This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With this solution, you can interact directly with the chat assistant powered by AWS from your Google Chat environment, as shown in the following example. The custom Google Chat app, configured for HTTP integration, sends an HTTP request to an API Gateway endpoint. The following figure illustrates the high-level design of the solution.
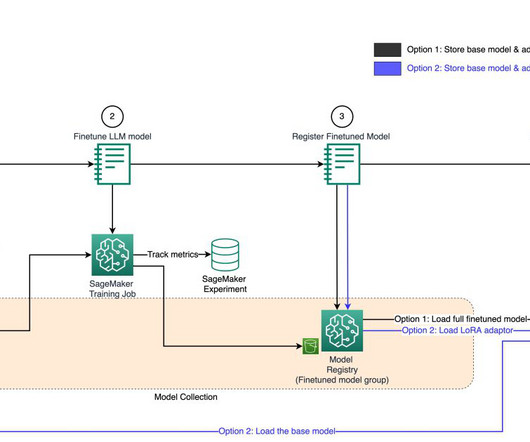
Customers can use the SageMaker Studio UI or APIs to specify the SageMaker Model Registry model to be shared and grant access to specific AWS accounts or to everyone in the organization. With this launch, customers can now seamlessly share and access ML models registered in SageMaker Model Registry between different AWS accounts.
Whether youre new to AI development or an experienced practitioner, this post provides step-by-step guidance and code examples to help you build more reliable AI applications. Lets walkthrough an example of how this solution would handle a users question. For example, if the question was What hotels are near re:Invent?
During these live events, F1 IT engineers must triage critical issues across its services, such as network degradation to one of its APIs. This impacts downstream services that consume data from the API, including products such as F1 TV, which offer live and on-demand coverage of every race as well as real-time telemetry.
Amazon SageMaker notebook jobs allow data scientists to run their notebooks on demand or on a schedule with a few clicks in SageMaker Studio. With this launch, you can programmatically run notebooks as jobs using APIs provided by Amazon SageMaker Pipelines , the ML workflow orchestration feature of Amazon SageMaker.
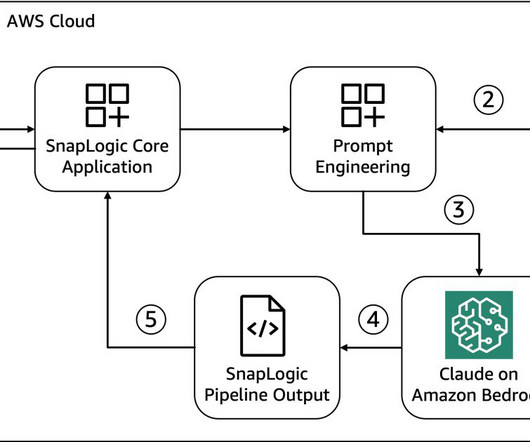
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. The integration with Amazon Bedrock is achieved through the Amazon Bedrock InvokeModel APIs.
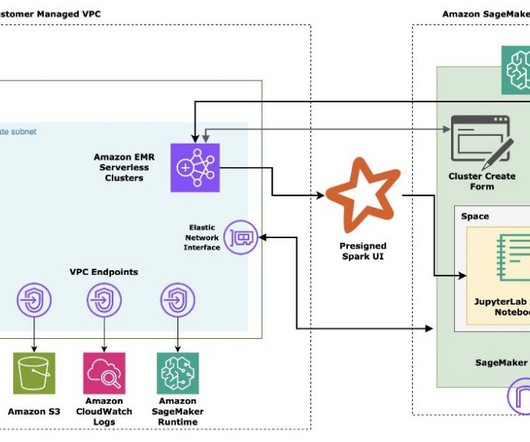
In the post Secure Amazon SageMaker Studio presigned URLs Part 2: Private API with JWT authentication , we demonstrated how to build a private API to generate Amazon SageMaker Studio presigned URLs that are only accessible by an authenticated end-user within the corporate network from a single account.
In this example, we start with the data science or portfolio agent. They provide access to external data and APIs or enable specific actions and computation. Hendra Suryanto is the Chief Data Scientist at RDC with more than 20 years of experience in data science, bigdata, and business intelligence.
It allows developers to build and scale generative AI applications using FMs through an API, without managing infrastructure. Customers are building innovative generative AI applications using Amazon Bedrock APIs using their own proprietary data.
