This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The solution integrates large language models (LLMs) with your organization’s data and provides an intelligent chat assistant that understands conversation context and provides relevant, interactive responses directly within the Google Chat interface. The following figure illustrates the high-level design of the solution.
While these models are trained on vast amounts of generic data, they often lack the organization-specific context and up-to-date information needed for accurate responses in business settings. The function checks the semantic cache (Amazon Bedrock Knowledge Bases) using the Retrieve API. which is received by the Invoke Agent function.
During these live events, F1 IT engineers must triage critical issues across its services, such as network degradation to one of its APIs. This impacts downstream services that consume data from the API, including products such as F1 TV, which offer live and on-demand coverage of every race as well as real-time telemetry.
In this post, we will continue to build on top of the previous solution to demonstrate how to build a private API Gateway via Amazon API Gateway as a proxy interface to generate and access Amazon SageMaker presigned URLs. The user invokes createStudioPresignedUrl API on API Gateway along with a token in the header.
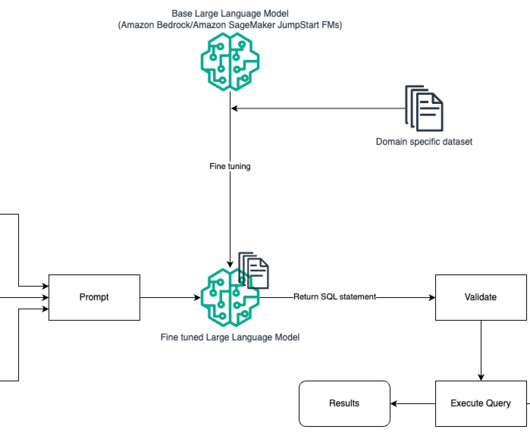
One such area that is evolving is using natural language processing (NLP) to unlock new opportunities for accessing data through intuitive SQL queries. Instead of dealing with complex technical code, business users and data analysts can ask questions related to data and insights in plain language.
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machine learning (ML) models. Amazon SageMaker notebook jobs allow data scientists to run their notebooks on demand or on a schedule with a few clicks in SageMaker Studio.
In this post, we show how to configure a new OAuth-based authentication feature for using Snowflake in Amazon SageMaker Data Wrangler. Snowflake is a cloud data platform that provides data solutions for data warehousing to data science. For more information about prerequisites, see Get Started with Data Wrangler.
It allows developers to build and scale generative AI applications using FMs through an API, without managing infrastructure. Customers are building innovative generative AI applications using Amazon Bedrock APIs using their own proprietary data.
These customers need to balance governance, security, and compliance against the need for machine learning (ML) teams to quickly access their data science environments in a secure manner. The workflow steps are as follows: The user authenticates with the Amazon Cognito user pool and receives a token to consume the Studio access API.
However, these models require massive amounts of clean, structured training data to reach their full potential. Most real-world data exists in unstructured formats like PDFs, which requires preprocessing before it can be used effectively. According to IDC , unstructured data accounts for over 80% of all business data today.
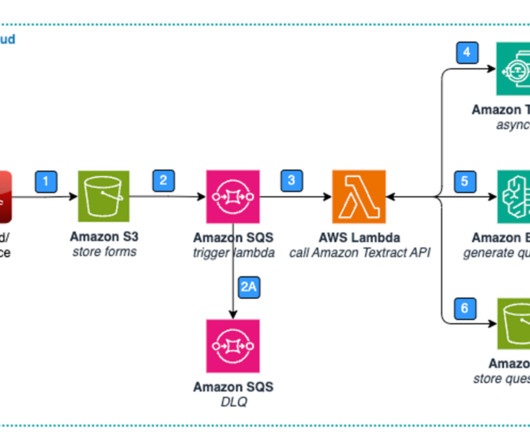
Generative artificial intelligence (AI) provides an opportunity for improvements in healthcare by combining and analyzing structured and unstructured data across previously disconnected silos. Figure 1: Architecture – Standard Form – Data Extraction & Storage.
