This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. The following figure illustrates the high-level design of the solution.
Harnessing the power of bigdata has become increasingly critical for businesses looking to gain a competitive edge. However, managing the complex infrastructure required for bigdata workloads has traditionally been a significant challenge, often requiring specialized expertise. latest USER root RUN dnf install python3.11
During these live events, F1 IT engineers must triage critical issues across its services, such as network degradation to one of its APIs. This impacts downstream services that consume data from the API, including products such as F1 TV, which offer live and on-demand coverage of every race as well as real-time telemetry.
Solution overview Our solution implements a verified semantic cache using the Amazon Bedrock Knowledge Bases Retrieve API to reduce hallucinations in LLM responses while simultaneously improving latency and reducing costs. The function checks the semantic cache (Amazon Bedrock Knowledge Bases) using the Retrieve API.
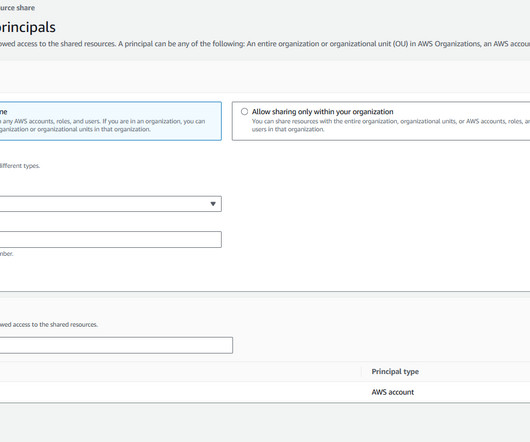
Customers can use the SageMaker Studio UI or APIs to specify the SageMaker Model Registry model to be shared and grant access to specific AWS accounts or to everyone in the organization. We will start by using the SageMaker Studio UI and then by using APIs. These stages are applicable to both use case and model stages.
In Part 1 of this series, we discussed intelligent document processing (IDP), and how IDP can accelerate claims processing use cases in the insurance industry. We discussed how we can use AWS AI services to accurately categorize claims documents along with supporting documents. Part 1: Classification and extraction of documents.
Amazon’s intelligent document processing (IDP) helps you speed up your business decision cycles and reduce costs. Across multiple industries, customers need to process millions of documents per year in the course of their business. The following figure shows the stages that are typically part of an IDP workflow.
The healthcare industry generates and collects a significant amount of unstructured textual data, including clinical documentation such as patient information, medical history, and test results, as well as non-clinical documentation like administrative records. Lastly, the Lambda function stores the question list in Amazon S3.
Amazon SageMaker notebook jobs allow data scientists to run their notebooks on demand or on a schedule with a few clicks in SageMaker Studio. With this launch, you can programmatically run notebooks as jobs using APIs provided by Amazon SageMaker Pipelines , the ML workflow orchestration feature of Amazon SageMaker.
Knowledge Bases for Amazon Bedrock automates synchronization of your data with your vector store, including diffing the data when it’s updated, document loading, and chunking, as well as semantic embedding. RAG is a popular technique that combines the use of private data with large language models (LLMs).
Imagine the possibilities: Quick and efficient brainstorming sessions, real-time ideation, and even drafting documents or code snippets—all powered by the latest advancements in AI. The Slack application sends the event to Amazon API Gateway , which is used in the event subscription.
Generative AI models have the potential to revolutionize enterprise operations, but businesses must carefully consider how to harness their power while overcoming challenges such as safeguarding data and ensuring the quality of AI-generated content. As a Data Engineer he was involved in applying AI/ML to fraud detection and office automation.
This solution uses an Amazon Cognito user pool as an OAuth-compatible identity provider (IdP), which is required in order to exchange a token with AWS IAM Identity Center and later on interact with the Amazon Q Business APIs. Amazon Q uses the chat_sync API to carry out the conversation.
