This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Solution overview Our solution implements a verified semantic cache using the Amazon Bedrock KnowledgeBases Retrieve API to reduce hallucinations in LLM responses while simultaneously improving latency and reducing costs. The function checks the semantic cache (Amazon Bedrock KnowledgeBases) using the Retrieve API.
The custom Google Chat app, configured for HTTP integration, sends an HTTP request to an API Gateway endpoint. Before processing the request, a Lambda authorizer function associated with the API Gateway authenticates the incoming message. If you don’t have an existing knowledgebase, refer to Create an Amazon Bedrock knowledgebase.
KnowledgeBases for Amazon Bedrock allows you to build performant and customized Retrieval Augmented Generation (RAG) applications on top of AWS and third-party vector stores using both AWS and third-party models. RAG is a popular technique that combines the use of private data with large language models (LLMs).
During these live events, F1 IT engineers must triage critical issues across its services, such as network degradation to one of its APIs. This impacts downstream services that consume data from the API, including products such as F1 TV, which offer live and on-demand coverage of every race as well as real-time telemetry.
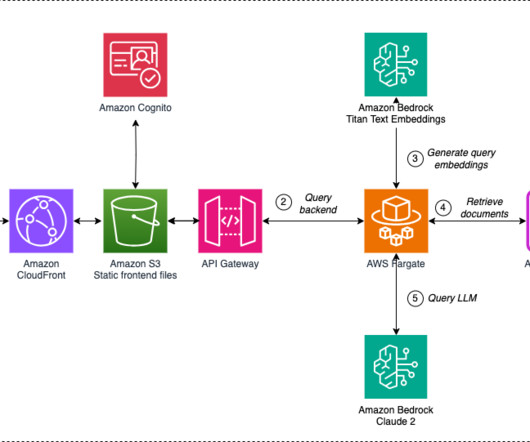
Solution overview In this solution, we deploy a custom web experience for Amazon Q to deliver quick, accurate, and relevant answers to your business questions on top of an enterprise knowledgebase. Amazon Q uses the chat_sync API to carry out the conversation. The following diagram illustrates the solution architecture.
It’s a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like Anthropic, Cohere, Meta, Mistral AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
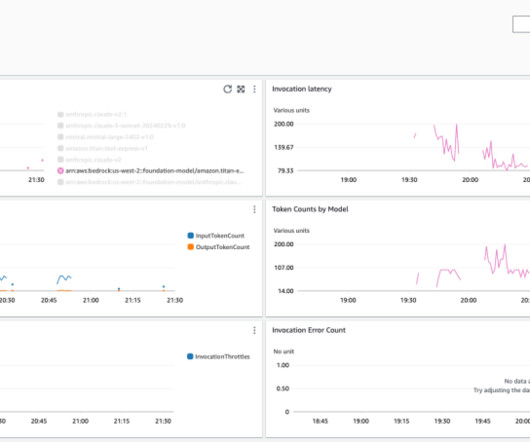
This dashboard provides a holistic view of metrics pertaining to: The number of invocations and token usage that the Amazon Bedrock embedding model used to create your knowledgebase and embed user queries as well as the Amazon Bedrock model used to respond to user queries given the context provided by the knowledgebase.
In the batch case, there are a couple challenges compared to typical data pipelines. The data sources may be PDF documents on a file system, data from a software as a service (SaaS) system like a CRM tool, or data from an existing wiki or knowledgebase. He also holds an MBA from Colorado State University.
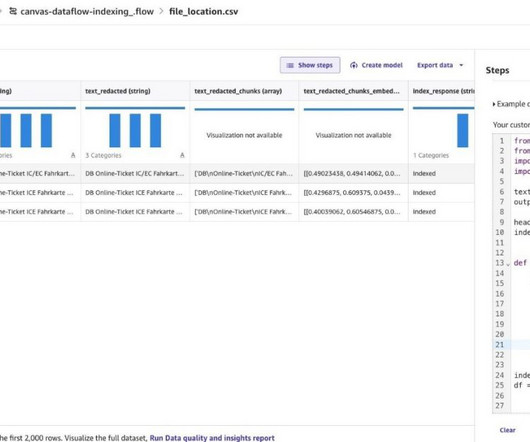
We’ll point our search data flow to the file and output a file with corresponding results in a new file in an Amazon S3 location. Preparing a prompt After we create a knowledgebase out of our PDF, we can test it by searching the knowledgebase for a few sample queries. Add a custom transform with Python (PySpark).
