This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The solution integrates large language models (LLMs) with your organization’s data and provides an intelligent chat assistant that understands conversation context and provides relevant, interactive responses directly within the Google Chat interface. The following figure illustrates the high-level design of the solution.
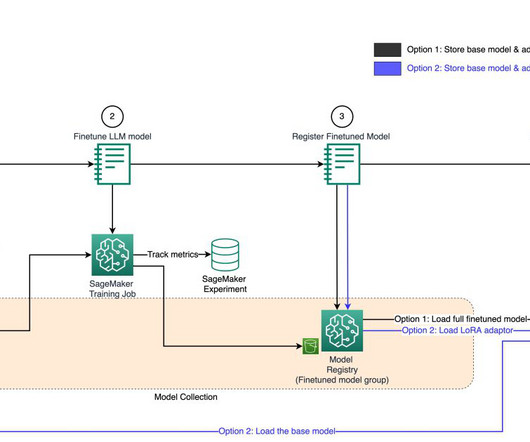
Customers can use the SageMaker Studio UI or APIs to specify the SageMaker Model Registry model to be shared and grant access to specific AWS accounts or to everyone in the organization. We will demonstrate how to set up a central model registry based on the architecture we described in the previous sections.
Solution overview Our solution implements a verified semantic cache using the Amazon Bedrock Knowledge Bases Retrieve API to reduce hallucinations in LLM responses while simultaneously improving latency and reducing costs. The function checks the semantic cache (Amazon Bedrock Knowledge Bases) using the Retrieve API.
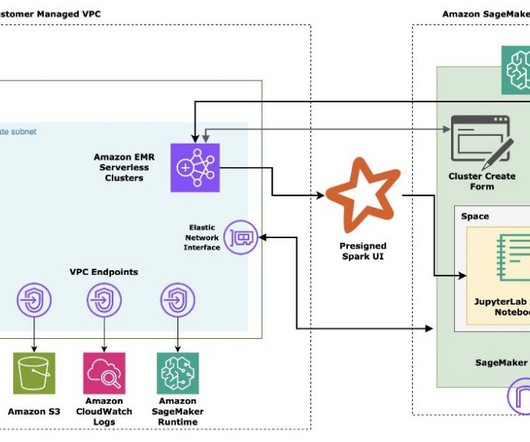
In part 1 of this series, we demonstrated how to resolve an Amazon SageMaker Studio presigned URL from a corporate network using Amazon private VPC endpoints without traversing the internet. The user invokes createStudioPresignedUrl API on API Gateway along with a token in the header. Deploy the solution. Deploy the solution.
In the post Secure Amazon SageMaker Studio presigned URLs Part 2: Private API with JWT authentication , we demonstrated how to build a private API to generate Amazon SageMaker Studio presigned URLs that are only accessible by an authenticated end-user within the corporate network from a single account.
During these live events, F1 IT engineers must triage critical issues across its services, such as network degradation to one of its APIs. This impacts downstream services that consume data from the API, including products such as F1 TV, which offer live and on-demand coverage of every race as well as real-time telemetry.
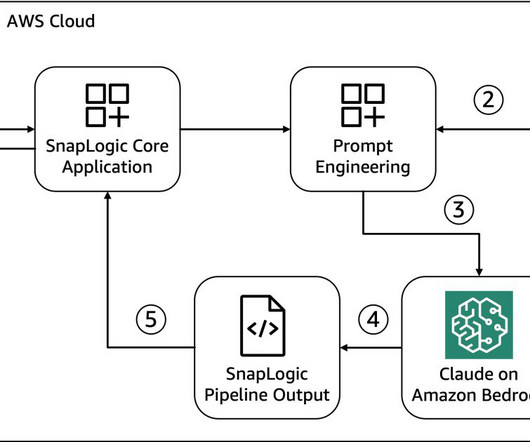
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. The integration with Amazon Bedrock is achieved through the Amazon Bedrock InvokeModel APIs.
It allows developers to build and scale generative AI applications using FMs through an API, without managing infrastructure. Customers are building innovative generative AI applications using Amazon Bedrock APIs using their own proprietary data.
They provide access to external data and APIs or enable specific actions and computation. For more information about how to work with RDC and AWS and to understand how were supporting banking customers around the world to use AI in credit decisions, contact your AWS Account Manager or visit Rich Data Co.
In this post, we show you how to unlock new levels of efficiency and creativity by bringing the power of generative AI directly into your Slack workspace using Amazon Bedrock. We show how to create a Slack application, configure the necessary permissions, and deploy the required resources using AWS CloudFormation.
Harnessing the power of bigdata has become increasingly critical for businesses looking to gain a competitive edge. However, managing the complex infrastructure required for bigdata workloads has traditionally been a significant challenge, often requiring specialized expertise.
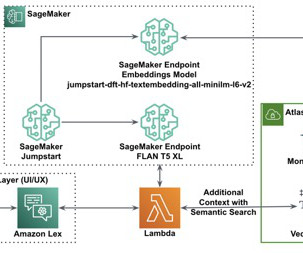
RAG starts with an initial step to retrieve relevant documents from a data store (most commonly a vector index) based on the user’s query. In this post, we demonstrate how to build a RAG workflow using Knowledge Bases for Amazon Bedrock for a drug discovery use case. When the sync is complete, the Sync history shows status Completed.
