This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
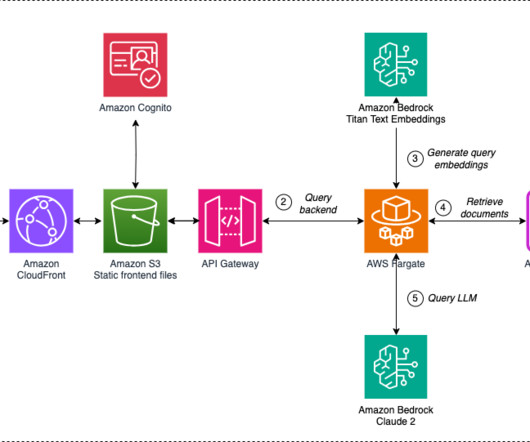
Solution overview Our solution implements a verified semantic cache using the Amazon Bedrock Knowledge Bases Retrieve API to reduce hallucinations in LLM responses while simultaneously improving latency and reducing costs. The function checks the semantic cache (Amazon Bedrock Knowledge Bases) using the Retrieve API.
During these live events, F1 IT engineers must triage critical issues across its services, such as network degradation to one of its APIs. This impacts downstream services that consume data from the API, including products such as F1 TV, which offer live and on-demand coverage of every race as well as real-time telemetry.
Customers can use the SageMaker Studio UI or APIs to specify the SageMaker Model Registry model to be shared and grant access to specific AWS accounts or to everyone in the organization. We will start by using the SageMaker Studio UI and then by using APIs.
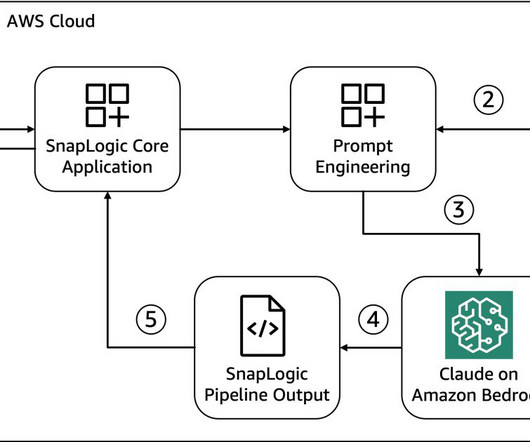
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. Its low-code interface drastically reduces the time needed to develop generative AI applications.
Amazon SageMaker notebook jobs allow data scientists to run their notebooks on demand or on a schedule with a few clicks in SageMaker Studio. With this launch, you can programmatically run notebooks as jobs using APIs provided by Amazon SageMaker Pipelines , the ML workflow orchestration feature of Amazon SageMaker.
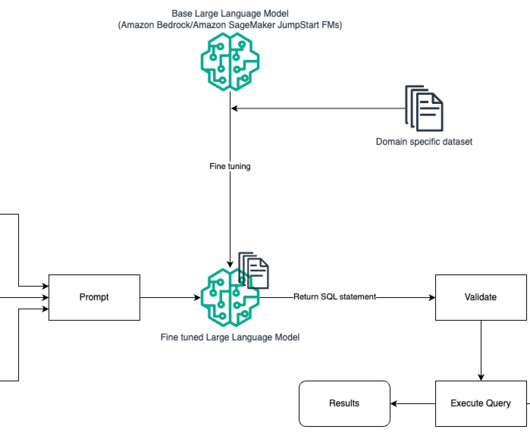
Our initial approach combined prompt engineering and traditional Retrieval Augmented Generation (RAG). They provide access to external data and APIs or enable specific actions and computation. As a former startup CTO, he enjoys collaborating with founders and engineering leaders to drive growth and innovation on AWS.
It allows developers to build and scale generative AI applications using FMs through an API, without managing infrastructure. Customers are building innovative generative AI applications using Amazon Bedrock APIs using their own proprietary data.
Harnessing the power of bigdata has become increasingly critical for businesses looking to gain a competitive edge. However, managing the complex infrastructure required for bigdata workloads has traditionally been a significant challenge, often requiring specialized expertise.
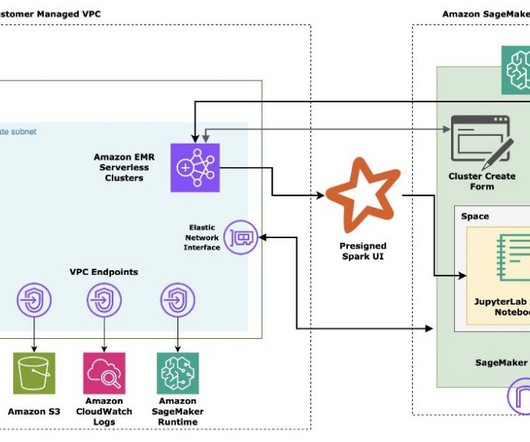
In the post Secure Amazon SageMaker Studio presigned URLs Part 2: Private API with JWT authentication , we demonstrated how to build a private API to generate Amazon SageMaker Studio presigned URLs that are only accessible by an authenticated end-user within the corporate network from a single account.
