulations. For more information about data privacy, see the Data Privacy FAQ.
We cover the key scenarios where scaling to zero is beneficial, provide bestpractices for optimizing scale-up time, and walk through the step-by-step process of implementing this functionality. We also discuss bestpractices for implementation and strategies to mitigate potential drawbacks.
The new ApplyGuardrail API enables you to assess any text using your preconfigured guardrails in Amazon Bedrock, without invoking the FMs. In this post, we demonstrate how to use the ApplyGuardrail API with long-context inputs and streaming outputs. For example, you can now use the API with models hosted on Amazon SageMaker.
Furthermore, evaluation processes are important not only for LLMs, but are becoming essential for assessing prompt template quality, input data quality, and ultimately, the entire application stack. SageMaker is a data, analytics, and AI/ML platform, which we will use in conjunction with FMEval to streamline the evaluation process.
Traditional automation approaches require custom API integrations for each application, creating significant development overhead. Add the Amazon Bedrock Agents supported computer use action groups to your agent using CreateAgentActionGroup API. Prerequisites AWS Command Line Interface (CLI), follow instructions here.
Amazon Bedrock Flows offers an intuitive visual builder and a set of APIs to seamlessly link foundation models (FMs), Amazon Bedrock features, and AWS services to build and automate user-defined generative AI workflows at scale. Test the flow Youre now ready to test the flow through the Amazon Bedrock console or API.
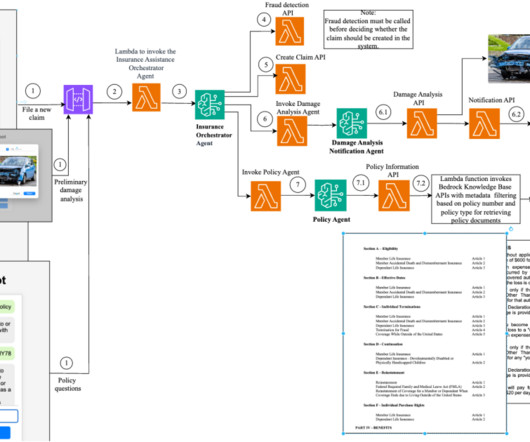
Intricate workflows that require dynamic and complex API orchestration can often be complex to manage. In this post, we explore how chaining domain-specific agents using Amazon Bedrock Agents can transform a system of complex API interactions into streamlined, adaptive workflows, empowering your business to operate with agility and precision.
In this post, we seek to address this growing need by offering clear, actionable guidelines and bestpractices on when to use each approach, helping you make informed decisions that align with your unique requirements and objectives. Optimized for cost-effective performance, they are trained on data in over 200 languages.
Amazon Bedrock , a fully managed service offering high-performing foundation models from leading AI companies through a single API, has recently introduced two significant evaluation capabilities: LLM-as-a-judge under Amazon Bedrock Model Evaluation and RAG evaluation for Amazon Bedrock Knowledge Bases.
This article outlines 10 CPQ bestpractices to help optimize your performance, eliminate inefficiencies, and maximize ROI. Use APIs and middleware to bridge gaps between CPQ and existing enterprise systems, ensuring smooth data flow.
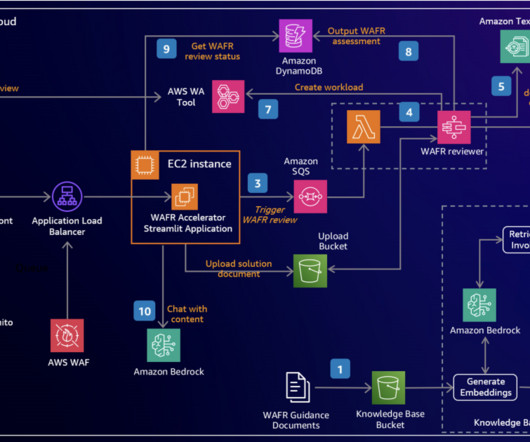
Building cloud infrastructure based on proven bestpractices promotes security, reliability and cost efficiency. We demonstrate how to harness the power of LLMs to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on AWS Well-Architected bestpractices.