Harnessing the power of bigdata has become increasingly critical for businesses looking to gain a competitive edge. However, managing the complex infrastructure required for bigdata workloads has traditionally been a significant challenge, often requiring specialized expertise. latest USER root RUN dnf install python3.11
It’s a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like Anthropic, Cohere, Meta, Mistral AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
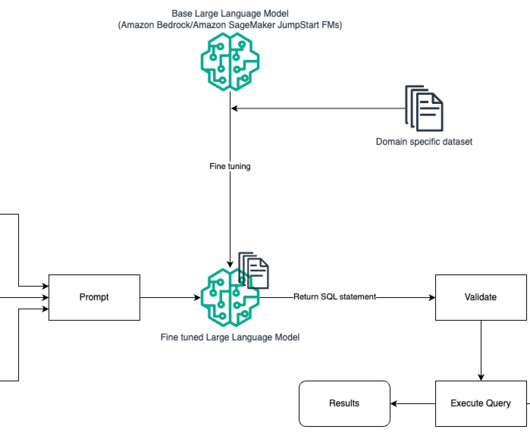
NLP SQL enables business users to analyze data and get answers by typing or speaking questions in natural language, such as the following: “Show total sales for each product last month” “Which products generated more revenue?” Fine-tuning directly trains the model on the end task but requires many text-SQL examples. gymnast_id = t2.
The Retrieve and RetrieveAndGenerate APIs allow your applications to directly query the index using a unified and standard syntax without having to learn separate APIs for each different vector database, reducing the need to write custom index queries against your vector store.
Example questions might be “What are the restrictions for CMR substances?”, “How long do I need to keep the documents related to a toluene sale?”, The following screenshot shows an example of the conversational interface. About the authors Vicente Cruz Mínguez is the Head of Data & Advanced Analytics at Cepsa Química.
You can now use cross-account support for Amazon SageMaker Pipelines to share pipeline entities across AWS accounts and access shared pipelines directly through Amazon SageMaker API calls. In this post, we present an example multi-account architecture for developing and deploying ML workflows with SageMaker Pipelines.
We explore two ways of obtaining the same result: via JumpStart’s graphical interface on Amazon SageMaker Studio , and programmatically through JumpStart APIs. If you want to jump straight into the JumpStart API code we go through in this post, you can refer to the following sample Jupyter notebook: Introduction to JumpStart – Text to Image.
The corporate portal application makes a private API call using an API Gateway VPC endpoint to create a presigned URL. The API Gateway VPC endpoint “create presigned URL” call is forwarded to the Route 53 inbound resolver on the customer VPC as configured in the corporate DNS. sagemaker.aws. About the Authors.
Agents automatically call the necessary APIs to interact with the company systems and processes to fulfill the request. The application architecture for building the example chat-based Generative AI Claims application with fine-grained access controls is shown in the following diagram.
This emergent ability in LLMs has compelled software developers to use LLMs as an automation and UX enhancement tool that transforms natural language to a domain-specific language (DSL): system instructions, API requests, code artifacts, and more.
In this post, we address these limitations by implementing the access control outside of the MLflow server and offloading authentication and authorization tasks to Amazon API Gateway , where we implement fine-grained access control mechanisms at the resource level using Identity and Access Management (IAM). Adds an IAM authorizer.
An example direct acyclic graph (DAG) might automate data ingestion, processing, model training, and deployment tasks, ensuring that each step is run in the correct order and at the right time. From our experience, artifact server has some limitations, such as limits on artifact size (because of sending it using REST API).
We explore two ways of obtaining the same result: via JumpStart’s graphical interface on Amazon SageMaker Studio , and programmatically through JumpStart APIs. The following sections provide a step-by-step demo to perform inference, both via the Studio UI and via JumpStart APIs. JumpStart overview. Solution overview.
The predictions (inference) use encrypted data and the results are only decrypted by the end consumer (client side). To demonstrate this, we show an example of customizing an Amazon SageMaker Scikit-learn, open sourced, deep learning container to enable a deployed endpoint to accept client-side encrypted inference requests.
For example, you can add custom terminology glossaries, while for LLMs, you might need fine-tuning that can be labor-intensive and costly. Here’s an example. For example, for science genres that have fewer idioms, you can turn the idiom detector off. The following is an example of an English sentence before shortening.
