This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
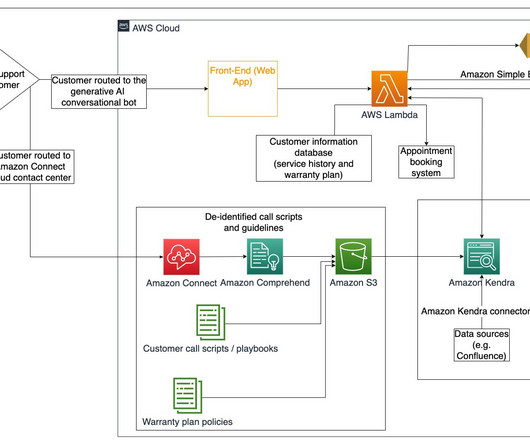
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
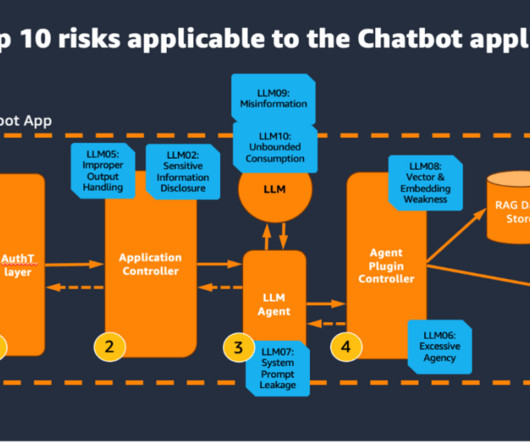
These steps might involve both the use of an LLM and external data sources and APIs. Agent plugin controller This component is responsible for the API integration to external data sources and APIs. The LLM agent is an orchestrator of a set of steps that might be necessary to complete the desired request.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon with a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
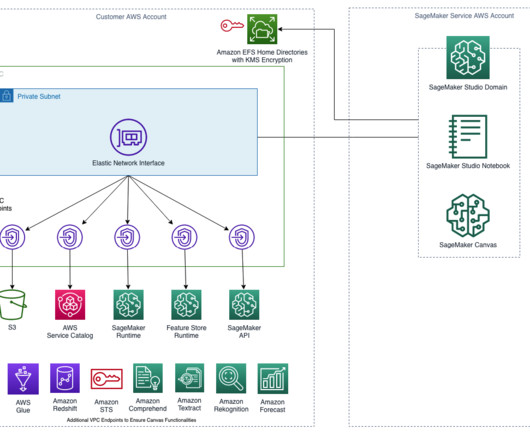
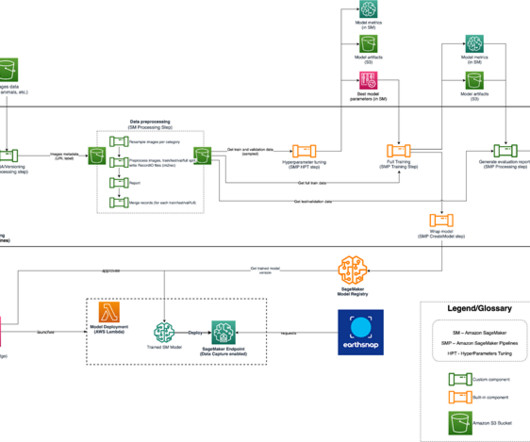
Customers can use the SageMaker Studio UI or APIs to specify the SageMaker Model Registry model to be shared and grant access to specific AWS accounts or to everyone in the organization. It also helps achieve data, project, and team isolation while supporting software development lifecycle bestpractices.
In this post, we dive into tips and bestpractices for successful LLM training on Amazon SageMaker Training. The post covers all the phases of an LLM training workload and describes associated infrastructure features and bestpractices. Some of the bestpractices in this post refer specifically to ml.p4d.24xlarge
Because many data scientists may lack experience in the acceleration training process, in this post we show you the factors that matter for fast deep learning model training and the bestpractices of acceleration training for TensorFlow 1.x We discuss bestpractices in the following areas: Accelerate training on a single instance.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon via a single API. This is because such tasks require organization-specific data and workflows that typically need custom programming.
This post describes the bestpractices for load testing a SageMaker endpoint to find the right configuration for the number of instances and size. Note that the model container also includes any custom inference code or scripts that you have passed for inference.
This two-part series explores bestpractices for building generative AI applications using Amazon Bedrock Agents. This data provides a benchmark for expected agent behavior, including the interaction with existing APIs, knowledge bases, and guardrails connected with the agent.