Open APIs: An open API model is advantageous in that it allows developers outside of companies to easily access and use APIs to create breakthrough innovations. At the same time, however, publicly available APIs are also exposed ones. billion GB of data were being produced every day in 2012 alone!)
Access and permissions to configure IDP to register Data Wrangler application and set up the authorization server or API. For data scientist: An S3 bucket that Data Wrangler can use to output transformed data. Select the configuration that starts the process of registering Data Wrangler as an application.
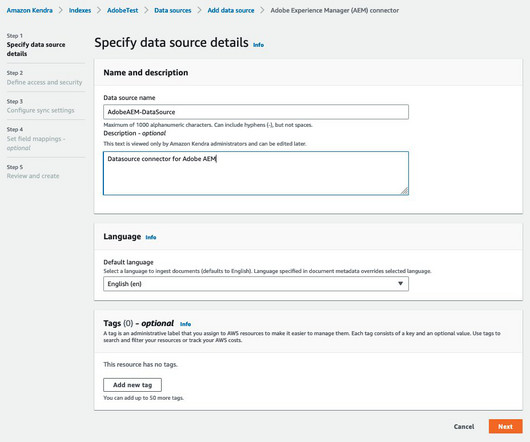
The connector also ingests the access control list (ACL) information for each document. Solution overview In our solution, we configure AEM as a data source for an Amazon Kendra search index using the Amazon Kendra AEM connector. The connector also indexes the Access Control List (ACL) information for each message and document.
Most real-world data exists in unstructured formats like PDFs, which requires preprocessing before it can be used effectively. According to IDC , unstructured data accounts for over 80% of all business data today. This includes formats like emails, PDFs, scanned documents, images, audio, video, and more.
This pipeline could be a batch pipeline if you prepare contextual data in advance, or a low-latency pipeline if you’re incorporating new contextual data on the fly. In the batch case, there are a couple challenges compared to typical data pipelines. He entered the bigdata space in 2013 and continues to explore that area.
SageMaker Feature Store automatically builds an AWS Glue Data Catalog during feature group creation. Customers can also access offline store data using a Spark runtime and perform bigdata processing for ML feature analysis and feature engineering use cases. Table formats provide a way to abstract data files as a table.
In this post, we explore how companies can improve visibility into their models with centralized dashboards and detailed documentation of their models using two new features: SageMaker Model Cards and the SageMaker Model Dashboard. Both these features are available at no additional charge to SageMaker customers.
Applications and services can call the deployed endpoint directly or through a deployed serverless Amazon API Gateway architecture. To learn more about real-time endpoint architectural best practices, refer to Creating a machine learning-powered REST API with Amazon API Gateway mapping templates and Amazon SageMaker.
Large language models (LLMs) can be used to analyze complex documents and provide summaries and answers to questions. The post Domain-adaptation Fine-tuning of Foundation Models in Amazon SageMaker JumpStart on Financial data describes how to fine-tune an LLM using your own dataset.