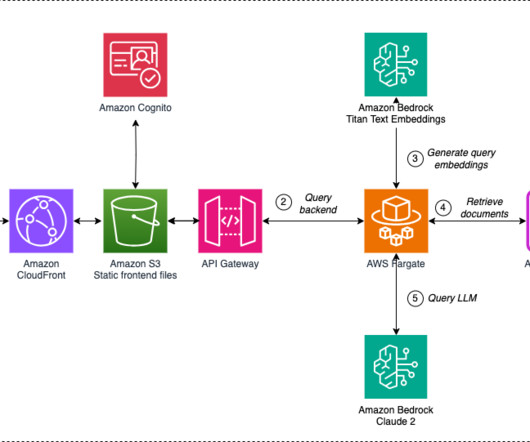
This solution uses an Amazon Cognito user pool as an OAuth-compatible identity provider (IdP), which is required in order to exchange a token with AWS IAM Identity Center and later on interact with the Amazon Q Business APIs. Amazon Q uses the chat_sync API to carry out the conversation.
If you need to establish a strong separation of security contexts, for example for different data categories, or need to entirely prevent the visibility of one group of users’ activity and resources to another, the recommended approach is to create multiple SageMaker domains. authorization process. Solution overview. Custom SAML 2.0
SageMaker Feature Store automatically builds an AWS Glue Data Catalog during feature group creation. Customers can also access offline store data using a Spark runtime and perform bigdata processing for ML feature analysis and feature engineering use cases. Table formats provide a way to abstract data files as a table.
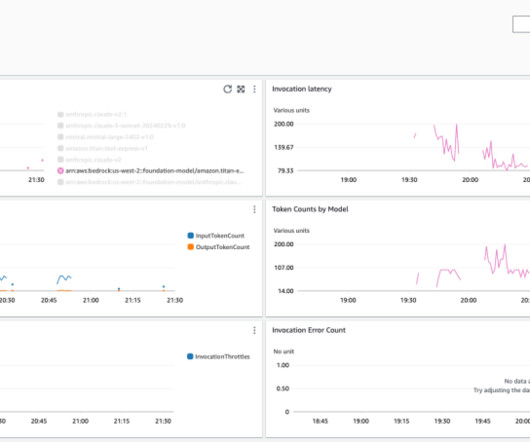
We will use the contextual conversational assistant example in the Amazon Bedrock GitHub repository to provide examples of how you can customize these views to further enhance visibility, tailored to your use case. For example, you can find out exactly who is using how many tokens or invocations.
Before you get started, refer to Part 1 for a high-level overview of the insurance use case with IDP and details about the data capture and classification stages. In Part 1, we saw how to use Amazon Textract APIs to extract information like forms and tables from documents, and how to analyze invoices and identity documents.
Access and permissions to configure IDP to register Data Wrangler application and set up the authorization server or API. For data scientist: An S3 bucket that Data Wrangler can use to output transformed data. An AWS account with permissions to create AWS Identity and Access Management (IAM) policies and roles.
To test the model output, we use a Jupyter notebook to run Python code to detect custom labels in a supplied image by calling Amazon Rekognition APIs. The solution workflow is as follows: Store satellite imagery data in Amazon S3 as the input source. Store satellite imagery data in Amazon S3 as an input source.
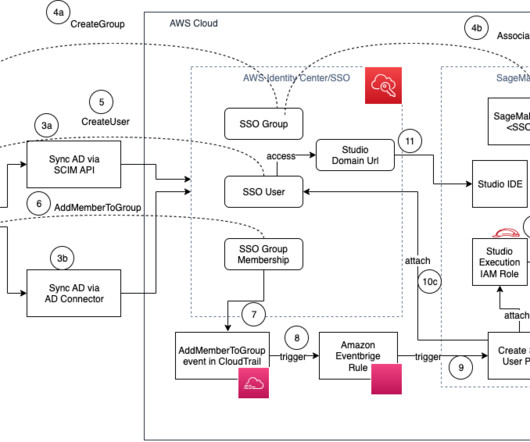
Sync your AD users and groups and memberships to AWS Identity Center: If you’re using an identity provider (IdP) that supports SCIM, use the SCIM API integration with IAM Identity Center. When the AD user is assigned to an AD group, an IAM Identity Center API ( CreateGroupMembership ) is invoked, and SSO group membership is created.
We explore two ways of obtaining the same result: via JumpStart’s graphical interface on Amazon SageMaker Studio , and programmatically through JumpStart APIs. The following sections provide a step-by-step demo to perform semantic segmentation with JumpStart, both via the Studio UI and via JumpStart APIs. Solution overview.