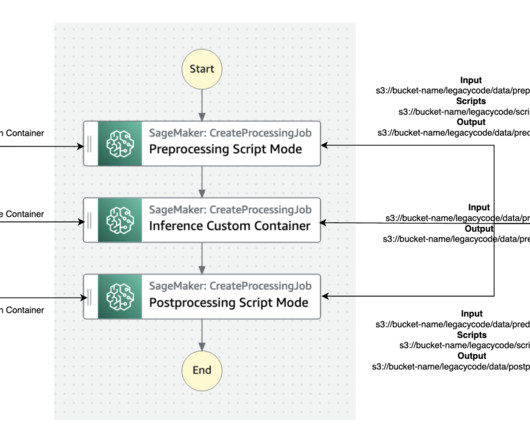
The bestpractice for migration is to refactor these legacy codes using the Amazon SageMaker API or the SageMaker Python SDK. SageMaker runs the legacy script inside a processing container. SageMaker takes your script, copies your data from Amazon Simple Storage Service (Amazon S3), and then pulls a processing container.
Refer to Getting started with the API to set up your environment to make Amazon Bedrock requests through the AWS API. Test the code using the native inference API for Anthropics Claude The following code uses the native inference API to send a text message to Anthropics Claude. client = boto3.client("bedrock-runtime",
At the forefront of this evolution sits Amazon Bedrock , a fully managed service that makes high-performing foundation models (FMs) from Amazon and other leading AI companies available through an API. System integration – Agents make API calls to integrated company systems to run specific actions.
Some links for security bestpractices are shared below but we strongly recommend reaching out to your account team for detailed guidance and to discuss the appropriate security architecture needed for a secure and compliant deployment. model API exposed by SageMaker JumpStart properly. define bot express greeting "Hey there!"
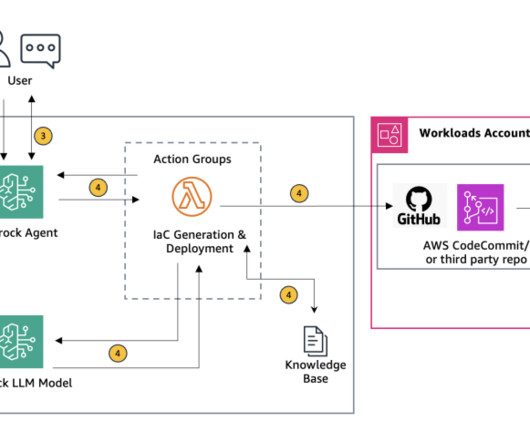
This solution uses Retrieval Augmented Generation (RAG) to ensure the generated scripts adhere to organizational needs and industry standards. In this blog post, we explore how Agents for Amazon Bedrock can be used to generate customized, organization standards-compliant IaC scripts directly from uploaded architecture diagrams.
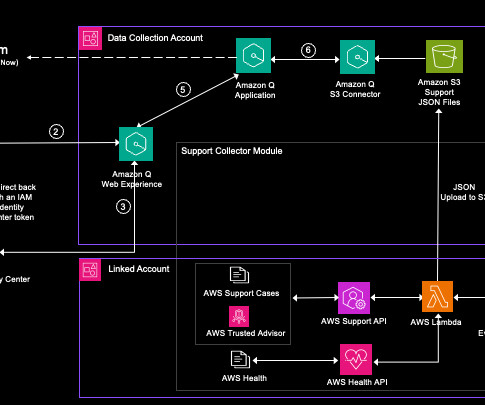
This post shows how to use AWS generative artificial intelligence (AI) services , like Amazon Q Business , with AWS Support cases, AWS Trusted Advisor , and AWS Health data to derive actionable insights based on common patterns, issues, and resolutions while using the AWS recommendations and bestpractices enabled by support data.
The AWS Well-Architected Framework provides bestpractices and guidelines for designing and operating reliable, secure, efficient, and cost-effective systems in the cloud. It calls the CreateDataSource and DeleteDataSource APIs. Minimally, you must specify the following properties: Name – Specify a name for the knowledge base.
The first allows you to run a Python script from any server or instance including a Jupyter notebook; this is the quickest way to get started. In the following sections, we first describe the script solution, followed by the AWS CDK construct solution. The following diagram illustrates the sequence of events within the script.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API. The scripts for fine-tuning and evaluation are available on the GitHub repository.