Twilio enables companies to use communications and data to add intelligence and security to every step of the customer journey, from sales and marketing to growth, customer service, and many more engagement use cases in a flexible, programmatic way. Data is the foundational layer for all generative AI and ML applications.
Harnessing the power of bigdata has become increasingly critical for businesses looking to gain a competitive edge. However, managing the complex infrastructure required for bigdata workloads has traditionally been a significant challenge, often requiring specialized expertise.
With the use of cloud computing, bigdata and machine learning (ML) tools like Amazon Athena or Amazon SageMaker have become available and useable by anyone without much effort in creation and maintenance. This dilemma hampers the creation of efficient models that use data to generate business-relevant insights.
However, as a new product in a new space for Amazon, Amp needed more relevant data to inform their decision-making process. Part 1 shows how data was collected and processed using the data and analytics platform, and Part 2 shows how the data was used to create show recommendations using Amazon SageMaker , a fully managed ML service.
However, scaling up generative AI and making adoption easier for different lines of businesses (LOBs) comes with challenges around making sure data privacy and security, legal, compliance, and operational complexities are governed on an organizational level. In this post, we discuss how to address these challenges holistically.
Affinities are computed either implicitly from the user’s behavioral data or explicitly from topics of interest (such as pop music, baseball, or politics) as provided in their user profiles. This is Part 2 of a series on using data analytics and ML for Amp and creating a personalized show recommendation list platform.
Knowledge Bases for Amazon Bedrock automates synchronization of your data with your vector store, including diffing the data when it’s updated, document loading, and chunking, as well as semantic embedding. RAG is a popular technique that combines the use of private data with large language models (LLMs).
Data-driven decisions are essential in businesses to diminish the chances of errors, and online data analyst courses will teach you how to interpret data precisely. There is where data analysis comes in, you can use the data your company has, and key performance indicators (KPIs) to indicate what path you should follow.
The Slack application sends the event to Amazon API Gateway , which is used in the event subscription. API Gateway forwards the event to an AWS Lambda function. About the Authors Rushabh Lokhande is a Senior Data & ML Engineer with AWS Professional Services Analytics Practice.
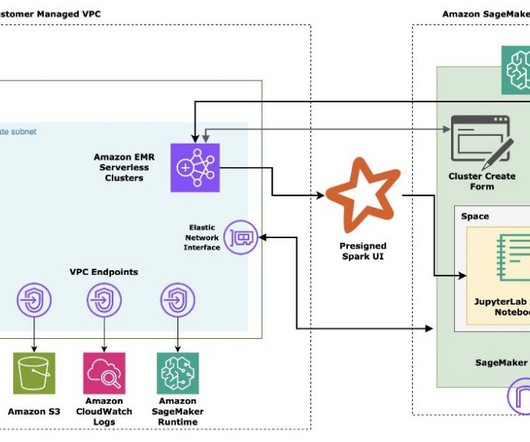
This presents an undesired threat vector for exfiltration and gaining access to customer data when proper access controls are not enforced. Studio supports a few methods for enforcing access controls against presigned URL data exfiltration: Client IP validation using the IAM policy condition aws:sourceIp. Solution overview.
You can now use cross-account support for Amazon SageMaker Pipelines to share pipeline entities across AWS accounts and access shared pipelines directly through Amazon SageMaker API calls. To further monitor those workflows, data scientists now require cross-account read-only permission to the deployed pipeline in the test account.
Generative AI models have the potential to revolutionize enterprise operations, but businesses must carefully consider how to harness their power while overcoming challenges such as safeguarding data and ensuring the quality of AI-generated content. Vector data is a type of data that represents a point in a high-dimensional space.
Amazon Q can help you get fast, relevant answers to pressing questions, solve problems, generate content, and take actions using the data and expertise found in your company’s information repositories and enterprise systems. Amazon Q uses the chat_sync API to carry out the conversation.
Join leading smart home service provider Vivint’s Ben Austin and Jacob Miller for an enlightening session on how they have designed and utilized automated speech analytics to extract KPI targeted scores and route those critical insights through an API to their own customized dashboard to track and coach on agent scoring/behaviors.