Enterprise data by its very nature spans diverse data domains, such as security, finance, product, and HR. Data across these domains is often maintained across disparate data environments (such as Amazon Aurora , Oracle, and Teradata), with each managing hundreds or perhaps thousands of tables to represent and persist business data.
The technical sessions covering generative AI are divided into six areas: First, we’ll spotlight Amazon Q , the generative AI-powered assistant transforming software development and enterprise data utilization. We’ll cover Amazon Bedrock Agents , capable of running complex tasks using your company’s systems and data.
However, adoption of these FMs involves addressing some key challenges, including quality output, data privacy, security, integration with organization data, cost, and skills to deliver. Organizations must also carefully manage data privacy and security risks that arise from processing proprietary data with FMs.
Customers can use the SageMaker Studio UI or APIs to specify the SageMaker Model Registry model to be shared and grant access to specific AWS accounts or to everyone in the organization. The model is then A/B tested along with the use case in pre-production with production-like data settings and approved for deployment to the next stage.
With GraphStorm, you can build solutions that directly take into account the structure of relationships or interactions between billions of entities, which are inherently embedded in most real-world data, including fraud detection scenarios, recommendations, community detection, and search/retrieval problems. Specifically, GraphStorm 0.3
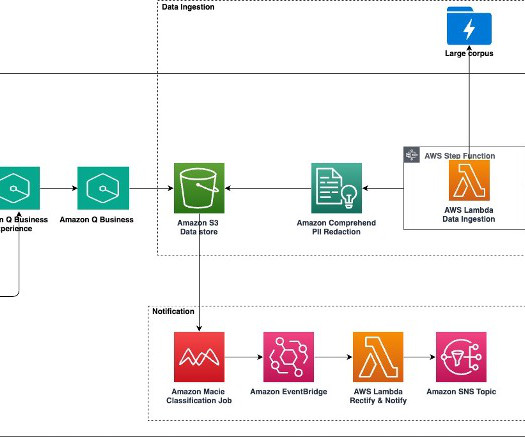
Amazon Q Business , a new generative AI-powered assistant, can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in an enterprises systems. Large-scale data ingestion is crucial for applications such as document analysis, summarization, research, and knowledge management.
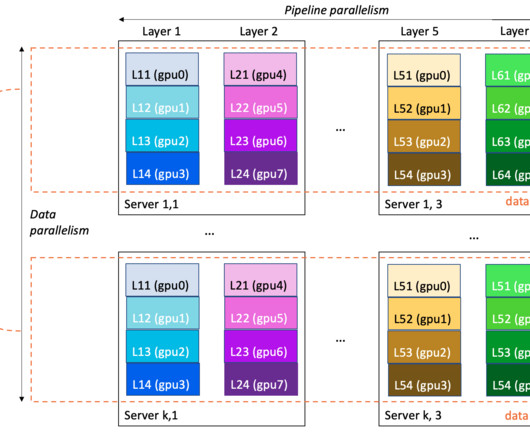
The size of an LLM and its training data is a double-edged sword: it brings modeling quality, but entails infrastructure challenges. In this post, we dive into tips and bestpractices for successful LLM training on Amazon SageMaker Training. Some of the bestpractices in this post refer specifically to ml.p4d.24xlarge
SageMaker Pipelines offers ML application developers the ability to orchestrate different steps of the ML workflow, including data loading, data transformation, training, tuning, and deployment. In this post, we provide some bestpractices to maximize the value of SageMaker Pipelines and make the development experience seamless.
However, the technology also comes with considerable data security and privacy concerns. Maximizing your investment in AI means navigating these roadblocks without compromising on privacy and data security for sensitive company info, customer data, and proprietary information.
This two-part series explores bestpractices for building generative AI applications using Amazon Bedrock Agents. Part 2 discusses architectural considerations and development lifecycle practices. Ground your data in real customer interactions that reflect actual use cases but be sure to de-identify and anonymize the data.