We recommend running similar scripts only on your own data sources after consulting with the team who manages them, or be sure to follow the terms of service for the sources that youre trying to fetch data from. As a security bestpractice, storing the client application data in Secrets Manager is recommended.
We provide a step-by-step guide to deploy your SageMaker trained model to Graviton-based instances, cover bestpractices when working with Graviton, discuss the price-performance benefits, and demo how to deploy a TensorFlow model on a SageMaker Graviton instance. The inference script URI is needed in the INFERENCE_SCRIPT_S3_LOCATION.
AWS Prototyping successfully delivered a scalable prototype, which solved CBRE’s business problem with a high accuracy rate (over 95%) and supported reuse of embeddings for similar NLQs, and an API gateway for integration into CBRE’s dashboards. The following diagram illustrates the web interface and API management layer.
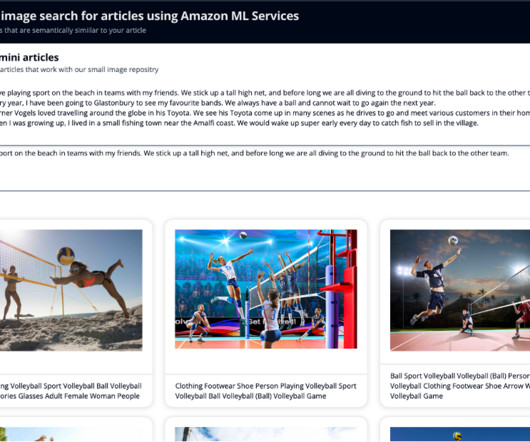
Amazon Rekognition makes it easy to add image analysis capability to your applications without any machine learning (ML) expertise and comes with various APIs to fulfil use cases such as object detection, content moderation, face detection and analysis, and text and celebrity recognition, which we use in this example.
Image 2: Hugging Face NLP model inference performance improvement with torch.compile on AWS Graviton3-based c7g instance using Hugging Face example scripts. This section shows how to run inference in eager and torch.compile modes using torch Python wheels and benchmarking scripts from Hugging Face and TorchBench repos.
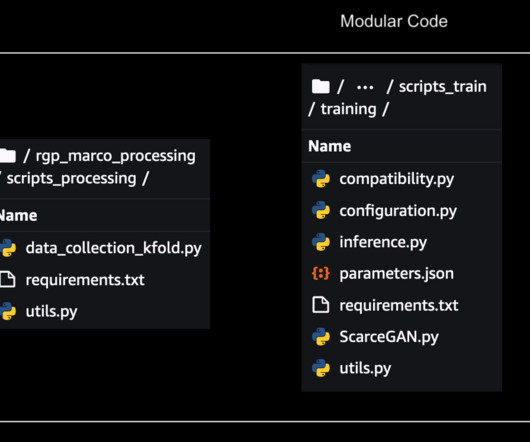
The code to invoke the pipeline script is available in the Studio notebooks, and we can change the hyperparameters and input/output when invoking the pipeline. This is quite different from our earlier method where we had all the parameters hard coded within the scripts and all the processes were inextricably linked.
IaC ensures that customer infrastructure and services are consistent, scalable, and reproducible while following bestpractices in the area of development operations (DevOps). This is required to communicate with the SageMaker API. SageMaker runtime: com.amazonaws.region.sagemaker.runtime.
Integrating security in our workflow Following the bestpractices of the Security Pillar of the Well-Architected Framework , Amazon Cognito is used for authentication. Amazon API Gateway hosts a REST API with various endpoints to handle user requests that are authenticated using Amazon Cognito.
Applications and services can call the deployed endpoint directly or through a deployed serverless Amazon API Gateway architecture. To learn more about real-time endpoint architectural bestpractices, refer to Creating a machine learning-powered REST API with Amazon API Gateway mapping templates and Amazon SageMaker.
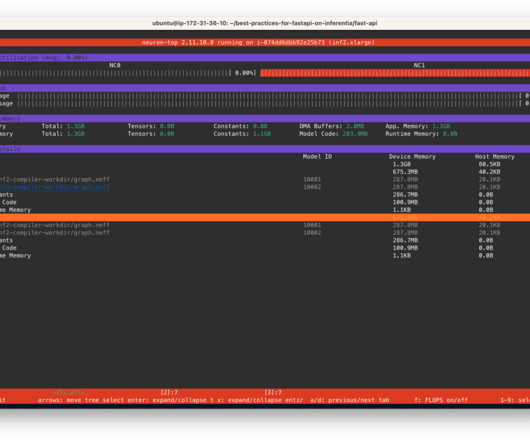
If the model changes on the server side, the client has to know and change its API call to the new endpoint accordingly. In this post, we share bestpractices to deploy deep learning models with FastAPI on AWS Inferentia NeuronCores. script in the fastapi and trace-model folders use this to create Docker images.