We also look into how to further use the extracted structured information from claims data to get insights using AWS Analytics and visualization services. We highlight on how extracted structured data from IDP can help against fraudulent claims using AWS Analytics services. Part 2: Data enrichment and insights. Prerequisites.
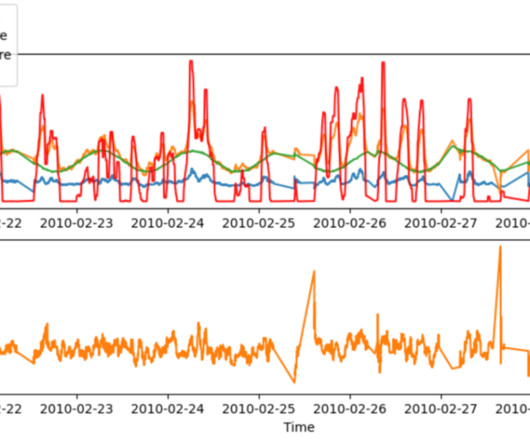
Homomorphic encryption is a new approach to encryption that allows computations and analytical functions to be run on encrypted data, without first having to decrypt it, in order to preserve privacy in cases where you have a policy that states data should never be decrypted. The following figure shows both versions of these patterns.
Make sure to validate prompt input data and prompt input size for allocated character limits that are defined by your model. If you’re performing prompt engineering, you should persist your prompts to a reliable data store. In the batch case, there are a couple challenges compared to typical data pipelines.
The underlying technologies of composability include some combination of artificial intelligence (AI), machine learning, automation, container-based architecture, bigdata, analytics, low-code and no-code development, Agile/DevOps deployment, cloud delivery, and applications with open APIs (microservices).
In this post, we address these limitations by implementing the access control outside of the MLflow server and offloading authentication and authorization tasks to Amazon API Gateway , where we implement fine-grained access control mechanisms at the resource level using Identity and Access Management (IAM). Adds an IAM authorizer.
We explore two ways of obtaining the same result: via JumpStart’s graphical interface on Amazon SageMaker Studio , and programmatically through JumpStart APIs. If you want to jump straight into the JumpStart API code we go through in this post, you can refer to the following sample Jupyter notebook: Introduction to JumpStart – Text to Image.
Amazon Bedrock Agents enable generative AI applications to perform multistep tasks across various company systems and data sources. Agents automatically call the necessary APIs to interact with the company systems and processes to fulfill the request. Claims API Gateway runs the Custom Authorizer to validate the access token.
The post Domain-adaptation Fine-tuning of Foundation Models in Amazon SageMaker JumpStart on Financial data describes how to fine-tune an LLM using your own dataset. When that job is done, you can invoke an API that summarizes the text or answers questions about it. text.strip().replace('n',
Tweet Managing your API’s has become a very complicated endeavor. If your role to is manage API’s it’s important to figure out how to automate that process. Today 3scale and Pivotal ® announced that the 3scale self-serve API management solution is available through the Pivotal Web Services (PWS) platform.
Max Goff is a data scientist/data engineer with over 30 years of software development experience. Yaoqi Zhang is a Senior BigData Engineer at Mission Cloud. Adrian Martin is a BigData/Machine Learning Lead Engineer at Mission Cloud. She received her Ph.D. Marco Mercado is a Sr. After earning his Ph.D.
Open APIs: An open API model is advantageous in that it allows developers outside of companies to easily access and use APIs to create breakthrough innovations. At the same time, however, publicly available APIs are also exposed ones. billion GB of data were being produced every day in 2012 alone!)
From understanding the fundamentals of call center predictive analytics to diving into real-world call center analytics use cases, this comprehensive guide covers everything you need to know about analyzing call center data. Predictive Analytics: Uses historical data to forecast future events like call volumes or customer churn.
Today, companies are establishing feature stores to provide a central repository to scale ML development across business units and data science teams. The offline store is an append-only store and can be used to store and access historical feature data. Table formats provide a way to abstract data files as a table.