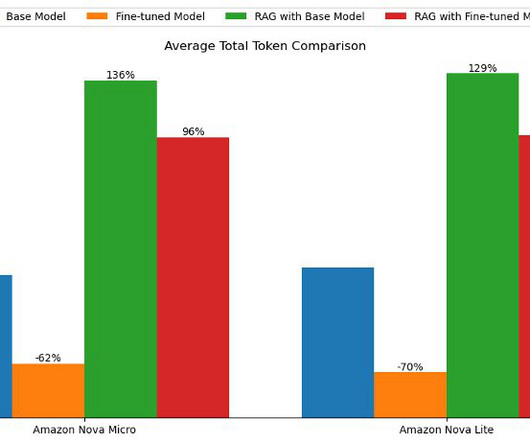
By fine-tuning, the LLM can adapt its knowledge base to specific data and tasks, resulting in enhanced task-specific capabilities. In this post, we explore the bestpractices and lessons learned for fine-tuning Anthropic’s Claude 3 Haiku on Amazon Bedrock. A well-curated dataset forms the foundation for successful fine-tuning.
The opportunities to unlock value using AI in the commercial real estate lifecycle starts with data at scale. Although CBRE provides customers their curated best-in-class dashboards, CBRE wanted to provide a solution for their customers to quickly make custom queries of their data using only natural language prompts.
Solution overview To get started with Nova Canvas and Nova Reel, you can either use the Image/Video Playground on the Amazon Bedrock console or access the models through APIs. When writing a video generation prompt for Nova Reel, be mindful of the following requirements and bestpractices: Prompts must be no longer than 512 characters.
In this post, we discuss how to use the Custom Moderation feature in Amazon Rekognition to enhance the accuracy of your pre-trained content moderation API. Introducing Amazon Rekognition Custom Moderation You can now enhance the accuracy of the Rekognition moderation model for your business-specific data with the Custom Moderation feature.
Numerous customers face challenges in managing diverse data sources and seek a chatbot solution capable of orchestrating these sources to offer comprehensive answers. It allows you to retrieve data from sources beyond the foundation model, enhancing prompts by integrating contextually relevant retrieved data.
With SageMaker, data scientists and developers can quickly and easily build and train ML models, and then directly deploy them into a production-ready hosted environment. It provides an integrated Jupyter authoring notebook instance for easy access to your data sources for exploration and analysis, so you don’t have to manage servers.
Data insights are crucial for businesses to enable data-driven decisions, identify trends, and optimize operations. Generative artificial intelligence (AI) has revolutionized this by allowing users to interact with data through natural language queries, providing instant insights and visualizations without needing technical expertise.
This post focuses on doing RAG on heterogeneous data formats. We first introduce routers, and how they can help managing diverse data sources. We then give tips on how to handle tabular data and will conclude with multimodal RAG, focusing specifically on solutions that handle both text and image data.
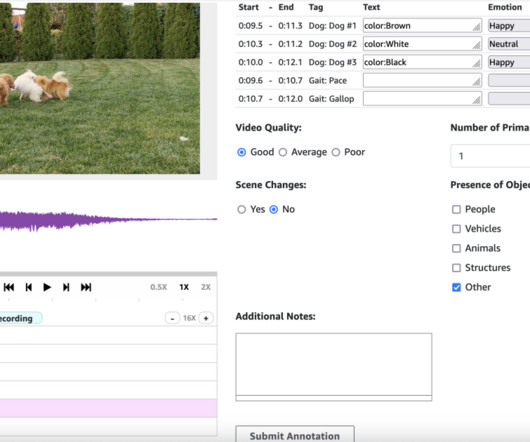
This setup enables the model to learn from human-labeled data, refining its ability to produce content that aligns with natural human expectations. Importance of high-quality data and reducing labeling errors High-quality data is essential for training generative AI models that can produce natural, human-like audio and video content.
To build a generative AI -based conversational application integrated with relevant data sources, an enterprise needs to invest time, money, and people. First, you would need build connectors to the data sources. For a full list of supported data source connectors, see Amazon Q Business connectors.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content