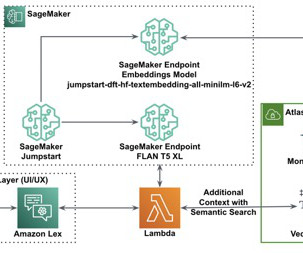
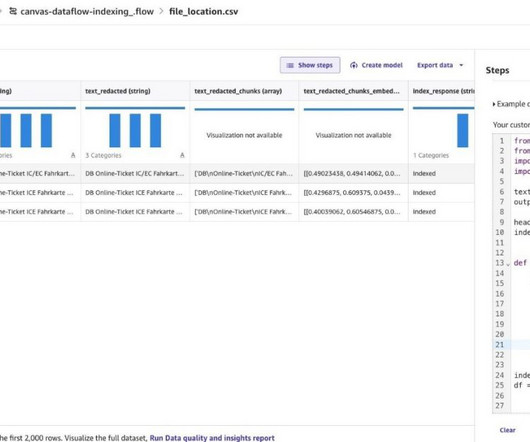
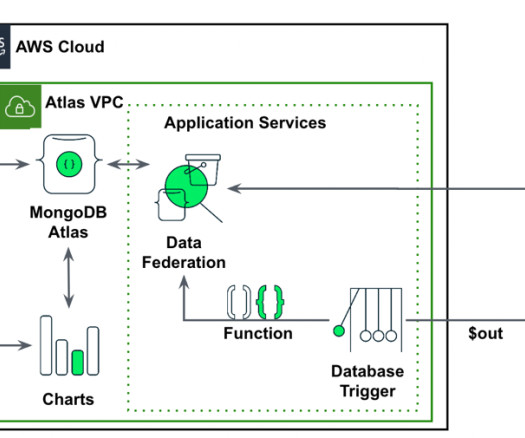
In this post, we will explore the potential of using MongoDB’s time series data and SageMaker Canvas as a comprehensive solution. MongoDB Atlas MongoDB Atlas is a fully managed developer data platform that simplifies the deployment and scaling of MongoDB databases in the cloud.
One of the tools available as part of the ML governance is Amazon SageMaker Model Cards , which has the capability to create a single source of truth for model information by centralizing and standardizing documentation throughout the model lifecycle. They provide a fact sheet of the model that is important for model governance.
Amazon SageMaker is a fully managed service that provides developers and data scientists the ability to build, train, and deploy machine learning (ML) models quickly. The SageMaker Python SDK provides open-source APIs and containers to train and deploy models on SageMaker, using several different ML and deep learning frameworks.
In this post, we address these limitations by implementing the access control outside of the MLflow server and offloading authentication and authorization tasks to Amazon API Gateway , where we implement fine-grained access control mechanisms at the resource level using Identity and Access Management (IAM). Adds an IAM authorizer.
Amazon Kendra supports a variety of document formats , such as Microsoft Word, PDF, and text from various data sources. In this post, we focus on extending the document support in Amazon Kendra to make images searchable by their displayed content. This means you can manipulate and ingest your data as needed.
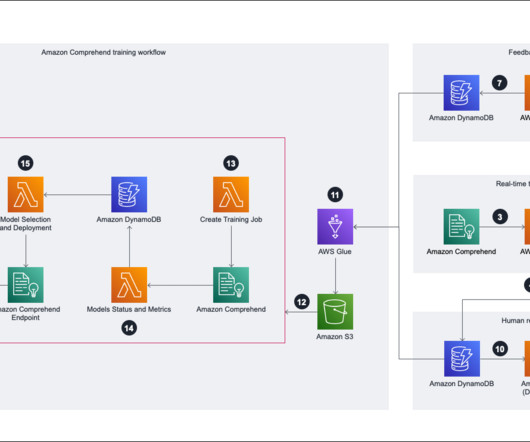
Amazon Comprehend is a fully managed and continuously trained natural language processing (NLP) service that can extract insight about the content of a document or text. The steps are as follows: The client side calls Amazon API Gateway as the entry point to provide a client message as input. API Gateway bypasses the request to Lambda.
The solution also uses SAML attribute mapping to populate the SAML assertion with specific access-relevant data, such as user ID and user team. Because the solution creates a SAML API, you can use any IdP supporting SAML assertions to create this architecture. The API Gateway calls an SAML backend API. Custom SAML 2.0
Synchronous translation has limits on the document size it can translate; as of this writing, it’s set to 5,000 bytes. For larger document sizes, consider using an asynchronous route of creating the job using start_text_translation_job and checking the status via describe_text_translation_job.
This example notebook demonstrates the pattern of using Feature Store as a central repository from which data scientists can extract training datasets. In addition to creating a training dataset, we use the PutRecord API to put the 1-week feature aggregations into the online feature store nightly. Nov-01,22:01:00 1 74.99 …9843 99.50
” How about full endpoint documentation for all our products. An API (Application Programming Interface) will enhance your utilisation of our platform. But that’s not all… 2018 is going to be The Year of Data Analysis! Bigdata is here and we have plenty of it.
