This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The custom Google Chat app, configured for HTTP integration, sends an HTTP request to an API Gateway endpoint. Before processing the request, a Lambda authorizer function associated with the API Gateway authenticates the incoming message. The following figure illustrates the high-level design of the solution.
Solution overview Our solution implements a verified semantic cache using the Amazon Bedrock Knowledge Bases Retrieve API to reduce hallucinations in LLM responses while simultaneously improving latency and reducing costs. The function checks the semantic cache (Amazon Bedrock Knowledge Bases) using the Retrieve API.
Customers can use the SageMaker Studio UI or APIs to specify the SageMaker Model Registry model to be shared and grant access to specific AWS accounts or to everyone in the organization. We will start by using the SageMaker Studio UI and then by using APIs.
During these live events, F1 IT engineers must triage critical issues across its services, such as network degradation to one of its APIs. This impacts downstream services that consume data from the API, including products such as F1 TV, which offer live and on-demand coverage of every race as well as real-time telemetry.
Harnessing the power of bigdata has become increasingly critical for businesses looking to gain a competitive edge. However, managing the complex infrastructure required for bigdata workloads has traditionally been a significant challenge, often requiring specialized expertise.
From our experience, artifact server has some limitations, such as limits on artifact size (because of sending it using REST API). Environment variables : Set environment variables, such as model paths, API keys, and other necessary parameters. The main parts we use are tracking the server and model registry.
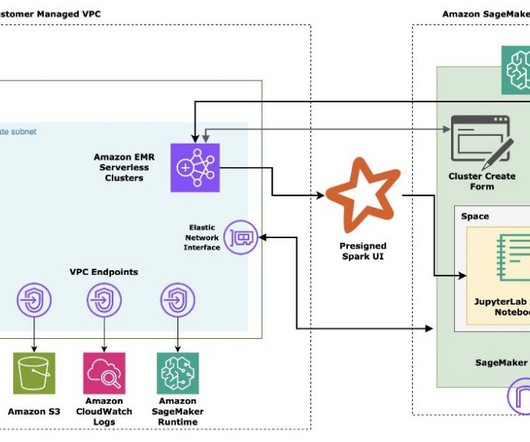
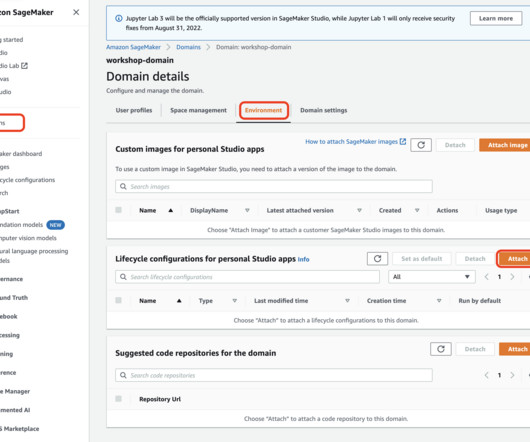
This presents an undesired threat vector for exfiltration and gaining access to customer data when proper access controls are not enforced. Studio supports a few methods for enforcing access controls against presigned URL data exfiltration: Client IP validation using the IAM policy condition aws:sourceIp. About the Authors.