This post demonstrates how to build a custom UI for Amazon Q Business. This solution uses an Amazon Cognito user pool as an OAuth-compatible identity provider (IdP), which is required in order to exchange a token with AWS IAM Identity Center and later on interact with the Amazon Q Business APIs.
Having said that, here are three massive IoT security threats we’re seeing today (and how to expertly address them): Personally-owned devices: Research shows that about 40% of U.S. Open APIs: An open API model is advantageous in that it allows developers outside of companies to easily access and use APIs to create breakthrough innovations.
However, scaling up generative AI and making adoption easier for different lines of businesses (LOBs) comes with challenges around making sure data privacy and security, legal, compliance, and operational complexities are governed on an organizational level. In this post, we discuss how to address these challenges holistically.
In this post, we address these limitations by implementing the access control outside of the MLflow server and offloading authentication and authorization tasks to Amazon API Gateway , where we implement fine-grained access control mechanisms at the resource level using Identity and Access Management (IAM).
In this part, we discuss the overarching architecture for securing studio pre-signed url and demonstrate how to set up the foundational infrastructure to create and launch a Studio presigned URL through your VPC endpoint over a private network without traversing the internet. Optionally, it looks up a private hosted zone record if it exists.
In the first post , we showed how you can run image classification use cases on JumpStart. In the second post , we demonstrated how to run text classification use cases. In the fourth post , we showed how you can run text generation use cases. The model page contains valuable information about the model and how to use it.
In the first post , we showed how to run image classification use cases on JumpStart. In the second post , we demonstrated how to run text classification use cases. In this post, we provide a step-by-step walkthrough on how to deploy pre-trained text generation models. In the third post , we ran image segmentation use cases.
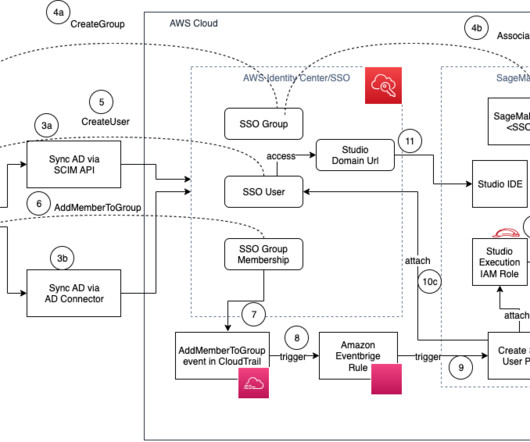
Sync your AD users and groups and memberships to AWS Identity Center: If you’re using an identity provider (IdP) that supports SCIM, use the SCIM API integration with IAM Identity Center. When the AD user is assigned to an AD group, an IAM Identity Center API ( CreateGroupMembership ) is invoked, and SSO group membership is created.
You can now use cross-account support for Amazon SageMaker Pipelines to share pipeline entities across AWS accounts and access shared pipelines directly through Amazon SageMaker API calls. The data scientist is now able to describe and monitor the test pipeline run status using SageMaker API calls from the dev account.
Data using FHE is larger in size, so testing must be done for applications that need the inference to be performed in near-real time or with size limitations. In this post, we show how to activate privacy-preserving ML predictions for the most highly regulated environments. The following figure shows both versions of these patterns.
In Part 1 of this series, we discussed intelligent document processing (IDP), and how IDP can accelerate claims processing use cases in the insurance industry. We discussed how we can use AWS AI services to accurately categorize claims documents along with supporting documents. Extraction phase. client('comprehend').
Generative AI models have the potential to revolutionize enterprise operations, but businesses must carefully consider how to harness their power while overcoming challenges such as safeguarding data and ensuring the quality of AI-generated content. To update all objects follow the instructions. Delete the Lambda function.
Tweet Managing your API’s has become a very complicated endeavor. If your role to is manage API’s it’s important to figure out how to automate that process. Today 3scale and Pivotal ® announced that the 3scale self-serve API management solution is available through the Pivotal Web Services (PWS) platform.
Agents automatically call the necessary APIs to interact with the company systems and processes to fulfill the request. We also show how to restrict permissions using custom attributes such as a user’s region for filtering insurance claims. Claims API Gateway runs the Custom Authorizer to validate the access token.
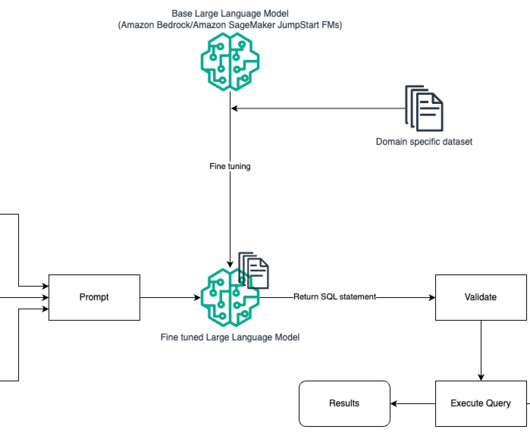
NLP SQL enables business users to analyze data and get answers by typing or speaking questions in natural language, such as the following: “Show total sales for each product last month” “Which products generated more revenue?” These act like instructions that tell the model how to format the SQL output. Arghya Banerjee is a Sr.