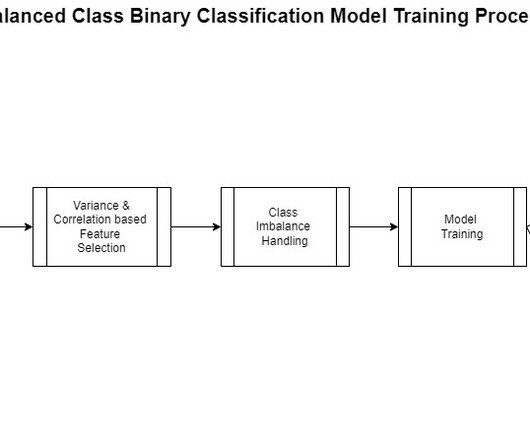
This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process. One aspect of this data preparation is feature engineering. However, generalizing feature engineering is challenging.
Specifically, we discuss the following: Why do we need Text2SQL Key components for Text to SQL Prompt engineering considerations for natural language or Text to SQL Optimizations and best practices Architecture patterns Why do we need Text2SQL? Effective prompt engineering is key to developing natural language to SQL systems.
The backbone of these advancements is ZOE, Zeta’s Optimization Engine. ZOE is a multi-agent LLM application that integrates with multiple data sources to provide a unified view of the customer, simplify analytics queries, and facilitate marketing campaign creation. The main parts we use are tracking the server and model registry.
The Slack application sends the event to Amazon API Gateway , which is used in the event subscription. API Gateway forwards the event to an AWS Lambda function. About the Authors Rushabh Lokhande is a Senior Data & ML Engineer with AWS Professional Services Analytics Practice.
It’s a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like Anthropic, Cohere, Meta, Mistral AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
in Mechanical Engineering from the University of Notre Dame. Max Goff is a data scientist/dataengineer with over 30 years of software development experience. Cloud Engineer specializing in developing cloud native solutions and automation. Yaoqi Zhang is a Senior BigDataEngineer at Mission Cloud.
You can now use cross-account support for Amazon SageMaker Pipelines to share pipeline entities across AWS accounts and access shared pipelines directly through Amazon SageMaker API calls. To further monitor those workflows, data scientists now require cross-account read-only permission to the deployed pipeline in the test account.
There are unique considerations when engineering generative AI workloads through a resilience lens. Make sure to validate prompt input data and prompt input size for allocated character limits that are defined by your model. If you’re performing prompt engineering, you should persist your prompts to a reliable data store.
The Retrieve and RetrieveAndGenerate APIs allow your applications to directly query the index using a unified and standard syntax without having to learn separate APIs for each different vector database, reducing the need to write custom index queries against your vector store.
This emergent ability in LLMs has compelled software developers to use LLMs as an automation and UX enhancement tool that transforms natural language to a domain-specific language (DSL): system instructions, API requests, code artifacts, and more. The JSON artifact is directly integrated to the core SnapLogic integration platform.
Queries are sent to the backend using a REST API defined in Amazon API Gateway , a fully managed service that makes it straightforward for developers to create, publish, maintain, monitor, and secure APIs at any scale, and implemented through an API Gateway private integration.
The underlying technologies of composability include some combination of artificial intelligence (AI), machine learning, automation, container-based architecture, bigdata, analytics, low-code and no-code development, Agile/DevOps deployment, cloud delivery, and applications with open APIs (microservices).
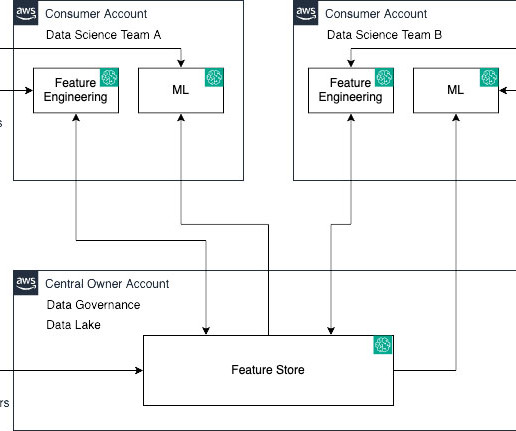
As feature data grows in size and complexity, data scientists need to be able to efficiently query these feature stores to extract datasets for experimentation, model training, and batch scoring. SageMaker Feature Store automatically builds an AWS Glue Data Catalog during feature group creation.
