This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
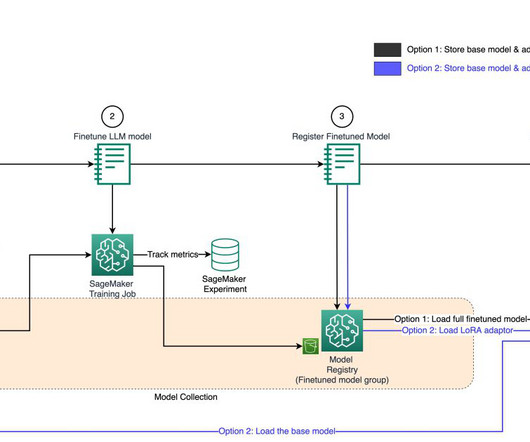
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
The custom Google Chat app, configured for HTTP integration, sends an HTTP request to an API Gateway endpoint. Before processing the request, a Lambda authorizer function associated with the API Gateway authenticates the incoming message. The following figure illustrates the high-level design of the solution.
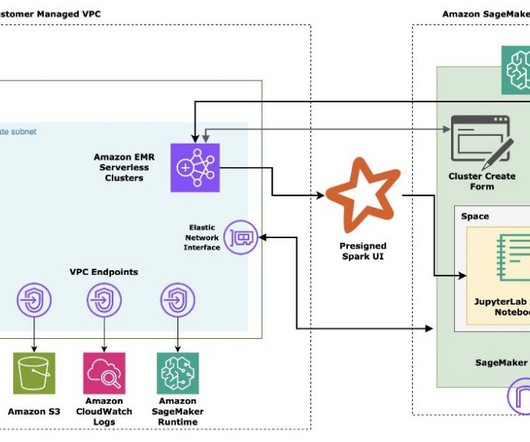
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machine learning (ML) models. Amazon SageMaker notebook jobs allow data scientists to run their notebooks on demand or on a schedule with a few clicks in SageMaker Studio.
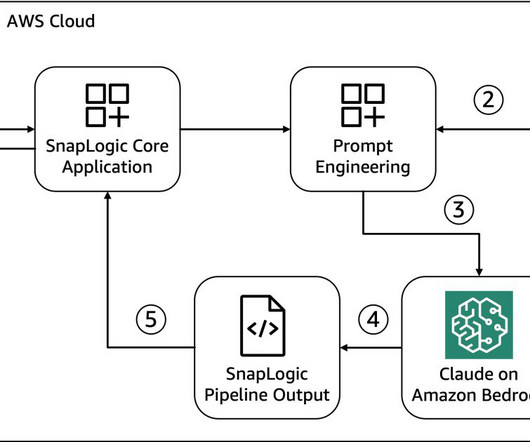
Agent Creator is a versatile extension to the SnapLogic platform that is compatible with modern databases, APIs, and even legacy mainframe systems, fostering seamless integration across various data environments. Its low-code interface drastically reduces the time needed to develop generative AI applications.
In this post, we will continue to build on top of the previous solution to demonstrate how to build a private API Gateway via Amazon API Gateway as a proxy interface to generate and access Amazon SageMaker presigned URLs. The user invokes createStudioPresignedUrl API on API Gateway along with a token in the header.
Solution overview Our solution implements a verified semantic cache using the Amazon Bedrock Knowledge Bases Retrieve API to reduce hallucinations in LLM responses while simultaneously improving latency and reducing costs. The function checks the semantic cache (Amazon Bedrock Knowledge Bases) using the Retrieve API.
During these live events, F1 IT engineers must triage critical issues across its services, such as network degradation to one of its APIs. This impacts downstream services that consume data from the API, including products such as F1 TV, which offer live and on-demand coverage of every race as well as real-time telemetry.
It aims to boost team efficiency by answering complex technical queries across the machine learning operations (MLOps) lifecycle, drawing from a comprehensive knowledge base that includes environment documentation, AI and data science expertise, and Python code generation. For portfolio managers, we prioritized high-level commercial insights.
In the post Secure Amazon SageMaker Studio presigned URLs Part 2: Private API with JWT authentication , we demonstrated how to build a private API to generate Amazon SageMaker Studio presigned URLs that are only accessible by an authenticated end-user within the corporate network from a single account.
Amazon Bedrock is a fully managed service provided by AWS that offers developers access to foundation models (FMs) and the tools to customize them for specific applications. It allows developers to build and scale generative AI applications using FMs through an API, without managing infrastructure.
