This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Customers can use the SageMaker Studio UI or APIs to specify the SageMaker Model Registry model to be shared and grant access to specific AWS accounts or to everyone in the organization. We will start by using the SageMaker Studio UI and then by using APIs.
Amazon SageMaker Studio provides a fully managed solution for data scientists to interactively build, train, and deploy machine learning (ML) models. Amazon SageMaker notebook jobs allow data scientists to run their notebooks on demand or on a schedule with a few clicks in SageMaker Studio.
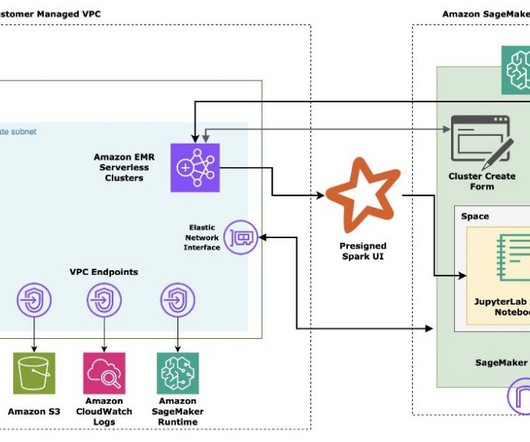
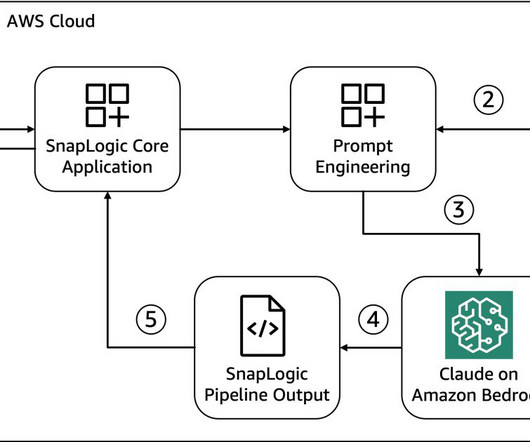
In this post, we will continue to build on top of the previous solution to demonstrate how to build a private API Gateway via Amazon API Gateway as a proxy interface to generate and access Amazon SageMaker presigned URLs. The user invokes createStudioPresignedUrl API on API Gateway along with a token in the header.
During these live events, F1 IT engineers must triage critical issues across its services, such as network degradation to one of its APIs. This impacts downstream services that consume data from the API, including products such as F1 TV, which offer live and on-demand coverage of every race as well as real-time telemetry.
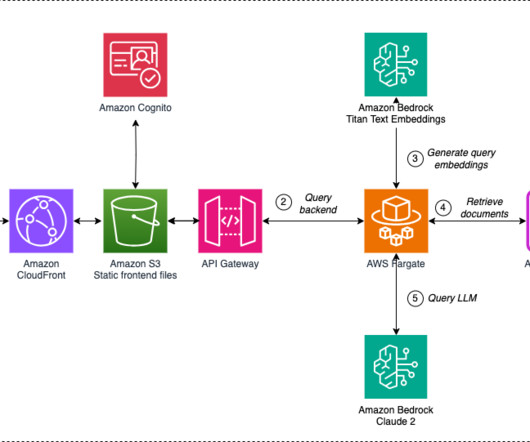
While these models are trained on vast amounts of generic data, they often lack the organization-specific context and up-to-date information needed for accurate responses in business settings. The function checks the semantic cache (Amazon Bedrock Knowledge Bases) using the Retrieve API.
They provide access to external data and APIs or enable specific actions and computation. To improve accuracy, we tested model fine-tuning, training the model on common queries and context (such as database schemas and their definitions). Before joining RDC, he served as a Lead Data Scientist at KPMG, advising clients globally.
Harnessing the power of bigdata has become increasingly critical for businesses looking to gain a competitive edge. However, managing the complex infrastructure required for bigdata workloads has traditionally been a significant challenge, often requiring specialized expertise.
Training ML algorithms for pose estimation requires a lot of expertise and custom trainingdata. Therefore, we present two options: one that doesn’t require any ML expertise and uses Amazon Rekognition, and another that uses Amazon SageMaker to train and deploy a custom ML model.
It’s a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like Anthropic, Cohere, Meta, Mistral AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
An example direct acyclic graph (DAG) might automate data ingestion, processing, model training, and deployment tasks, ensuring that each step is run in the correct order and at the right time. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly.
