This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Using SageMaker with MLflow to track experiments The fully managed MLflow capability on SageMaker is built around three core components: MLflow tracking server This component can be quickly set up through the Amazon SageMaker Studio interface or using the API for more granular configurations.
This work extends upon the post Generating value from enterprise data: Bestpractices for Text2SQL and generative AI. The top-level definitions of these abstractions are included as part of the prompt context for query generation, and the full definitions are provided to the SQL execution engine, along with the generated query.
Although were using admin privileges for the purpose of this post, its a security bestpractice to apply least privilege permissions and grant only the permissions required to perform a task. This involves creating an OAuth API endpoint in ServiceNow and using the web experience URL from Amazon Q Business as the callback URL.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Traditional automation approaches require custom API integrations for each application, creating significant development overhead. Add the Amazon Bedrock Agents supported computer use action groups to your agent using CreateAgentActionGroup API. Prerequisites AWS Command Line Interface (CLI), follow instructions here.
In this post, we provide some bestpractices to maximize the value of SageMaker Pipelines and make the development experience seamless. Bestpractices for SageMaker Pipelines In this section, we discuss some bestpractices that can be followed while designing workflows using SageMaker Pipelines.
You liked the overall experience and now want to deploy the bot in your production environment, but aren’t sure about bestpractices for Amazon Lex. In this post, we review the bestpractices for developing and deploying Amazon Lex bots, enabling you to streamline the end-to-end bot lifecycle and optimize your operations.
This two-part series explores bestpractices for building generative AI applications using Amazon Bedrock Agents. This data provides a benchmark for expected agent behavior, including the interaction with existing APIs, knowledge bases, and guardrails connected with the agent.
Because many data scientists may lack experience in the acceleration training process, in this post we show you the factors that matter for fast deep learning model training and the bestpractices of acceleration training for TensorFlow 1.x We discuss bestpractices in the following areas: Accelerate training on a single instance.
In this post, we explore the bestpractices and lessons learned for fine-tuning Anthropic’s Claude 3 Haiku on Amazon Bedrock. We discuss the important components of fine-tuning, including use case definition, data preparation, model customization, and performance evaluation.
Designing the prompt Before starting any scaled use of generative AI, you should have the following in place: A clear definition of the problem you are trying to solve along with the end goal. Refer to Getting started with the API to set up your environment to make Amazon Bedrock requests through the AWS API. client = boto3.client("bedrock-runtime",
You can deploy or fine-tune models through an intuitive UI or APIs, providing flexibility for all skill levels. Task definition (count_task) This is a task that we want this agent to execute. Amazon SageMaker JumpStart offers a diverse selection of open and proprietary FMs from providers like Hugging Face, Meta, and Stability AI.
Find out what it takes to deliver winning service and sales experiences across channelsincluding the best omnichannel contact center software options to support your efforts in 2025. 5 Essential Omnichannel Contact Center BestPractices Implementing and managing an omnichannel contact center is anything but a set-it-and-forget it affair.
This configuration takes the form of a Directed Acyclic Graph (DAG) represented as a JSON pipeline definition. The DevOps engineer can then use the Kubernetes APIs provided by ACK to submit the pipeline definition and initiate one or more pipeline runs in SageMaker. amazonaws.com/sagemaker-xgboost:1.7-1",
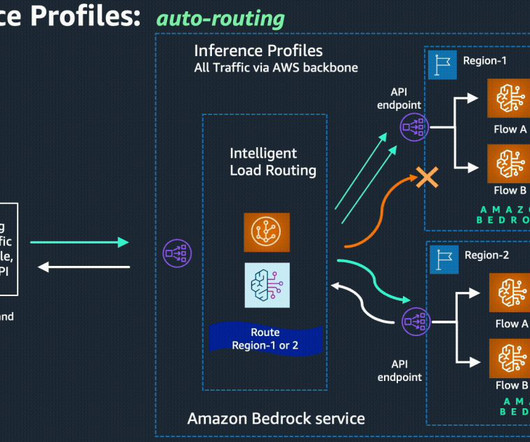
Moreover, this capability prioritizes the connected Amazon Bedrock API source/primary region when possible, helping to minimize latency and improve responsiveness. Compatibility with existing Amazon Bedrock API No additional routing or data transfer cost and you pay the same price per token for models as in your source/primary region.