In the artificial intelligence (AI) space, athenahealth uses data science and machine learning (ML) to accelerate business processes and provide recommendations, predictions, and insights across multiple services. Each project maintained detailed documentation that outlined how each script was used to build the final model.
For detailed instructions on how to use the DGL-KE, refer to Training knowledge graph embeddings at scale with the Deep Graph Library and DGL-KE Documentation. For production, we wanted to invoke the model as a simple API call. Packaging the solution as a scalable workflow. We used SageMaker notebooks to develop and debug our code.
The consistency problem can be avoided by defining all the categories rigorously in a shared document, mentioning each edge case, like the one above, to what category it should belong. Clean data. In general, the more training data you have, the better.
In terms of resulting speedups, the approximate order is programming hardware, then programming against PBA APIs, then programming in an unmanaged language such as C++, then a managed language such as Python. SIMD describes computers with multiple processing elements that perform the same operation on multiple data points simultaneously.
You can also access the trial data via the Python SDK to generate your own visualization using your preferred plotting libraries. To learn more about Experiments APIs and SDKs, we recommend the following documentation: CreateExperiment and Amazon SageMaker Experiments Python SDK.
You can change the existing policies here by selecting the policy and editing the document. This role can also be recreated via Infrastructure as Code (IaC) by simply taking the contents of the policy documents and inserting them into your existing solution. Link the new role to a user.
Despite significant advancements in bigdata and open source tools, niche Contact Center Business Intelligence providers are still wed to their own proprietary tools leaving them saddled with technical debt and an inability to innovate from within. By putting it into the public domain, we invite your feedback and contributions.
One of the tools available as part of the ML governance is Amazon SageMaker Model Cards , which has the capability to create a single source of truth for model information by centralizing and standardizing documentation throughout the model lifecycle. They provide a fact sheet of the model that is important for model governance.
Hoewel ze zijn geëvolueerd van gedrukte naar een meer document-centrisch wereldbeeld, hebben ze de neiging om CCM in de eerste plaats te zien als gestructureerde, uitgaande communicatie die wordt aangedreven door wettelijke normen. Investeringen in CCM worden gedaan door on-premise, gelicentieerde software aan te schaffen.
These offer applications with open APIs provide a new level of customization and integration. even small business is taking advantage of sophisticated analytics to turn data. Personalize the customer experience, make sense of bigdata to turn insights into actionable plans. Continued Emphasis – Self-Serve Documentation.
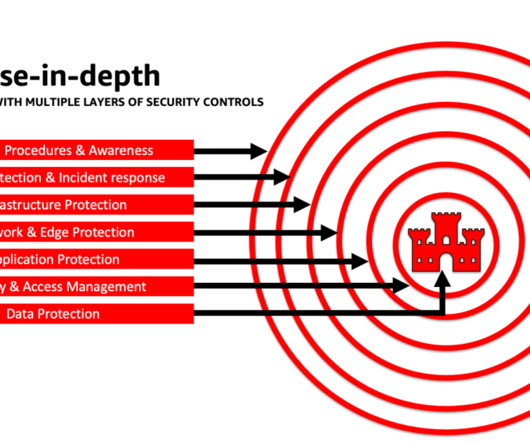
Accelerate your security and AI/ML learning with best practices guidance, training, and certification AWS also curates recommendations from Best Practices for Security, Identity, & Compliance and AWS Security Documentation to help you identify ways to secure your training, development, testing, and operational environments.
Maintain and develop Stratifyd’s API layer and/or analytics pipeline. Design, implement, and document new platform features and associated unit tests. Professional experience working with systems designed to deliver and operate on streaming data in near-real-time, or personal projects related to the same. and Python/C API.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content