Harnessing the power of bigdata has become increasingly critical for businesses looking to gain a competitive edge. However, managing the complex infrastructure required for bigdata workloads has traditionally been a significant challenge, often requiring specialized expertise.
You can now use cross-account support for Amazon SageMaker Pipelines to share pipeline entities across AWS accounts and access shared pipelines directly through Amazon SageMaker API calls. Customers are increasingly adopting multi-account architectures for deploying and managing machine learning (ML) workflows with SageMaker Pipelines.
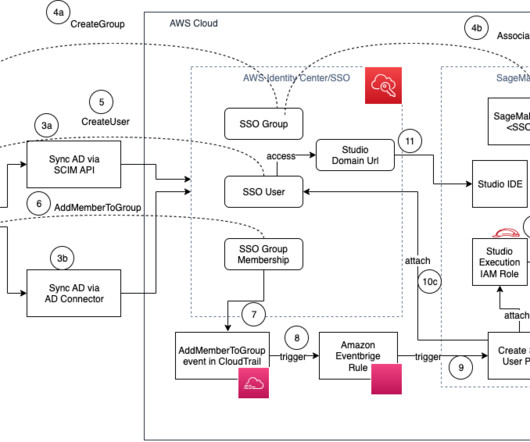
Each onboarded user in Studio has their own dedicated set of resources, such as compute instances, a home directory on an Amazon Elastic File System (Amazon EFS) volume, and a dedicated AWS Identity and Access Management (IAM) execution role. Organizations manage their users in AWS SSO instead of the SageMaker domain.
In the era of bigdata and AI, companies are continually seeking ways to use these technologies to gain a competitive edge. At the core of these cutting-edge solutions lies a foundation model (FM), a highly advanced machine learning model that is pre-trained on vast amounts of data.
However, scaling up generative AI and making adoption easier for different lines of businesses (LOBs) comes with challenges around making sure data privacy and security, legal, compliance, and operational complexities are governed on an organizational level. In this post, we discuss how to address these challenges holistically.
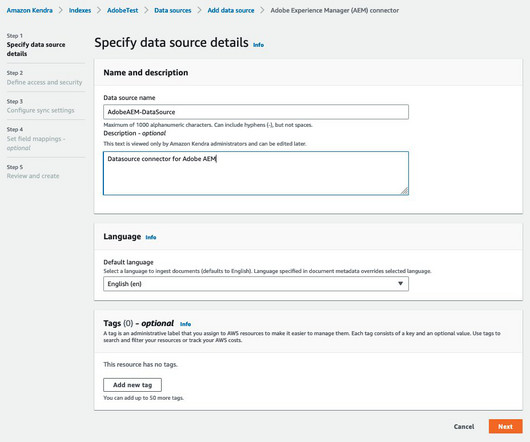
With Amazon Kendra, you can easily aggregate content from a variety of content repositories into an index that lets you quickly search all your enterprise data and find the most accurate answer. Adobe Experience Manager (AEM) is a content management system that’s used for creating website or mobile app content. and above).
The Slack application sends the event to Amazon API Gateway , which is used in the event subscription. API Gateway forwards the event to an AWS Lambda function. About the Authors Rushabh Lokhande is a Senior Data & ML Engineer with AWS Professional Services Analytics Practice.
It allows you to seamlessly customize your RAG prompts and retrieval strategies—we provide the source attribution, and we handle memory management automatically. RAG is a popular technique that combines the use of private data with large language models (LLMs). Choose Next. Choose Next.
This blog post delves into the details of this MLOps platform, exploring how the integration of these tools facilitates a more efficient and scalable approach to managing ML projects. This setup not only simplifies infrastructure management, but also ensures that resources are used efficiently, scaling up or down as needed.
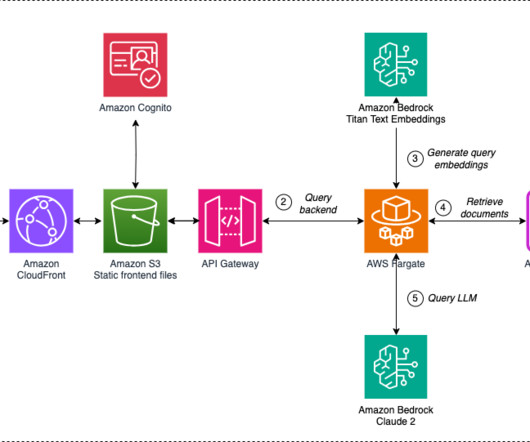
The Product Stewardship department is responsible for managing a large collection of regulatory compliance documents. The backend is implemented by an LLM chain service running on AWS Fargate , a serverless, pay-as-you-go compute engine that lets you focus on building applications without managing servers.