In this section, you’ll learn how to create a custom dashboard using an example RAG based architecture that utilizes Amazon Bedrock. With over 35 patents granted across various technology domains, she has a passion for continuous innovation and using data to drive business outcomes.
By the end of this post, you will know how to create feature groups using the Iceberg format, execute Iceberg’s table management procedures using Amazon Athena , and schedule these tasks to run autonomously. SageMaker Feature Store automatically builds an AWS Glue Data Catalog during feature group creation.
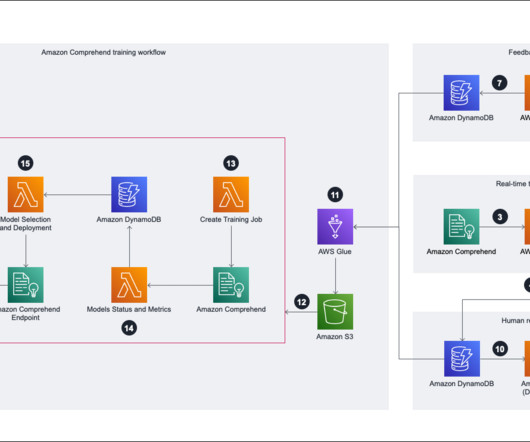
In this post, we explore how AWS customer Pro360 used the Amazon Comprehend custom classification API , which enables you to easily build custom text classification models using your business-specific labels without requiring you to learn machine learning (ML), to improve customer experience and reduce operational costs.
One of the most common real-world challenges in setting up user access for Studio is how to manage multiple users, groups, and data science teams for data access and resource isolation. The solution outlines how to use a custom SAML 2.0 The API Gateway calls an SAML backend API. authorization process.
In this post, we provide a step-by-step walkthrough on how to fine-tune and deploy an image segmentation model, using trained models from MXNet. We explore two ways of obtaining the same result: via JumpStart’s graphical interface on Amazon SageMaker Studio , and programmatically through JumpStart APIs. Solution overview.
In the following sections, you will learn how to use the unique features of Amazon Translate for setting formality tone and for custom terminology. You will also learn how to use Amazon Bedrock to further improve the quality of video dubbing. Yaoqi Zhang is a Senior BigData Engineer at Mission Cloud.
In this post, we show how to configure a new OAuth-based authentication feature for using Snowflake in Amazon SageMaker Data Wrangler. Snowflake is a cloud data platform that provides data solutions for data warehousing to data science. Specify the lifetime of the access token.
They use bigdata (such as a history of past search queries) to provide many powerful yet easy-to-use patent tools. In this section, we show how to build your own container, deploy your own GPT-2 model, and test with the SageMaker endpoint API. implement the model and the inference API. gpt2 and predictor.py
This emergent ability in LLMs has compelled software developers to use LLMs as an automation and UX enhancement tool that transforms natural language to a domain-specific language (DSL): system instructions, API requests, code artifacts, and more.
In this post, we show how to label, train, and build a computer vision model to detect rooftops and solar panels from satellite images. To test the model output, we use a Jupyter notebook to run Python code to detect custom labels in a supplied image by calling Amazon Rekognition APIs. On the model page, choose API Code.
But modern analytics goes beyond basic metricsit leverages technologies like call center data science, machine learning models, and bigdata to provide deeper insights. Predictive Analytics: Uses historical data to forecast future events like call volumes or customer churn. What is contact center bigdata analytics?
They faced two challenges: how to reduce food waste, and how to manage forecast models for over 10,000 SKUs and thousands of stores efficiently and at scale. We can then call a Forecast API to create a dataset group and import data from the processed S3 bucket. Summary and next steps. About the Authors.
Because the interface between agents and tools is less formally defined than an API contract, you should monitor these traces not only for performance but also to capture new error scenarios. Conclusion This post described how to take resilience into account when building generative AI solutions.
seek_help Does your employer provide resources to learn more about mental health issues and how to seek help? leave How easy is it for you to take medical leave for a mental health condition? You can change the configuration later from the SageMaker Canvas UI or using SageMaker APIs. Set Instance count to 1. Choose Deploy.
This example notebook demonstrates the pattern of using Feature Store as a central repository from which data scientists can extract training datasets. In addition to creating a training dataset, we use the PutRecord API to put the 1-week feature aggregations into the online feature store nightly. Nov-01,22:01:00 1 74.99 …9843 99.50
Join leading smart home service provider Vivint’s Ben Austin and Jacob Miller for an enlightening session on how they have designed and utilized automated speech analytics to extract KPI targeted scores and route those critical insights through an API to their own customized dashboard to track and coach on agent scoring/behaviors.
In the era of bigdata and AI, companies are continually seeking ways to use these technologies to gain a competitive edge. At the core of these cutting-edge solutions lies a foundation model (FM), a highly advanced machine learning model that is pre-trained on vast amounts of data.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content