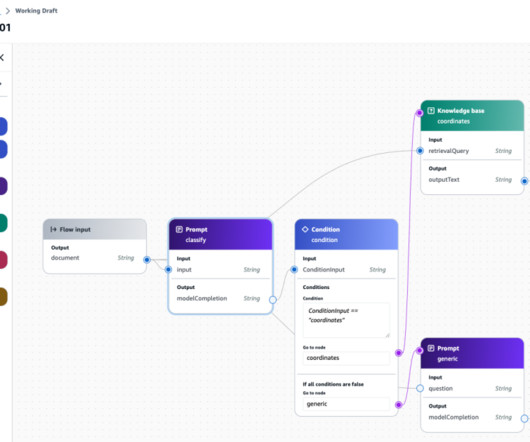
You can use the Prompt Management and Flows features graphically on the Amazon Bedrock console or Amazon Bedrock Studio, or programmatically through the Amazon Bedrock SDK APIs. These approaches allow for the definition of more sophisticated logic and dynamic workflows, often called prompt flows.
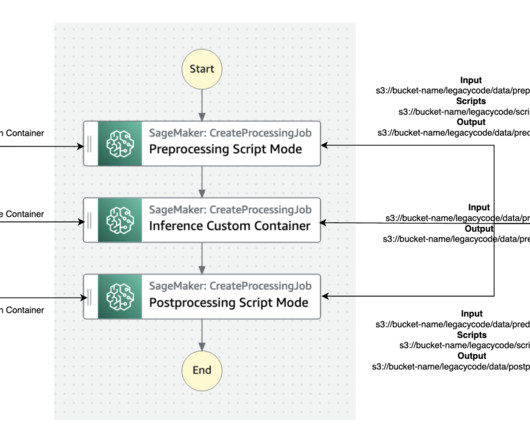
The bestpractice for migration is to refactor these legacy codes using the Amazon SageMaker API or the SageMaker Python SDK. Step Functions is a serverless workflow service that can control SageMaker APIs directly through the use of the Amazon States Language.
The following figure shows schema definition and model which reference it. From our experience, artifact server has some limitations, such as limits on artifact size (because of sending it using REST API). This can be achieved by enabling the awslogs log driver within the logConfiguration parameters of the task definitions.
For interacting with AWS services, the AWS Amplify JS library for React simplifies the authentication, security, and API requests. The backend uses several serverless and event-driven AWS services, including AWS Step Functions for low-code workflows, AWS AppSync for a GraphQL API, and Amazon Translate. 1 – Translating a document.
This is the second instalment in our list of call center bestpractices. So, is setting up a virtual call center a piece of call center bestpractice? But it’s definitely worth investigating the option. IVR testing definitely is call center bestpractice. Good – let’s get started.
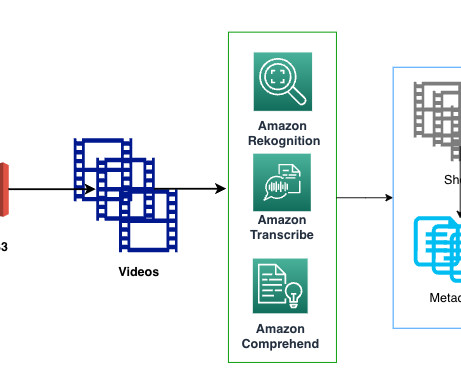
Amazon Transcribe The transcription for the entire video is generated using the StartTranscriptionJob API. The solution runs Amazon Rekognition APIs for label detection , text detection, celebrity detection , and face detection on videos. The metadata generated for each video by the APIs is processed and stored with timestamps.
Apart from GPU provisioning, this setup also required data scientists to build a REST API wrapper for each model, which was needed to provide a generic interface for other company services to consume, and to encapsulate preprocessing and postprocessing of model data. Two MMEs were created at Veriff, one for staging and one for production.
The next stage is the extraction phase, where you pass the collected invoices and receipts to the Amazon Textract AnalyzeExpense API to extract financially related relationships between text such as vendor name, invoice receipt date, order date, amount due, amount paid, and so on. It is available both as a synchronous or asynchronous API.
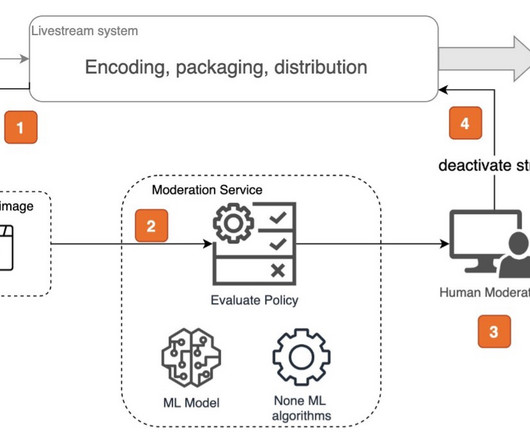
In this post, we explain the common practice of live stream visual moderation with a solution that uses the Amazon Rekognition Image API to moderate live streams. There are charges for Amazon S3 storage, Amazon S3 API calls that Amazon IVS makes on behalf of the customer, and serving the stored video to viewers.