Users typically reach out to the engineering support channel when they have questions about data that is deeply embedded in the data lake or if they can’t access it using various queries. Having an AI assistant can reduce the engineering time spent in responding to these queries and provide answers more quickly.
Let’s demystify this using the following personas and a real-world analogy: Data and ML engineers (owners and producers) – They lay the groundwork by feeding data into the feature store Data scientists (consumers) – They extract and utilize this data to craft their models Dataengineers serve as architects sketching the initial blueprint.
Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics. Access and permissions to configure IDP to register Data Wrangler application and set up the authorization server or API. Configure Snowflake. Configure SageMaker Studio.
Generative AI models have the potential to revolutionize enterprise operations, but businesses must carefully consider how to harness their power while overcoming challenges such as safeguarding data and ensuring the quality of AI-generated content. As a DataEngineer he was involved in applying AI/ML to fraud detection and office automation.
To overcome this, enterprises needs to shape a clear operating model defining how multiple personas, such as data scientists, dataengineers, ML engineers, IT, and business stakeholders, should collaborate and interact; how to separate the concerns, responsibilities, and skills; and how to use AWS services optimally.
Our initial ML model uses 21 batch features computed daily using data captured in the past 2 months. This data includes both playback and app engagement history per user, and grows with the number of users and frequency of app usage. Manolya McCormick is a Sr Software Development Engineer for Amp on Amazon. Real-time inference.
Applications and services can call the deployed endpoint directly or through a deployed serverless Amazon API Gateway architecture. To learn more about real-time endpoint architectural best practices, refer to Creating a machine learning-powered REST API with Amazon API Gateway mapping templates and Amazon SageMaker.
Data is presented to the personas that need access using a unified interface. For example, it can be used to answer questions such as “If patients have a propensity to have their wearables turned off and there is no clinical telemetry data available, can the likelihood that they are hospitalized still be accurately predicted?”
In this post, we address these limitations by implementing the access control outside of the MLflow server and offloading authentication and authorization tasks to Amazon API Gateway , where we implement fine-grained access control mechanisms at the resource level using Identity and Access Management (IAM). Adds an IAM authorizer.
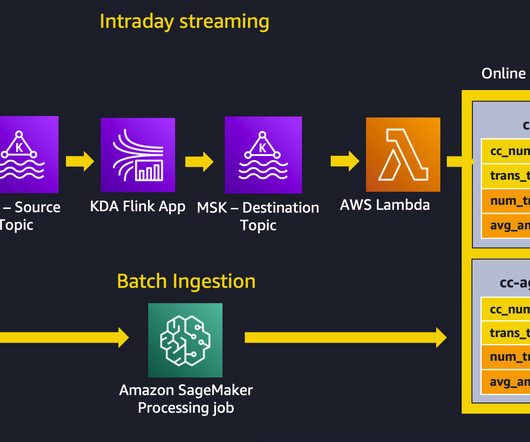
This post walks through a complete example of how you can couple streaming feature engineering with Feature Store to make ML-backed decisions in near-real time. Apache Flink is a popular framework and engine for processing data streams. cc_num trans_time amount fraud_label …1248 Nov-01 14:50:01 10.15
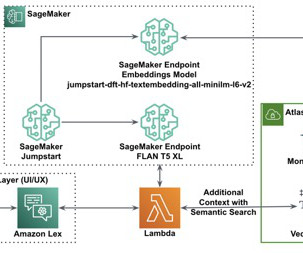
Let’s invoke the Amazon OpenSearch API to search relevant documents for the generated vector embeddings. The same feature engineering code is often run again and again, wasting time and compute resources on repeating the same operations. To avoid the reprocessing of features, we’ll export our data flow to an Amazon SageMaker pipeline.
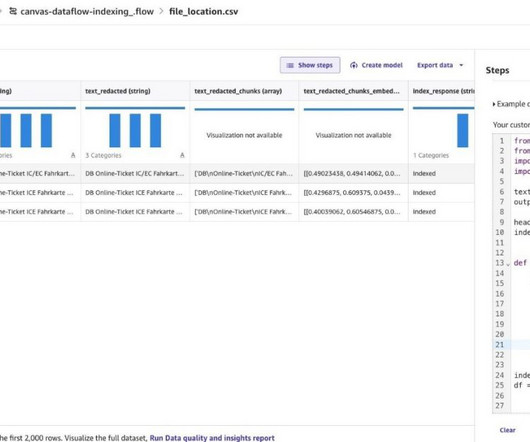
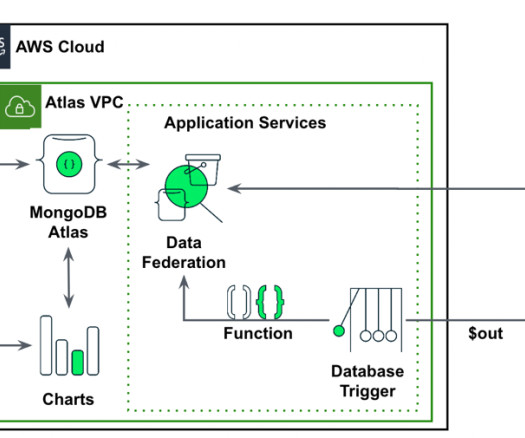
The SageMaker Canvas UI lets you seamlessly integrate data sources from the cloud or on-premises, merge datasets effortlessly, train precise models, and make predictions with emerging data—all without coding. Solution overview Users persist their transactional time series data in MongoDB Atlas.