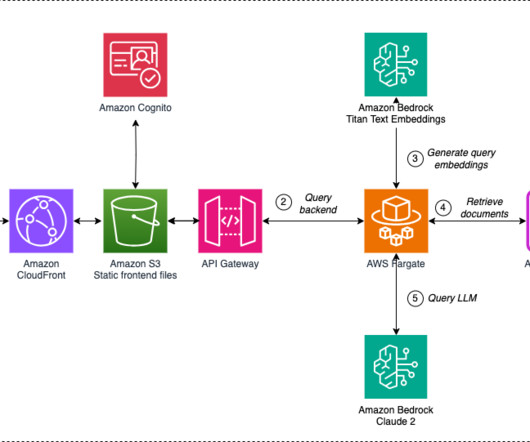
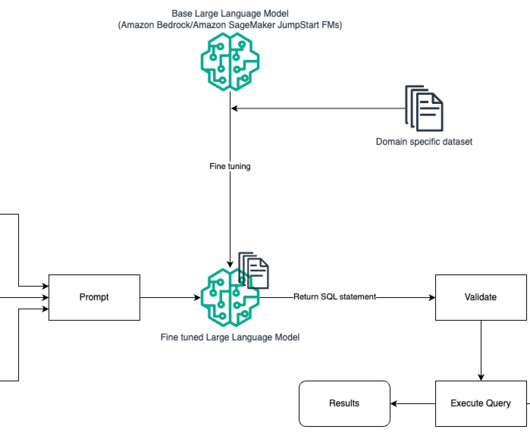
To overcome this limitation and provide dynamism and adaptability to knowledge base changes, we decided to follow a Retrieval Augmented Generation (RAG) approach, in which the LLMs are presented with relevant information extracted from external data sources to provide up-to-date data without the need to retrain the models.
We explore two ways of obtaining the same result: via JumpStart’s graphical interface on Amazon SageMaker Studio , and programmatically through JumpStart APIs. If you want to jump straight into the JumpStart API code we go through in this post, you can refer to the following sample Jupyter notebook: Introduction to JumpStart – Text to Image.
The Retrieval-Augmented Generation (RAG) framework augments prompts with external data from multiple sources, such as document repositories, databases, or APIs, to make foundation models effective for domain-specific tasks. As a Data Engineer he was involved in applying AI/ML to fraud detection and office automation.
You can now use cross-account support for Amazon SageMaker Pipelines to share pipeline entities across AWS accounts and access shared pipelines directly through Amazon SageMaker API calls. In this post, we present an example multi-account architecture for developing and deploying ML workflows with SageMaker Pipelines.
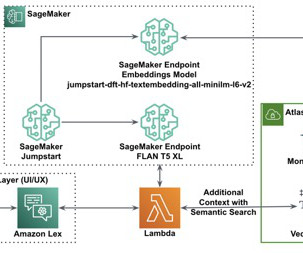
NLP SQL enables business users to analyze data and get answers by typing or speaking questions in natural language, such as the following: “Show total sales for each product last month” “Which products generated more revenue?” In entered the BigData space in 2013 and continues to explore that area. Nitin Eusebius is a Sr.
We explore two ways of obtaining the same result: via JumpStart’s graphical interface on Amazon SageMaker Studio , and programmatically through JumpStart APIs. The following sections provide a step-by-step demo to perform inference, both via the Studio UI and via JumpStart APIs. JumpStart overview. Solution overview.
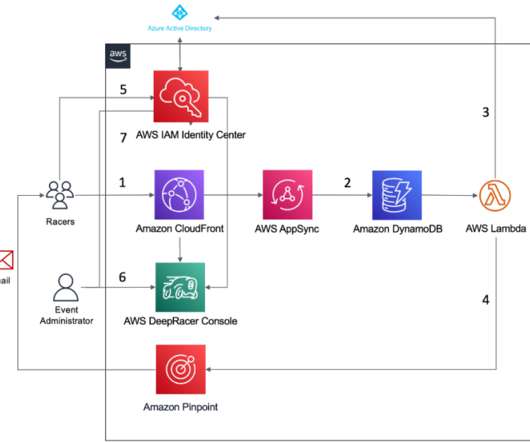
You can further personalize this page to gather additional user data (such as the user’s DeepRacer AWS profile or their level of AI and ML knowledge) or to add event marketing and training materials. The event portal registration form calls a customer API endpoint that stores email addresses in Amazon DynamoDB through AWS AppSync.
We explore two ways of obtaining the same result: via JumpStart’s graphical interface on Amazon SageMaker Studio , and programmatically through JumpStart APIs. The following sections provide a step-by-step demo to perform semantic segmentation with JumpStart, both via the Studio UI and via JumpStart APIs. Solution overview.