SaaS works well for a variety of general use cases, including: Data backup. Bigdata analytics. Flexibility – SaaS uses an open API (application programming interface) technology. They’d rather take the lead and get an answer on their own using an automated voice response system or a knowledgebase.
But modern analytics goes beyond basic metricsit leverages technologies like call center data science, machine learning models, and bigdata to provide deeper insights. Predictive Analytics: Uses historical data to forecast future events like call volumes or customer churn. Immediate access to knowledgebases or FAQs.
Knowledgebased and FAQ’s are not a one and done. For Partner Colorado, Enghouse’s use of open APIs allows integration with the in-house CRM. Instead of having to toggle back and forth between different screens and applications, agents proactively receive relevant and useful data on callers via ScreenPop.
With time, it develops a massive knowledgebase and can anticipate the user or customer requirements. AI can learn from its past experiences and formulates predictions based on data. Interpret bigdata. Industries collect mounds and mounds of data in a single day.
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. The integration with Amazon Bedrock is achieved through the Amazon Bedrock InvokeModel APIs.
To solve this challenge, RDC used generative AI , enabling teams to use its solution more effectively: Data science assistant Designed for data science teams, this agent assists teams in developing, building, and deploying AI models within a regulated environment. Tools Tools extend agent capabilities beyond the FM.
An approach to product stewardship with generative AI Large language models (LLMs) are trained with vast amounts of information crawled from the internet, capturing considerable knowledge from multiple domains. However, their knowledge is static and tied to the data used during the pre-training phase.
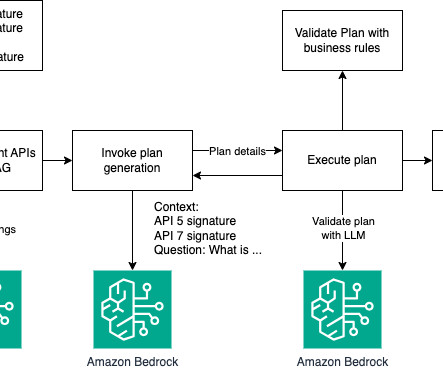
In this context, the term tools refer to external capabilities or APIs that the model can access and interact with to extend its functionality beyond text-based responses. By planning, the LLM can break down a complex question into manageable steps, making sure that the right APIs are called in the correct order.
Enterprises are facing challenges in accessing their data assets scattered across various sources because of increasing complexities in managing vast amount of data. Traditional search methods often fail to provide comprehensive and contextual results, particularly for unstructured data or complex queries.
Tecton accommodates these latency requirements by integrating with both disk-based and in-memory data stores, supporting in-memory caching, and serving features for inference through a low-latency REST API, which integrates with SageMaker endpoints. Now we can complete our fraud detection use case.
We showcase a variety of tools including database retrieval with Text2SQL, statistical models and visual charts with scientific libraries, biomedical literature search with public APIs and internal evidence, and medical image processing with Amazon SageMaker jobs. Architecture diagram showing Agents for Bedrock system flow.
NIM microservices provide straightforward integration into generative AI applications using industry-standard APIs and can be deployed with just a few lines of code, or with a few clicks on the SageMaker JumpStart console. For inference request format, NIM on SageMaker supports the OpenAI API inference protocol (at the time of writing).
Amazon Bedrock Flows provide a powerful, low-code solution for creating complex generative AI workflows with an intuitive visual interface and with a set of APIs in the Amazon Bedrock SDK. The agent submits the following query to the knowledgebase: Product specifications and market context for Interest Rate option USD_2Y_1Y.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content