JSONs inherently structured format allows for clear and organized representation of complex data such as table schemas, column definitions, synonyms, and sample queries. The produced query should be functional, efficient, and adhere to bestpractices in SQL query optimization.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon with a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
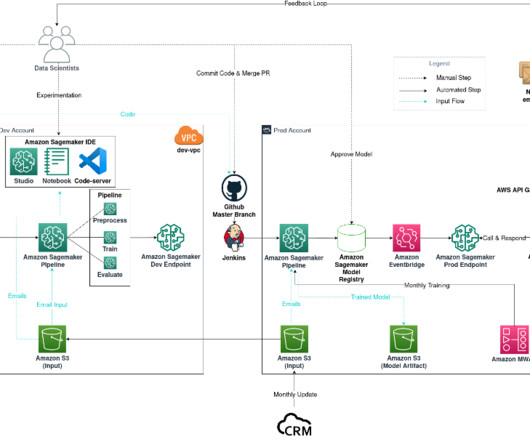
MLOps – Because the SageMaker endpoint is private and can’t be reached by services outside of the VPC, an AWS Lambda function and Amazon API Gateway public endpoint are required to communicate with CRM. The function then relays the classification back to CRM through the API Gateway public endpoint.
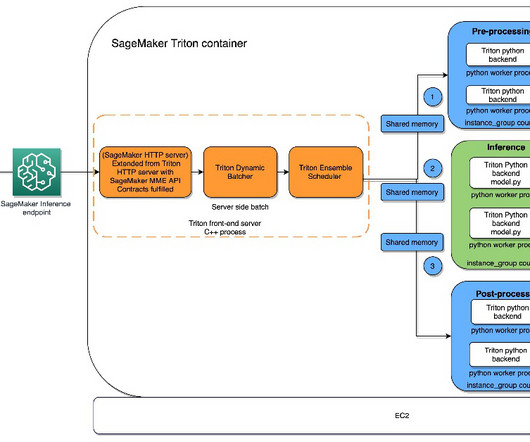
Triton with PyTorch backend The PyTorch backend is designed to run TorchScript models using the PyTorch C++ API. In the container definition, define the ModelDataUrl to specify the S3 directory that contains all the models that the SageMaker MME will use to load and serve predictions. tar -C triton-serve-pt/ -czf resnet_pt_v0.tar.gz
Because we wanted to track the metrics of an ongoing training job and compare them with previous training jobs, we just had to parse this StdOut by defining the metric definitions through regex to fetch the metrics from StdOut for every epoch. amazonaws.com/tensorflow-training:2.11.0-cpu-py39-ubuntu20.04-sagemaker", cpu-py39-ubuntu20.04-sagemaker",
Building proofs of concept is relatively straightforward because cutting-edge foundation models are available from specialized providers through a simple API call. Cohere language models in Amazon Bedrock The Cohere Platform brings language models with state-of-the-art performance to enterprises and developers through a simple API call.
Here are some bestpractices for personalizing bulk SMS campaigns: a. Some people will definitely reply to your texts for more information about your service/offer. Thanks to SMS gateways and APIs, you can schedule and automatically send pre-written messages to thousands of customers today. and boost engagement.
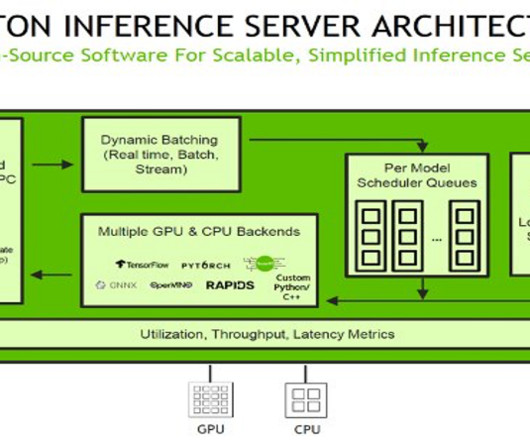
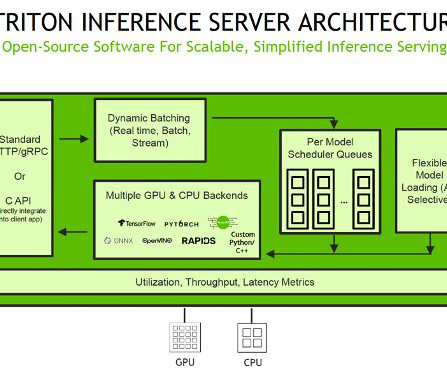
To use TensorRT as a backend for Triton Inference Server, you need to create a TensorRT engine from your trained model using the TensorRT API. Inference requests arrive at the server via either HTTP/REST or by the C API , and are then routed to the appropriate per-model scheduler. Firstly, we need to define the serving container.