Join leading smart home service provider Vivint’s Ben Austin and Jacob Miller for an enlightening session on how they have designed and utilized automated speech analytics to extract KPI targeted scores and route those critical insights through an API to their own customized dashboard to track and coach on agent scoring/behaviors.
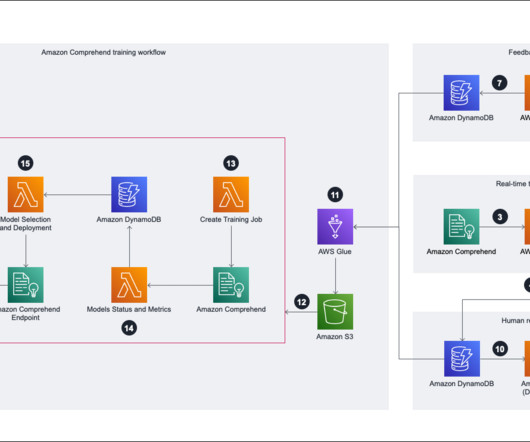
In this post, we explore how AWS customer Pro360 used the Amazon Comprehend custom classification API , which enables you to easily build custom text classification models using your business-specific labels without requiring you to learn machine learning (ML), to improve customer experience and reduce operational costs.
Open APIs: An open API model is advantageous in that it allows developers outside of companies to easily access and use APIs to create breakthrough innovations. At the same time, however, publicly available APIs are also exposed ones. billion GB of data were being produced every day in 2012 alone!)
In the era of bigdata and AI, companies are continually seeking ways to use these technologies to gain a competitive edge. At the core of these cutting-edge solutions lies a foundation model (FM), a highly advanced machine learning model that is pre-trained on vast amounts of data. Python 3.10
Reflection time is the time it takes for a feature to be available to read after the contributing events were emitted, for example, the time between a listener liking a show and the PIT LikeCount feature being updated. Sources of the data are the backend services directly serving the app. Data Engineer for Amp on Amazon.
In this example figure, features are extracted from raw historical data, which are then are fed into a neural network (NN). Due to model and data size, learning is distributed over multiple PBAs in an approach called parallelism. As shown in the preceding figure, the ML paradigm is learning (training) followed by inference.
For example, a health-tech company may be looking to improve patient care by predicting the probability that an elderly patient may become hospitalized by analyzing both clinical and non-clinical data. These device metrics and logs are ingested into and stored in a Splunk index , a repository of incoming data.
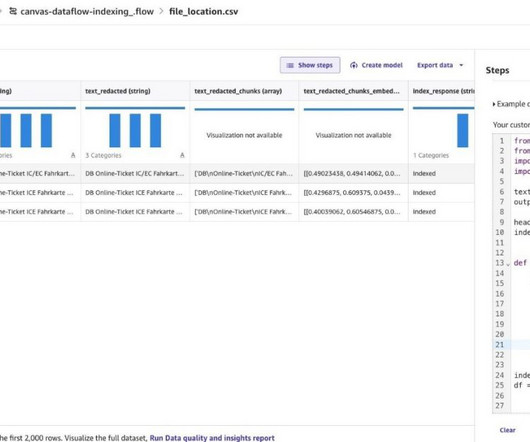
In this example, we have chosen Amazon OpenSearch as our vector database. From the example code snippets, browse and select extract text from pdf. Let’s add a step to redact Personal Identifiable Information (PII) data from the extracted data by leveraging Amazon Comprehend. Choose Add Step and choose Custom Transform.
The SageMaker Python SDK provides open-source APIs and containers to train and deploy models on SageMaker, using several different ML and deep learning frameworks. In this post, we walk you through an example of how to build and deploy a custom Hugging Face text summarizer on SageMaker. return tokenized_dataset. to(device).eval().
Follow the normal practice of least-privilege access, for example restricting incoming prompts from other systems. Because the interface between agents and tools is less formally defined than an API contract, you should monitor these traces not only for performance but also to capture new error scenarios.
With a data flow, you can prepare data using generative AI, over 300 built-in transforms, or custom Spark commands. Complete the following steps: Choose Prepare and analyze data. For Data flow name , enter a name (for example, AssessingMentalHealthFlow ). SageMaker Data Wrangler will open. Choose Create.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content