This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Fine-tuning pre-trained language models allows organizations to customize and optimize the models for their specific use cases, providing better performance and more accurate outputs tailored to their unique data and requirements. Model customization in Amazon Bedrock involves the following actions: Create training and validation datasets.
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. This results in an imbalanced class distribution for training and test datasets.
You need trained people and specialized equipment, and you often must shut things down during inspection. Security is paramount, and we adhere to AWS bestpractices across the layers. API Gateway plays a complementary role by acting as the main entry point for external applications, dashboards, and enterprise integrations.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
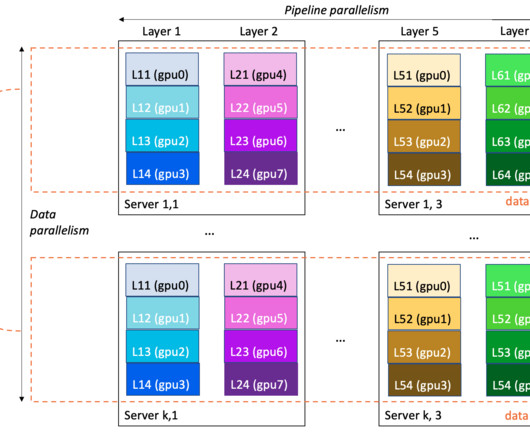
Large language models (LLMs) are neural network-based language models with hundreds of millions ( BERT ) to over a trillion parameters ( MiCS ), and whose size makes single-GPU training impractical. The size of an LLM and its training data is a double-edged sword: it brings modeling quality, but entails infrastructure challenges.
Today, a lot of customers are using TensorFlow to train deep learning models for their clickthrough rate in advertising and personalization recommendations in ecommerce. Model iteration is one of a data scientist’s daily jobs, but they face the problem of taking too long to train on large datasets. Automatic mixed precision training.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. API Gateway is serverless and hence automatically scales with traffic. API Gateway also provides a WebSocket API. Incoming requests to the gateway go through this point.
In this post, we seek to address this growing need by offering clear, actionable guidelines and bestpractices on when to use each approach, helping you make informed decisions that align with your unique requirements and objectives. Optimized for cost-effective performance, they are trained on data in over 200 languages.
Customers can use the SageMaker Studio UI or APIs to specify the SageMaker Model Registry model to be shared and grant access to specific AWS accounts or to everyone in the organization. It also helps achieve data, project, and team isolation while supporting software development lifecycle bestpractices.
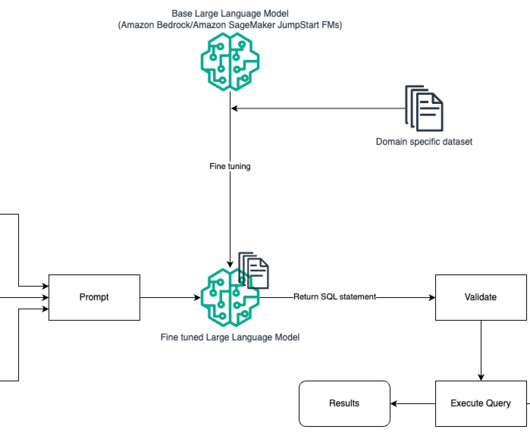
In this post, we provide an introduction to text to SQL (Text2SQL) and explore use cases, challenges, design patterns, and bestpractices. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) via a single API, enabling to easily build and scale Gen AI applications.
Contrast that with Scope 4/5 applications, where not only do you build and secure the generative AI application yourself, but you are also responsible for fine-tuning and training the underlying large language model (LLM). These steps might involve both the use of an LLM and external data sources and APIs.
Because these bestpractices might not be appropriate or sufficient for your environment, use them as helpful considerations rather than prescriptions. Applications must have valid credentials to sign API requests to AWS services. The customer data is cleaned up for both complete and failure cases.
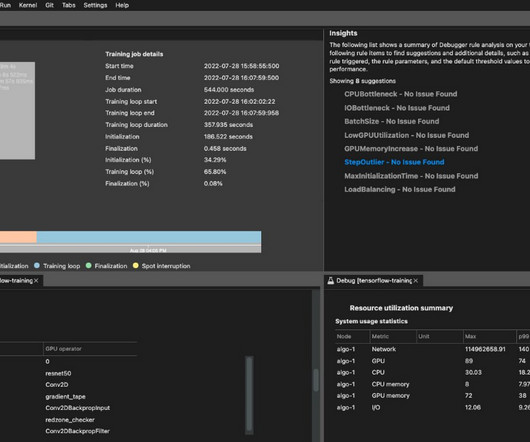
Similarly, maintaining detailed information about the datasets used for training and evaluation helps identify potential biases and limitations in the models knowledge base. It functions as a standalone HTTP server that provides various REST API endpoints for monitoring, recording, and visualizing experiment runs.