Tweet Managing your API’s has become a very complicated endeavor. If your role to is manageAPI’s it’s important to figure out how to automate that process. Reducing the effort required to manageAPI’s can be keep to using resources in other ways that are not as easily automated.
You can access Amazon SageMaker Studio notebooks from the Amazon SageMaker console via AWS Identity and Access Management (IAM) authenticated federation from your identity provider (IdP), such as Okta. The corporate portal application makes a private API call using an API Gateway VPC endpoint to create a presigned URL.
In this post, we look at how to use Amazon SageMaker Role Manager to quickly build out a set of persona-based roles that can be further customized to your specific requirements in minutes, right on the Amazon SageMaker console. They’re permitted to manage models, endpoints, and pipelines, and audit resources. ML activities.
This solution uses an Amazon Cognito user pool as an OAuth-compatible identity provider (IdP), which is required in order to exchange a token with AWS IAM Identity Center and later on interact with the Amazon Q Business APIs. Amazon Q uses the chat_sync API to carry out the conversation. Enter an application name and description.
With Amazon SageMaker , you can manage the whole end-to-end machine learning (ML) lifecycle. It offers many native capabilities to help manage ML workflows aspects, such as experiment tracking, and model governance via the model registry. Now let’s dive deeper into the details.
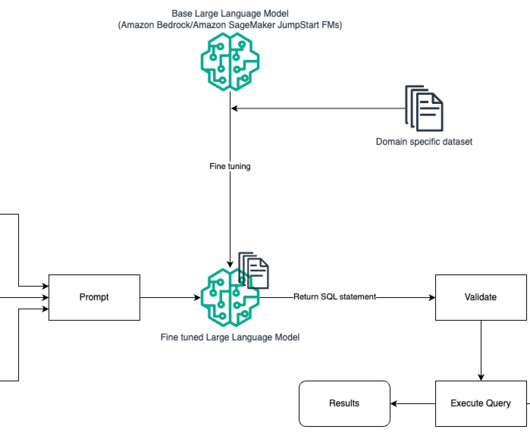
NLP SQL enables business users to analyze data and get answers by typing or speaking questions in natural language, such as the following: “Show total sales for each product last month” “Which products generated more revenue?” In entered the BigData space in 2013 and continues to explore that area. Arghya Banerjee is a Sr.
We explore two ways of obtaining the same result: via JumpStart’s graphical interface on Amazon SageMaker Studio , and programmatically through JumpStart APIs. If you want to jump straight into the JumpStart API code we go through in this post, you can refer to the following sample Jupyter notebook: Introduction to JumpStart – Text to Image.
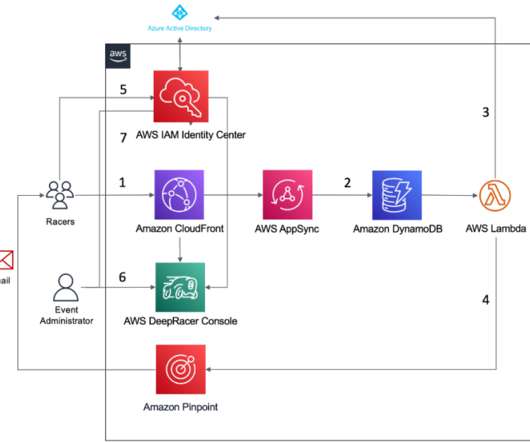
With AWS DeepRacer multi-user account management , event organizers can provide hundreds of participants access to AWS DeepRacer using a single AWS account, simplifying event management and improving the participant experience. Build a solution around AWS DeepRacer multi-user account management.
When creating your SageMaker domain, you can choose to use either AWS IAM Identity Center (successor to AWS Single Sign-On) or AWS Identity and Access Management (IAM) for user authentication methods. If you are using self-managed AD, you may use AD Connector. The EventBridge rule triggers the target AWS Lambda function.
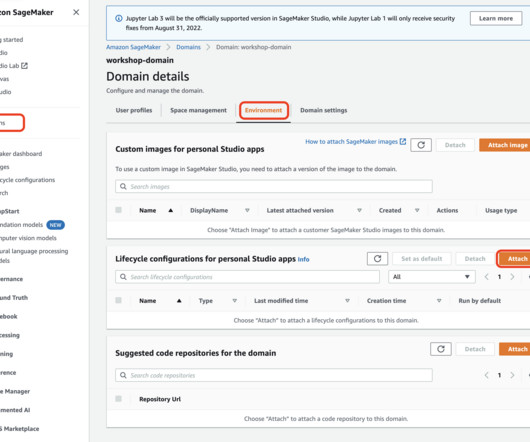
This post presents and compares options and recommended practices on how to manage Python packages and virtual environments in Amazon SageMaker Studio notebooks. You can manage app images via the SageMaker console, the AWS SDK for Python (Boto3), and the AWS Command Line Interface (AWS CLI). Launch the custom image in Studio.