Furthermore, TechSee’s technology can be integrated anywhere through APIs or SDKs. To ensure that new technologies are embraced and utilized to their fullest, they must be integrated smoothly into the existing agent dashboards and scripts, requiring minimal shifts from established routines.
Furthermore, TechSee’s technology can be integrated anywhere through APIs or SDKs. To ensure that new technologies are embraced and utilized to their fullest, they must be integrated smoothly into the existing agent dashboards and scripts, requiring minimal shifts from established routines.
In this post, we present a comprehensive guide on deploying and running inference using the Stable Diffusion inpainting model in two methods: through JumpStart’s user interface (UI) in Amazon SageMaker Studio , and programmatically through JumpStart APIs available in the SageMaker Python SDK.
This often means the method of using a third-party LLM API won’t do for security, control, and scale reasons. It provides an approachable, robust Python API for the full infrastructure stack of ML/AI, from data and compute to workflows and observability. The following figure illustrates this workflow.
For more information about bestpractices, refer to the AWS re:Invent 2019 talk, Build accurate training datasets with Amazon SageMaker Ground Truth. For this we use AWS Step Functions , a serverless workflow service that provides us with API integrations to quickly orchestrate and visualize the steps in our workflow.
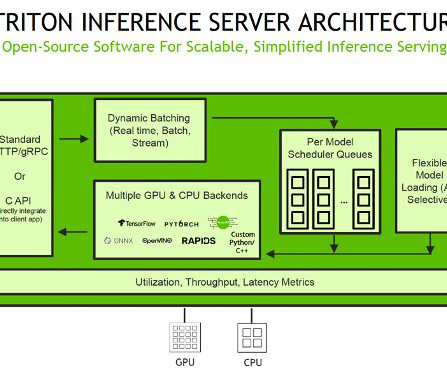
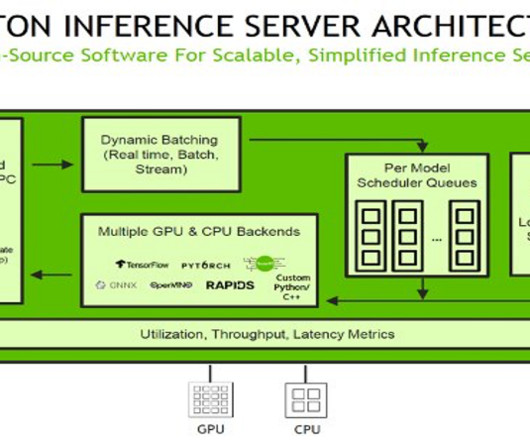
To use TensorRT as a backend for Triton Inference Server, you need to create a TensorRT engine from your trained model using the TensorRT API. Inference requests arrive at the server via either HTTP/REST or by the C API , and are then routed to the appropriate per-model scheduler. script from the following cell.
Creates an API Gateway that adds an additional layer of security between the web app user interface and Lambda. Wait until the script provisions all the required resources and finishes running. Copy the API Gateway URL that the AWS CDK script prints out and save it. (We The S3 path to the movie node file.
Triton with PyTorch backend The PyTorch backend is designed to run TorchScript models using the PyTorch C++ API. Alternatively, you can use ensemble models or business logic scripting. file in the workspace directory contains scripts to load and save a PyTorch model. client(service_name="sagemaker") runtime_sm_client = boto3.client("sagemaker-runtime")
Solution overview To get responses streamed back from SageMaker, you can use our new InvokeEndpointWithResponseStream API. To take advantage of the new streaming API, you need to make sure the model container returns the streamed response as chunked encoded data. We use Streamlit for the sample demo application UI.
The ML components for data ingestion, preprocessing, and model training were available as disjointed Python scripts and notebooks, which required a lot of manual heavy lifting on the part of engineers. The initial solution also required the support of a technical third party, to release new models swiftly and efficiently.