GraphStorm is a low-code enterprise graph machine learning (GML) framework to build, train, and deploy graph ML solutions on complex enterprise-scale graphs in days instead of months. allows you to define multiple training targets on different nodes and edges within a single training loop. Specifically, GraphStorm 0.3
Building large language models (LLMs) from scratch or customizing pre-trained models requires substantial compute resources, expert data scientists, and months of engineering work. Launched in 2017, Amazon SageMaker is a fully managed service that makes it straightforward to build, train, and deploy ML models.
Discover how the fully managed infrastructure of SageMaker enables high-performance, low cost ML throughout the ML lifecycle, from building and training to deploying and managing models at scale. Fourth, we’ll address responsible AI, so you can build generative AI applications with responsible and transparent practices.
This article outlines 10 CPQ bestpractices to help optimize your performance, eliminate inefficiencies, and maximize ROI. Use APIs and middleware to bridge gaps between CPQ and existing enterprise systems, ensuring smooth data flow. Equip sales managers with analytics training to track quote performance and refine strategies.
For more information, see Redacting PII entities with asynchronous jobs (API). The query is then forwarded using a REST API call to an Amazon API Gateway endpoint along with the access tokens in the header. The user query is sent using an API call along with the authentication token through Amazon API Gateway.
invoke(inputs["query"])) ) return retrieval_chain Option 2: Access the underlying Boto3 API The Boto3 API is able to directly retrieve with a dynamic retrieval_config. For Amazon Bedrock: Use IAM roles and policies to control access to Bedrock resources and APIs.
In this post, we discuss how to use the Custom Moderation feature in Amazon Rekognition to enhance the accuracy of your pre-trained content moderation API. You can train a custom adapter with as few as 20 annotated images in less than 1 hour. Create a project A project is a container to store your adapters.
SageMaker Pipelines offers ML application developers the ability to orchestrate different steps of the ML workflow, including data loading, data transformation, training, tuning, and deployment. In this post, we provide some bestpractices to maximize the value of SageMaker Pipelines and make the development experience seamless.
Recent advances in generative AI have led to the rapid evolution of natural language to SQL (NL2SQL) technology, which uses pre-trained large language models (LLMs) and natural language to generate database queries in the moment.
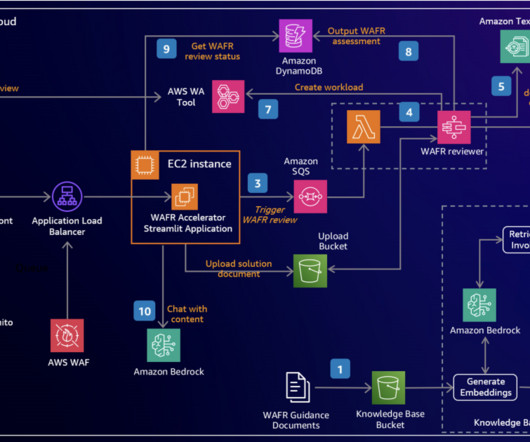
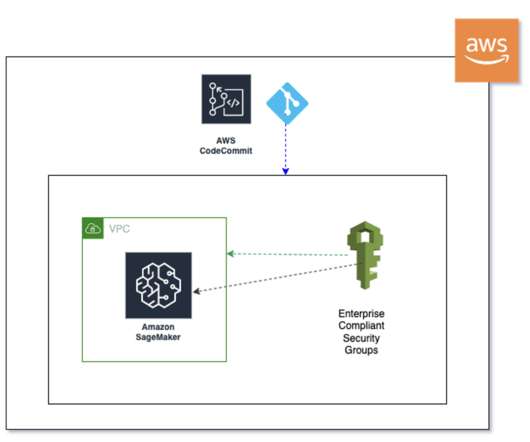
Building cloud infrastructure based on proven bestpractices promotes security, reliability and cost efficiency. We demonstrate how to harness the power of LLMs to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on AWS Well-Architected bestpractices.
Fine-tuning is a powerful approach in natural language processing (NLP) and generative AI , allowing businesses to tailor pre-trained large language models (LLMs) for specific tasks. In this post, we explore the bestpractices and lessons learned for fine-tuning Anthropic’s Claude 3 Haiku on Amazon Bedrock.