Agents automatically call the necessary APIs to interact with the company systems and processes to fulfill the request. Verified Permissions is a scalable permissions management and authorization service for custom applications built by you. Claims API Gateway runs the Custom Authorizer to validate the access token.
We explore two ways of obtaining the same result: via JumpStart’s graphical interface on Amazon SageMaker Studio , and programmatically through JumpStart APIs. The following sections provide a step-by-step demo to perform inference, both via the Studio UI and via JumpStart APIs. JumpStart overview. Solution overview.
As feature data grows in size and complexity, data scientists need to be able to efficiently query these feature stores to extract datasets for experimentation, model training, and batch scoring. SageMaker Feature Store consists of an online and an offline mode for managing features.
Product Manager; and Rich Dill, Enterprise Solutions Architect from SnapLogic. This emergent ability in LLMs has compelled software developers to use LLMs as an automation and UX enhancement tool that transforms natural language to a domain-specific language (DSL): system instructions, API requests, code artifacts, and more.
AWS Glue is a part of the AWS Analytics services stack, and is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development. Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. Prerequisites.
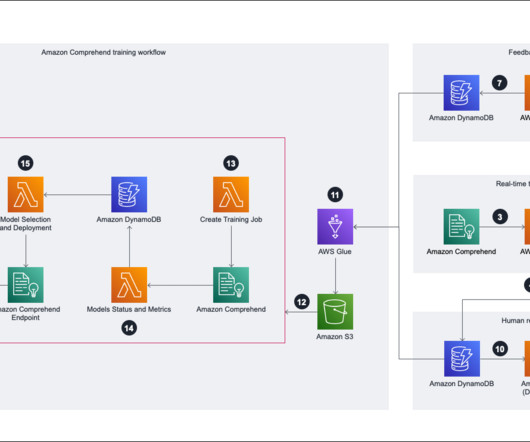
Amazon Comprehend is a fully managed and continuously trained natural language processing (NLP) service that can extract insight about the content of a document or text. The steps are as follows: The client side calls Amazon API Gateway as the entry point to provide a client message as input. API Gateway bypasses the request to Lambda.
Collecting raw data for batch feature computing doesn’t have the sub-minute reflection time requirement PIT features have, which makes it feasible to buffer the events longer and transform metrics in batch. The underlying infrastructure for a Processing job is fully managed by SageMaker. Operational health.
An AWS account with permissions to create AWS Identity and Access Management (IAM) policies and roles. Access and permissions to configure IDP to register Data Wrangler application and set up the authorization server or API. For data scientist: An S3 bucket that Data Wrangler can use to output transformed data.
Because the interface between agents and tools is less formally defined than an API contract, you should monitor these traces not only for performance but also to capture new error scenarios. Randy has held a variety of positions in the technology space, ranging from software engineering to product management.
Applications and services can call the deployed endpoint directly or through a deployed serverless Amazon API Gateway architecture. To learn more about real-time endpoint architectural best practices, refer to Creating a machine learning-powered REST API with Amazon API Gateway mapping templates and Amazon SageMaker.
Part 1 shows how data was collected and processed using the data and analytics platform, and Part 2 shows how the data was used to create show recommendations using Amazon SageMaker , a fully managed ML service. Streaming data ingestion, processing, transformation, and storage.
They faced two challenges: how to reduce food waste, and how to manage forecast models for over 10,000 SKUs and thousands of stores efficiently and at scale. Advanced inventory forecasting using machine learning (ML) allows retail stores to maximize sales and minimize waste through more effective inventory management and turnover.
Yaoqi Zhang is a Senior BigData Engineer at Mission Cloud. Adrian Martin is a BigData/Machine Learning Lead Engineer at Mission Cloud. Amazon Translate is a neural machine translation service that delivers fast, high-quality, and affordable language translation.
The greatest areas of investment in service organizations and contact centers are in AI, robotic process automation (RPA), bigdata and digital-oriented applications, all of which are delivered via the cloud. Adoption of cloud-based recording is starting to pick up momentum, as is analytics-enabled quality management (QM). .
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content