The absence of real-time forecasts in various industries presents pressing business challenges that can significantly impact decision-making and operational efficiency. If you need an automated workflow or direct ML model integration into apps, Canvas forecasting functions are accessible through APIs.
This year CallMiner is presenting our first annual WebinarStock, July 23rd through 25th. Creating Customer Service Super Agents with Data, Tech and Coaching featuring Forrester. This is a great opportunity to listen, watch, and learn the latest CX analytics information out there! Register for 10am BST Session.
Because the interface between agents and tools is less formally defined than an API contract, you should monitor these traces not only for performance but also to capture new error scenarios. He entered the bigdata space in 2013 and continues to explore that area.
The solution also uses SAML attribute mapping to populate the SAML assertion with specific access-relevant data, such as user ID and user team. Because the solution creates a SAML API, you can use any IdP supporting SAML assertions to create this architecture. The API Gateway calls an SAML backend API. Custom SAML 2.0
They use bigdata (such as a history of past search queries) to provide many powerful yet easy-to-use patent tools. In this section, we show how to build your own container, deploy your own GPT-2 model, and test with the SageMaker endpoint API. implement the model and the inference API. gpt2 and predictor.py
We begin by understanding the feature columns, presented in the following table. To learn more about importing data to SageMaker Canvas, see Import data into Canvas. Choose Import data , then choose Tabular. After a successful import, you will be presented with a preview of the data, which you can browse.
Training ML algorithms for pose estimation requires a lot of expertise and custom training data. Therefore, we present two options: one that doesn’t require any ML expertise and uses Amazon Rekognition, and another that uses Amazon SageMaker to train and deploy a custom ML model. We use deep learning models to solve this problem.
In the era of bigdata and AI, companies are continually seeking ways to use these technologies to gain a competitive edge. At the core of these cutting-edge solutions lies a foundation model (FM), a highly advanced machine learning model that is pre-trained on vast amounts of data.
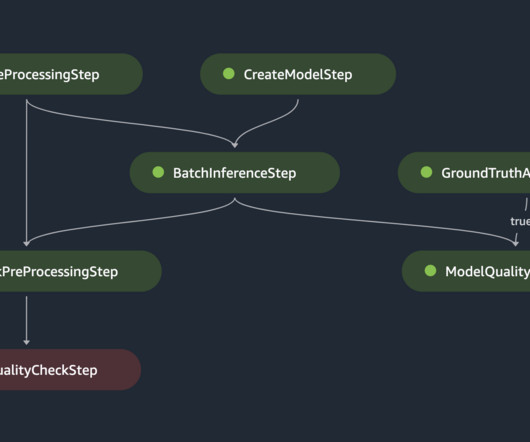
The presented MLOps workflow provides a reusable template for managing the ML lifecycle through automation, monitoring, auditability, and scalability, thereby reducing the complexities and costs of maintaining batch inference workloads in production. Manually approving or rejecting newly trained model versions in the model registry.
However, because multiple teams might use your ML platform in the cloud, monitoring large ML workloads across a scaling multi-account environment presents challenges in setting up and monitoring telemetry data that is scattered across multiple accounts. Enable CloudWatch cross-account observability.
A centralized data lake with informative data catalogs would reduce duplication efforts and enable wider sharing of creative content and consistency between teams. After ingestion, images can be searched via the Amazon Kendra search console, API, or SDK. Tanvi Singhal is a Data Scientist within AWS Professional Services.
Instead of coercing these graph datasets into tables or sequences, you can use graph ML algorithms to both represent and learn from the data as presented in its graph form, including information about constituent nodes, edges, and other features. For production, we wanted to invoke the model as a simple API call.
In terms of resulting speedups, the approximate order is programming hardware, then programming against PBA APIs, then programming in an unmanaged language such as C++, then a managed language such as Python. SIMD describes computers with multiple processing elements that perform the same operation on multiple data points simultaneously.