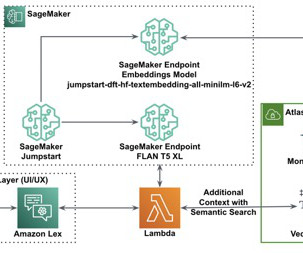
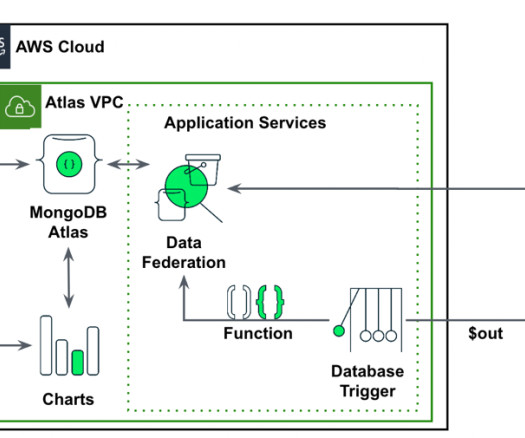
By harnessing the transformative potential of MongoDB’s native time series data capabilities and integrating it with the power of Amazon SageMaker Canvas , organizations can overcome these challenges and unlock new levels of agility. Solution overview Users persist their transactional time series data in MongoDB Atlas.
We explore two ways of obtaining the same result: via JumpStart’s graphical interface on Amazon SageMaker Studio , and programmatically through JumpStart APIs. The following sections provide a step-by-step demo to perform inference, both via the Studio UI and via JumpStart APIs. JumpStart overview. Solution overview.
With Amazon Forecast , and support from the AWS ProServe team and AWS Machine Learning Solutions Lab , our customer—with limited internal data scientists—now has state-of-the-art forecasting capabilities. To train a predictor, training data is ingested into data storage from a data source, using one of the formats supported by Forecast.
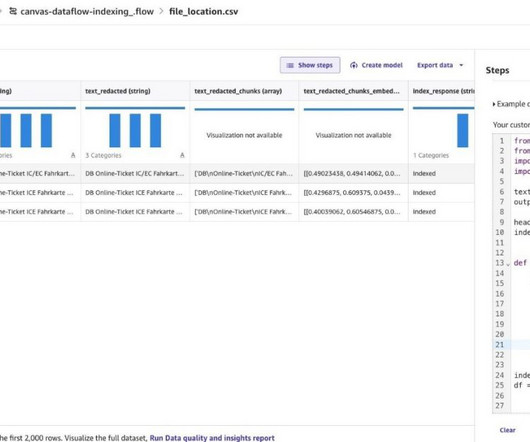
Solution overview SageMaker Canvas brings together a broad set of capabilities to help data professionals prepare, build, train, and deploy ML models without writing any code. SageMaker Data Wrangler has also been integrated into SageMaker Canvas, reducing the time it takes to import, prepare, transform, featurize, and analyze data.
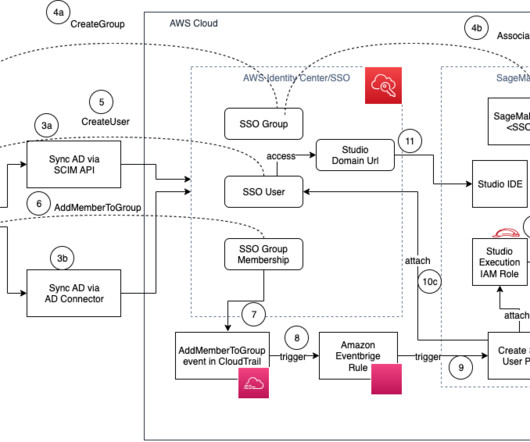
One of the most common real-world challenges in setting up user access for Studio is how to manage multiple users, groups, and data science teams for data access and resource isolation. The solution also uses SAML attribute mapping to populate the SAML assertion with specific access-relevant data, such as user ID and user team.
Sync your AD users and groups and memberships to AWS Identity Center: If you’re using an identity provider (IdP) that supports SCIM, use the SCIM API integration with IAM Identity Center. When the AD user is assigned to an AD group, an IAM Identity Center API ( CreateGroupMembership ) is invoked, and SSO group membership is created.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content