Amazon Bedrock , a fully managed service offering high-performing foundation models from leading AI companies through a single API, has recently introduced two significant evaluation capabilities: LLM-as-a-judge under Amazon Bedrock Model Evaluation and RAG evaluation for Amazon Bedrock Knowledge Bases. keys()) & set(metrics2.keys())
As large language models (LLMs) increasingly integrate more multimedia capabilities, human feedback becomes even more critical in training them to generate rich, multi-modal content that aligns with human quality standards. The path to creating effective AI models for audio and video generation presents several distinct challenges.
With SageMaker, data scientists and developers can quickly and easily build and train ML models, and then directly deploy them into a production-ready hosted environment. This post describes the bestpractices for load testing a SageMaker endpoint to find the right configuration for the number of instances and size.
In this post, we will continue to build on top of the previous solution to demonstrate how to build a private API Gateway via Amazon API Gateway as a proxy interface to generate and access Amazon SageMaker presigned URLs. The user invokes createStudioPresignedUrl API on API Gateway along with a token in the header.
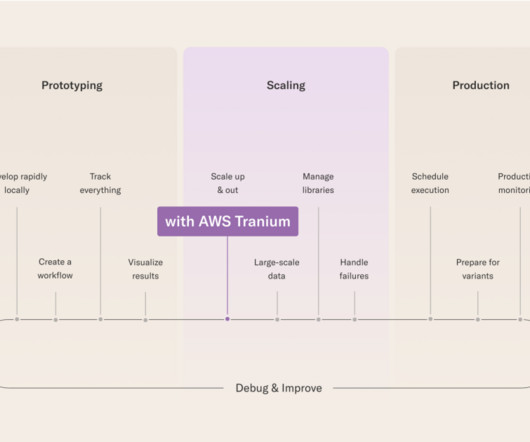
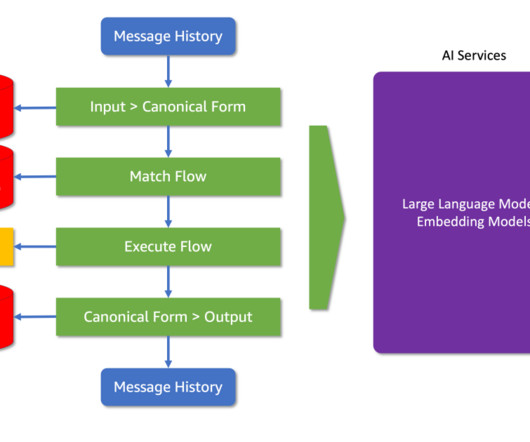
This often means the method of using a third-party LLM API won’t do for security, control, and scale reasons. First, the AWS Trainium accelerator provides a high-performance, cost-effective, and readily available solution for training and fine-tuning large models. The following figure illustrates this workflow.
In addition, we discuss the benefits of Custom Queries and share bestpractices for effectively using this feature. Refer to BestPractices for Queries to draft queries applicable to your use case. Within hours, you can annotate your sample documents using the AWS Management Console and train an adapter.
In this post, we focus on SageMaker training jobs. With SageMaker training jobs, you can bring your own algorithm or choose from more than 25 built-in algorithms. The cost of a training job is based on the resources you use (instances and storage) for the duration (in seconds) that those instances are running.
Because this is an emerging area, bestpractices, practical guidance, and design patterns are difficult to find in an easily consumable basis. This integration makes sure enterprises can take advantage of the full power of generative AI while adhering to bestpractices in operational excellence.
In this post, we provide an overview of the Meta Llama 3 models available on AWS at the time of writing, and share bestpractices on developing Text-to-SQL use cases using Meta Llama 3 models. Training involved a dataset of over 15 trillion tokens across two GPU clusters, significantly more than Meta Llama 2.
This text-to-video API generates high-quality, realistic videos quickly from text and images. Trained on the Amazon SageMaker HyperPod , Dream Machine excels in creating consistent characters, smooth motion, and dynamic camera movements. Luma AI’s recently launched Dream Machine represents a significant advancement in this field.
Training an LLM to Know and Write Standing up an LLM-powered chatbot requires training, tuning, testing, and validating the LLM’s knowledge and guidance. Like agents, the LLM must have visibility into system outage statuses and training on the latest agent guidance or bestpractices.
Large language models Large language models (LLMs) are large-scale ML models that contain billions of parameters and are pre-trained on vast amounts of data. Furthermore, the data that the model was trained on might be out of date, which leads to providing inaccurate responses.