This platform removes the common barriers to adopting best-in-class computer vision technologies, as organizations can train their own customized computer vision models through the VI Studio and deploy practical automation using these models across TechSee’s suite of visual service products. cial intelligence and bigdata.
JumpStart provides one-click fine-tuning and deployment of a wide variety of pre-trained models across popular ML tasks, as well as a selection of end-to-end solutions that solve common business problems. In this post, we provide a step-by-step walkthrough on how to deploy pre-trained stable diffusion models for generating images from text.
JumpStart provides one-click fine-tuning and deployment of a wide variety of pre-trained models across popular ML tasks, as well as a selection of end-to-end solutions that solve common business problems. In this post, we provide a step-by-step walkthrough on how to deploy pre-trained text generation models.
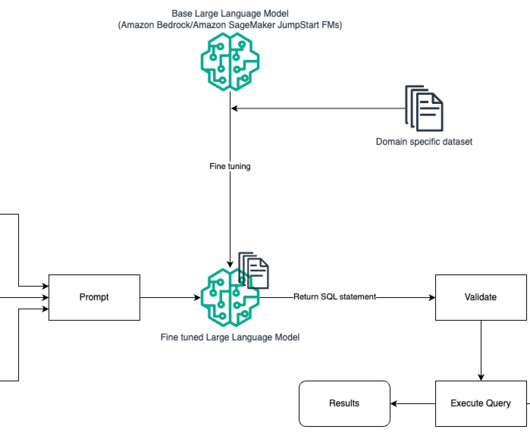
NLP SQL enables business users to analyze data and get answers by typing or speaking questions in natural language, such as the following: “Show total sales for each product last month” “Which products generated more revenue?” Fine-tuning directly trains the model on the end task but requires many text-SQL examples.
An approach to product stewardship with generative AI Large language models (LLMs) are trained with vast amounts of information crawled from the internet, capturing considerable knowledge from multiple domains. However, their knowledge is static and tied to the data used during the pre-training phase.
The Retrieve and RetrieveAndGenerate APIs allow your applications to directly query the index using a unified and standard syntax without having to learn separate APIs for each different vector database, reducing the need to write custom index queries against your vector store.
Generative AI models have the potential to revolutionize enterprise operations, but businesses must carefully consider how to harness their power while overcoming challenges such as safeguarding data and ensuring the quality of AI-generated content. Amazon SageMaker enables enterprises to build, train, and deploy machine learning (ML) models.
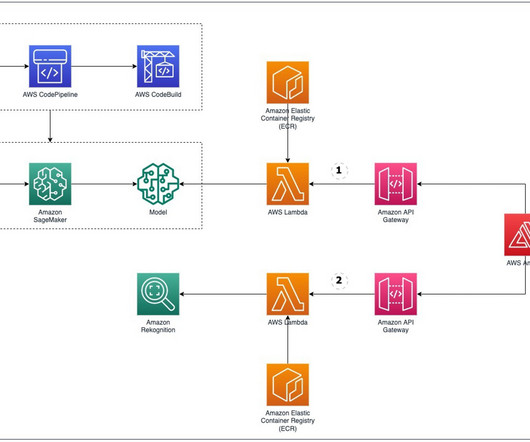
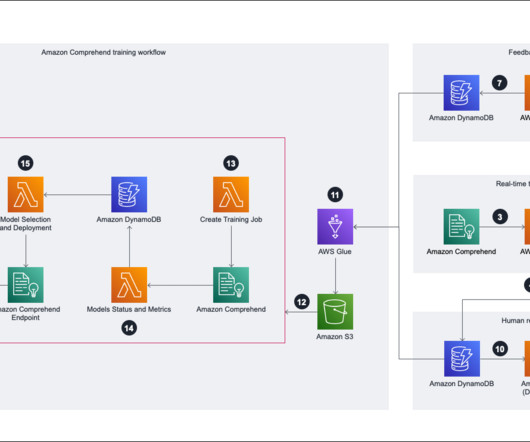
Amazon Comprehend is a fully managed and continuously trained natural language processing (NLP) service that can extract insight about the content of a document or text. accuracy by training on 800 data points and testing on 300 data points. API Gateway bypasses the request to Lambda.