Data is presented to the personas that need access using a unified interface. The Step Functions state machine is configured with an AWS Lambda function to retrieve data from the Splunk index using the Splunk Enterprise SDK for Python. In this section, we present some example prompts to demonstrate this in action.
Organizations can dive deep to identify which models have missing or inactive monitors and add them using SageMaker APIs to ensure all models are being checked for data drift, model drift, bias drift, and feature attribution drift. The following screenshot shows an example of the Model dashboard.
The Data Analyst Course With the Data Analyst Course, you will be able to become a professional in this area, developing all the necessary skills to succeed in your career. The course also teaches beginner and advanced Python, basics and advanced NumPy and Pandas, and data visualization.
Open a terminal and go to the folder location where privateKey.crt is present and run the following command: keytool -import -trustcacerts -keystore /lib/security/cacerts -storepass changeit -noprompt -alias yourAliasName -file privateKey.crt Be sure to open 8443 and 80 port in your firewall settings. Now we’re ready to search our index.
Edge is a term that refers to a location, far from the cloud or a bigdata center, where you have a computer device (edge device) capable of running (edge) applications. How do I eliminate the need of installing a big framework like TensorFlow or PyTorch on my restricted device? Edge computing. About the Authors.
When that job is done, you can invoke an API that summarizes the text or answers questions about it. In entered the BigData space in 2013 and continues to explore that area. He is actively working on projects in the ML space and has presented at numerous conferences including Strata and GlueCon.
Prior to our adoption of Kubeflow on AWS, our data scientists used a standardized set of tools and a process that allowed flexibility in the technology and workflow used to train a given model. This means that user access can be controlled on the Kubeflow UI but not over the Kubernetes API via Kubectl.
Compare and evaluate experiments – The integration of Experiments with Amazon SageMaker Studio makes it easy to produce data visualizations and compare different trials. You can also access the trial data via the Python SDK to generate your own visualization using your preferred plotting libraries.
This post presents and compares options and recommended practices on how to manage Python packages and virtual environments in Amazon SageMaker Studio notebooks. A public GitHub repo provides hands-on examples for each of the presented approaches. The image is immediately available to all user profiles of the domain.
One of the main drivers for new innovations and applications in ML is the availability and amount of data along with cheaper compute options. Training job steps – An iterative process that teaches a model to make predictions by presenting examples from a training dataset.
It all starts with data: Data mesh principle AI is more than just machine learning and algorithms. AI represents a complete flow that starts with the data, which gets put in the algorithm and eventually presented to the end-user. That’s where the concept of data mesh comes into play.
Le aziende leader sotto il profilo del digitale raccolgono dati e ricavano spunti preziosi attraverso l'ausilio di modelli dati standardizzati, dell'intelligenza artificiale (IA) e dell'analisi dei bigdata. Ciò consente loro di innovare più rapidamente rispetto ai loro competitor non digitali.
For Partner Colorado, Enghouse’s use of open APIs allows integration with the in-house CRM. Instead of having to toggle back and forth between different screens and applications, agents proactively receive relevant and useful data on callers via ScreenPop. In the contact center it all comes down to interactions.
RPA, also known as software robotics, uses automation technology to build, deploy, and manage software robots that take over back-office tasks of humans such as extracting data, filling forms, etc. Interpret bigdata. Industries collect mounds and mounds of data in a single day.
Back then, Artificial Intelligence, APIs, Robotic Process Automation (RPA), and even "BigData" weren't things yet. So once they’ve identified an issue, they are presented with options consistent with your business rules and objectives [a recommendation engine built with machine learning on massive amounts of data].
In this context, the term tools refer to external capabilities or APIs that the model can access and interact with to extend its functionality beyond text-based responses. By planning, the LLM can break down a complex question into manageable steps, making sure that the right APIs are called in the correct order.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content