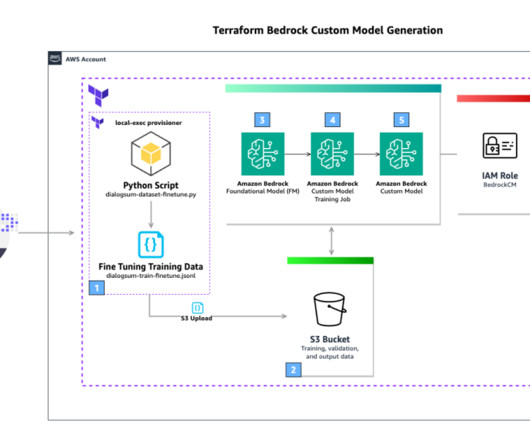
The workflow includes the following steps: The user runs the terraform apply The Terraform local-exec provisioner is used to run a Python script that downloads the public dataset DialogSum from the Hugging Face Hub. file you have been working in and add the terraform_data resource type, uses a local provisioner to invoke your Python script.
Each stage in the ML workflow is broken into discrete steps, with its own script that takes input and output parameters. In the following code, the desired number of actors is passed in as an input argument to the script. Let’s look at sections of the scripts that perform this data preprocessing. get("OfflineStoreConfig").get("S3StorageConfig").get("ResolvedOutputS3Uri")
In this post, we address these limitations by implementing the access control outside of the MLflow server and offloading authentication and authorization tasks to Amazon API Gateway , where we implement fine-grained access control mechanisms at the resource level using Identity and Access Management (IAM). Adds an IAM authorizer.
With SageMaker Processing, you can bring your own custom processing scripts and choose to build a custom container or use a SageMaker managed container with common frameworks like scikit-learn, Lime, Spark and more. Alternatively, you can use the list_processing_jobs API. You can choose from two methods to do this.
As recommended by AWS as a bestpractice , customers have used separate accounts to simplify policy management for users and isolate resources by workloads and account. You can deploy the management account resources by running the following command: /scripts/organization-deployment/deploy-management-account.sh aws/config.
Lifecycle configurations (LCCs) are shell scripts to automate customization for your Studio environments, such as installing JupyterLab extensions, preloading datasets, and setting up source code repositories. LCC scripts are triggered by Studio lifecycle events, such as starting a new Studio notebook. Apply the script (see below).
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















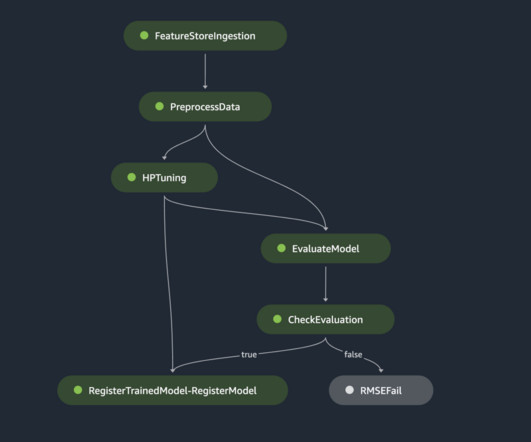

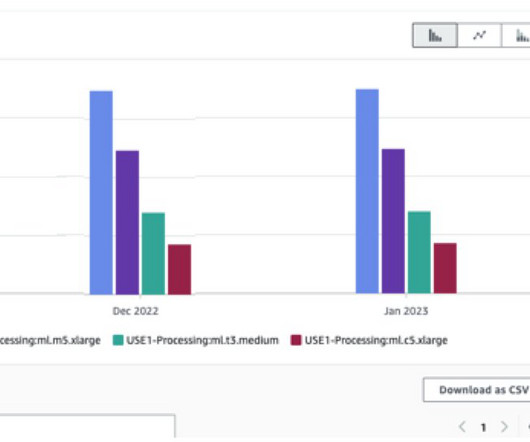
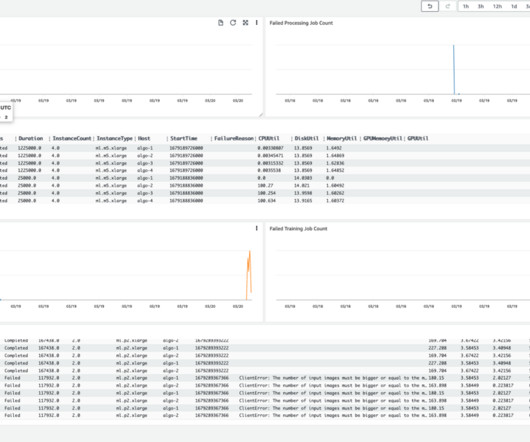










Let's personalize your content