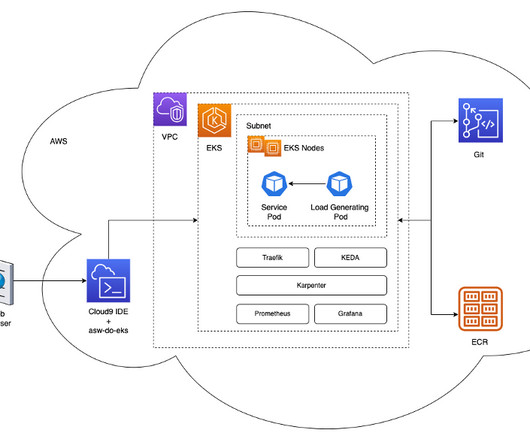
In this post, we focus on how we used Karpenter on Amazon Elastic Kubernetes Service (Amazon EKS) to scale AI training and inference, which are core elements of the Iambic discovery platform. We wanted to build a scalable system to support AI training and inference. per training task 20 minutes average $0.38
Look for a service that has: Encrypted data storage Secure call recording Staff trained in handling PHI (Protected Health Information) Internal audits and compliance reporting 3. Trained Medical Receptionists and Agents Your patients should be speaking with knowledgeable and compassionate representatives.
Agents for Bedrock are a game changer, allowing LLMs to complete complex tasks based on your own data and APIs, privately, securely, with setup in minutes (no training or fine tuning required). Amazon Bedrock is the first fully managed generative AI service to offer Llama 2, Meta’s next-generation LLM, through a managed API.
When you use bestpractices in sales planning, everyone involved benefits — marketing teams, sales managers, sales teams, and your customers. Bestpractices for sales planning begins with an overall comprehensive plan that serves as your roadmap for sales call planning. BestPractices to Improve Sales Planning .
In this post, we dive into how organizations can use Amazon SageMaker AI , a fully managed service that allows you to build, train, and deploy ML models at scale, and can build AI agents using CrewAI, a popular agentic framework and open source models like DeepSeek-R1.
The GenASL web app invokes the backend services by sending the S3 object key in the payload to an API hosted on Amazon API Gateway. API Gateway instantiates an AWS Step Functions The state machine orchestrates the AI/ML services Amazon Transcribe and Amazon Bedrock and the NoSQL data store Amazon DynamoDB using AWS Lambda functions.
Some links for security bestpractices are shared below but we strongly recommend reaching out to your account team for detailed guidance and to discuss the appropriate security architecture needed for a secure and compliant deployment. model API exposed by SageMaker JumpStart properly. How do I train my cat?"
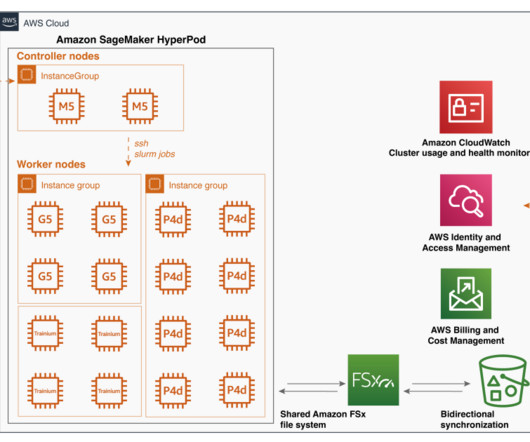
With the increasing use of artificial intelligence (AI) and machine learning (ML) for a vast majority of industries (ranging from healthcare to insurance, from manufacturing to marketing), the primary focus shifts to efficiency when building and training models at scale. The following diagram illustrates the solution architecture.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























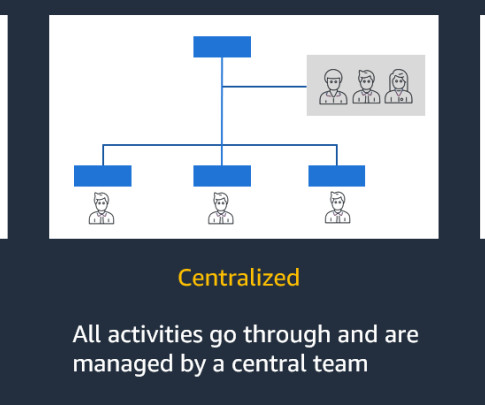














Let's personalize your content