This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
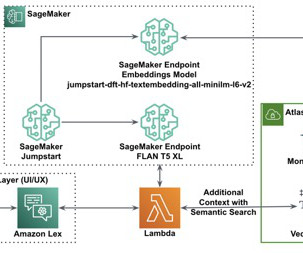
Generative AI models have the potential to revolutionize enterprise operations, but businesses must carefully consider how to harness their power while overcoming challenges such as safeguarding data and ensuring the quality of AI-generated content. It uses the Vector Search index and performs a semantic search on the vector data store.
Before you get started, refer to Part 1 for a high-level overview of the insurance use case with IDP and details about the data capture and classification stages. In Part 1, we saw how to use Amazon Textract APIs to extract information like forms and tables from documents, and how to analyze invoices and identity documents.
Agents automatically call the necessary APIs to interact with the company systems and processes to fulfill the request. The App calls the Claims API Gateway API to run the claims proxy passing user requests and tokens. Claims API Gateway runs the Custom Authorizer to validate the access token.
In this post, we address these limitations by implementing the access control outside of the MLflow server and offloading authentication and authorization tasks to Amazon API Gateway , where we implement fine-grained access control mechanisms at the resource level using Identity and Access Management (IAM). Adds an IAM authorizer.
When the message is received by the SQS queue, it triggers the AWS Lambda function to make an API call to the Amp catalog service. The Lambda function retrieves the desired show metadata, filters the metadata, and then sends the output metadata to Amazon Kinesis Data Streams. Data Engineer for Amp on Amazon.
To implement ML pipelines, data scientists (or ML engineers) use SageMaker Pipelines. A SageMaker pipeline is a series of interconnected steps (SageMaker processing jobs, training, HPO) that is defined by a JSON pipeline definition using a Python SDK. This pipeline definition encodes a pipeline using a Directed Acyclic Graph (DAG).
Although they still own the two largest shares of this fragmented market, there’s a definite trend toward more open providers – particularly those that were born in the cloud (like Toast or Upserve ). A big point of discussion during breakout sessions and over drinks (yes, really!)
In terms of resulting speedups, the approximate order is programming hardware, then programming against PBA APIs, then programming in an unmanaged language such as C++, then a managed language such as Python. SIMD describes computers with multiple processing elements that perform the same operation on multiple data points simultaneously.
One of the main drivers for new innovations and applications in ML is the availability and amount of data along with cheaper compute options. Although you can configure a local data path for many of the local pipeline steps, Amazon S3 is the default location to store the data output by the transformation.
What is Customer Data? Customer data is the information that companies collect every time customers interact with them–both online and offline. It gives you a more definite customer profile, lets you know the customer’s behavior, and gives you an in-depth look into the customer journey. Tealium AudienceStream CDP.
Organizational resiliency draws on and extends the definition of resiliency in the AWS Well-Architected Framework to include and prepare for the ability of an organization to recover from disruptions. Ram Vittal is a Principal ML Solutions Architect at AWS.
They provide access to external data and APIs or enable specific actions and computation. To improve accuracy, we tested model fine-tuning, training the model on common queries and context (such as database schemas and their definitions). Before joining RDC, he served as a Lead Data Scientist at KPMG, advising clients globally.
Moreover, it provides a straightforward way to track data lineage, so we can foresee which datasets will be affected by newly introduced changes. The following figure shows schema definition and model which reference it. Environment variables : Set environment variables, such as model paths, API keys, and other necessary parameters.
He enjoys supporting customers in their digital transformation journey, using bigdata, machine learning, and generative AI to help solve their business challenges. Prerequisites As a prerequisite, you need to enable model access in Amazon Bedrock and have access to a Linux or macOS development environment.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content