Amp wanted a scalable data and analytics platform to enable easy access to data and perform machine leaning (ML) experiments for live audio transcription, content moderation, feature engineering, and a personal show recommendation service, and to inspect or measure business KPIs and metrics. DataEngineer for Amp on Amazon.
With over 35 patents granted across various technology domains, she has a passion for continuous innovation and using data to drive business outcomes. Shelbee is a co-creator and instructor of the Practical Data Science specialization on Coursera. She is also the Co-Director of Women In BigData (WiBD), Denver chapter.
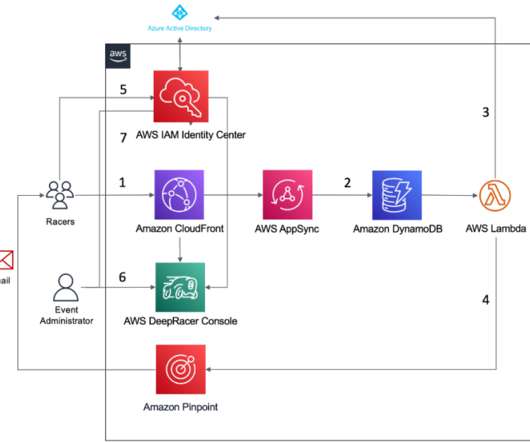
You can further personalize this page to gather additional user data (such as the user’s DeepRacer AWS profile or their level of AI and ML knowledge) or to add event marketing and training materials. The event portal registration form calls a customer API endpoint that stores email addresses in Amazon DynamoDB through AWS AppSync.
We set the OutputFormat to mp3 , which tells Amazon Polly to generate an audio stream for this API call. We again use the start_speech_synthesis_task method but specify OutputFormat to json , which tells Amazon Polly to generate speech marks for this API call. Anil Kodali is a Solutions Architect with Amazon Web Services.
Prepare your data As expected in the ML process, your dataset may require transformations to address issues such as missing values, outliers, or perform feature engineering prior to model building. SageMaker Canvas provides ML data transforms to clean, transform, and prepare your data for model building without having to write code.
This blog post was co-authored, and includes an introduction, by Zilong Bai, senior natural language processing engineer at Patsnap. They use bigdata (such as a history of past search queries) to provide many powerful yet easy-to-use patent tools. implement the model and the inference API. gpt2 and predictor.py
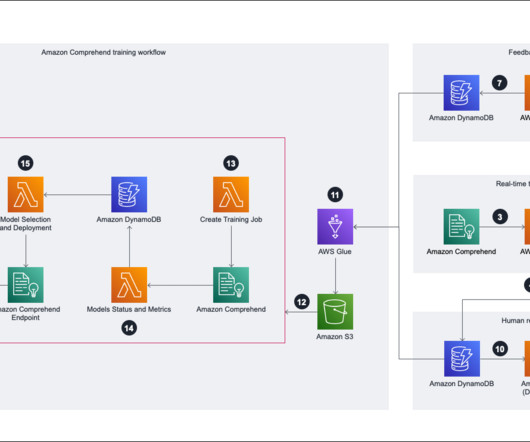
In this post, we explore how AWS customer Pro360 used the Amazon Comprehend custom classification API , which enables you to easily build custom text classification models using your business-specific labels without requiring you to learn machine learning (ML), to improve customer experience and reduce operational costs.
Model cards provide model risk managers, data scientists, and ML engineers the ability to perform the following tasks: Document model requirements such as risk rating, intended usage, limitations, and expected performance. The SageMaker Python SDK allows data scientists and ML engineers to easily interact with SageMaker components.
The solution also uses SAML attribute mapping to populate the SAML assertion with specific access-relevant data, such as user ID and user team. Because the solution creates a SAML API, you can use any IdP supporting SAML assertions to create this architecture. The API Gateway calls an SAML backend API. Custom SAML 2.0
Prior to our adoption of Kubeflow on AWS, our data scientists used a standardized set of tools and a process that allowed flexibility in the technology and workflow used to train a given model. Consequently, maintaining and augmenting older projects required more engineering time and effort.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content