By using the Framework, you will learn operational and architectural bestpractices for designing and operating reliable, secure, efficient, cost-effective, and sustainable workloads in the cloud. The AWS Well-Architected Framework helps you understand the benefits and risks of decisions you make while building workloads on AWS.
Agents automatically call the necessary APIs to interact with the company systems and processes to fulfill the request. The App calls the Claims API Gateway API to run the claims proxy passing user requests and tokens. Claims API Gateway runs the Custom Authorizer to validate the access token.
For more information about bestpractices, refer to the AWS re:Invent 2019 talk, Build accurate training datasets with Amazon SageMaker Ground Truth. For this we use AWS Step Functions , a serverless workflow service that provides us with API integrations to quickly orchestrate and visualize the steps in our workflow.
In this post, we address these limitations by implementing the access control outside of the MLflow server and offloading authentication and authorization tasks to Amazon API Gateway , where we implement fine-grained access control mechanisms at the resource level using Identity and Access Management (IAM). Adds an IAM authorizer.
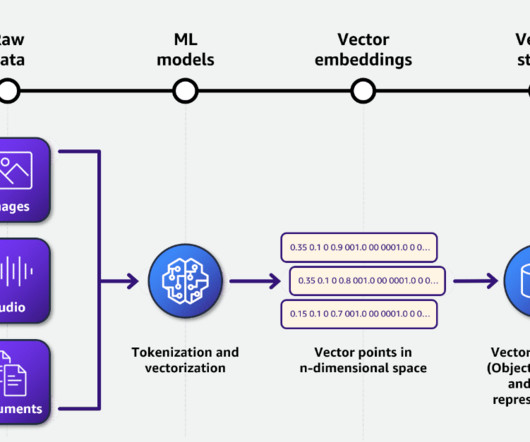
This often means the method of using a third-party LLM API won’t do for security, control, and scale reasons. It provides an approachable, robust Python API for the full infrastructure stack of ML/AI, from data and compute to workflows and observability. The following figure illustrates this workflow.
You can also create the Data Catalog definition using the Amazon Athena create database and create table statements. Collaborators can use the AWS Clean Rooms console, APIs, or AWS SDKs to set up a collaboration. Clean up It’s a bestpractice to delete resources that are no longer being used.
It has APIs for common ML data preprocessing operations like parallel transformations, shuffling, grouping, and aggregations. It provides simple drop-in replacements for XGBoost’s train and predict APIs while handling the complexities of distributed data management and training under the hood.
Standardize building and reuse of AI solutions across business functions and AI practitioners’ personas, while ensuring adherence to enterprise bestpractices: Automate and standardize the repetitive undifferentiated engineering effort. Amazon Simple Storage Service (Amazon S3) object storage acts as a content data lake.
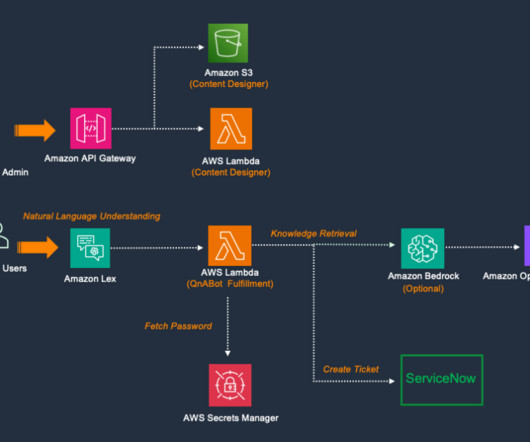
The workflow includes the following steps: A QnABot administrator can configure the questions using the Content Designer UI delivered by Amazon API Gateway and Amazon Simple Storage Service (Amazon S3). For all other parameters, accept the defaults (see the implementation guide for parameter definitions), and launch the QnABot stack.
Inference requests arrive at the server via either HTTP/REST or by the C API and are then routed to the appropriate per-model scheduler. SageMaker MMEs offer capabilities for running multiple deep learning or ML models on the GPU at the same time with Triton Inference Server, which has been extended to implement the MME API contract.
They want to be able to easily try the latest models, and also test to see which capabilities and features will give them the best results and cost characteristics for their use cases. With Amazon Bedrock, customers are only ever one API call away from a new model. Meta Llama 2 70B, and additions to the Amazon Titan family.
Yara has built APIs using Amazon API Gateway to expose the sensor data to applications such as ELC. SageMaker Model Monitor APIs offer data and model quality monitoring. The deployment account contains the CI/CD pipeline definition and is capable of deploying to the DEV, TEST, and PROD accounts. Onboarding a new use case.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content