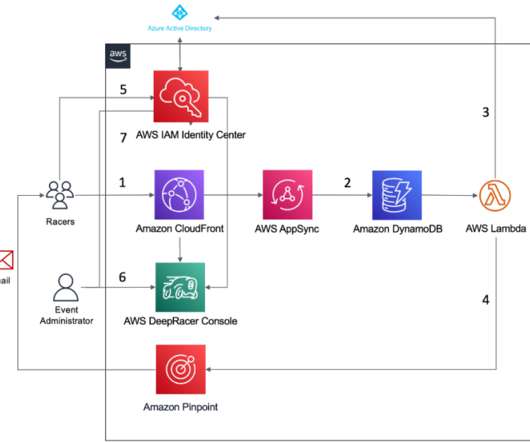
This requires more accessible ML training, speaking to a larger number of people with diverse backgrounds. You can get started with RL quickly with hands-on tutorials that guide you through the basics of training RL models and testing them in an exciting, autonomous car racing experience. “We
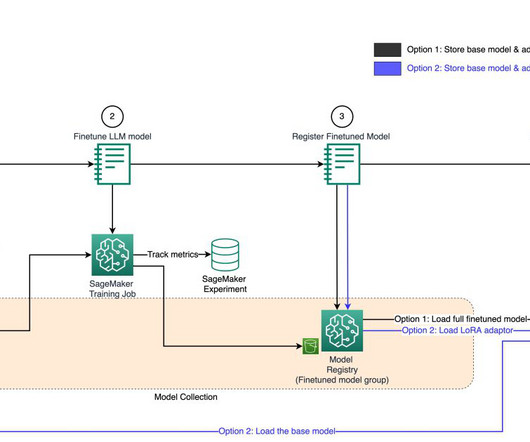
In a previous post , we discussed MLflow and how it can run on AWS and be integrated with SageMaker—in particular, when tracking training jobs as experiments and deploying a model registered in MLflow to the SageMaker managed infrastructure. How to use MLflow as a centralized repository in a multi-account setup.
Although this example shows how to perform this for inference operations, you can extend the solution to training and other ML steps. Endpoints are deployed with a couple clicks or lines of code using SageMaker, which simplifies the process for developers and ML experts to build and train ML and deep learning models in the cloud.
The phases we discuss in this post use the following key services: Amazon Comprehend Medical is a HIPAA-eligible natural language processing (NLP) service that uses machine learning (ML) models that have been pre-trained to understand and extract health data from medical text, such as prescriptions, procedures, or diagnoses.
JumpStart provides one-click fine-tuning and deployment of a wide variety of pre-trained models across popular ML tasks, as well as a selection of end-to-end solutions that solve common business problems. Fine-tune pre-trained models – JumpStart allows you to fine-tune pre-trained models with no need to write your own training algorithm.
You simply provide images with the appropriate labels, train the model, and deploy without having to build the model and fine-tune it. In this post, we show how to label, train, and build a computer vision model to detect rooftops and solar panels from satellite images. Use Amazon Rekognition to train the model with custom labels.
In the era of bigdata and AI, companies are continually seeking ways to use these technologies to gain a competitive edge. At the core of these cutting-edge solutions lies a foundation model (FM), a highly advanced machine learning model that is pre-trained on vast amounts of data.
As feature data grows in size and complexity, data scientists need to be able to efficiently query these feature stores to extract datasets for experimentation, model training, and batch scoring. The offline store is primarily used for batch predictions and model training.
You can now use cross-account support for Amazon SageMaker Pipelines to share pipeline entities across AWS accounts and access shared pipelines directly through Amazon SageMaker API calls. The data scientist is now able to describe and monitor the test pipeline run status using SageMaker API calls from the dev account.
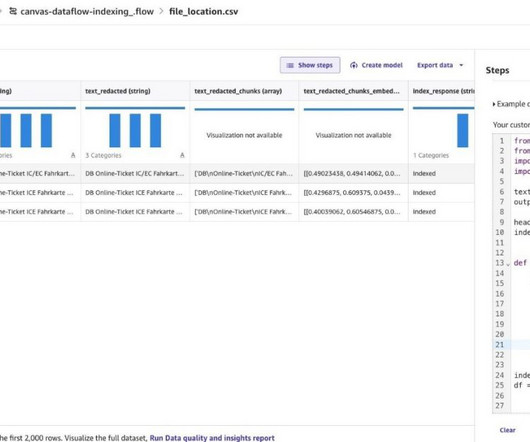
We also detail the steps that data scientists can take to configure the data flow, analyze the data quality, and add data transformations. Finally, we show how to export the data flow and train a model using SageMaker Autopilot. Configure Snowflake. Configure SageMaker Studio.
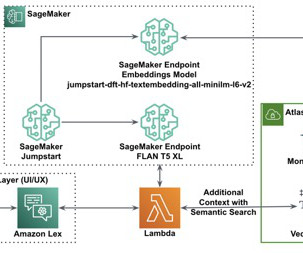
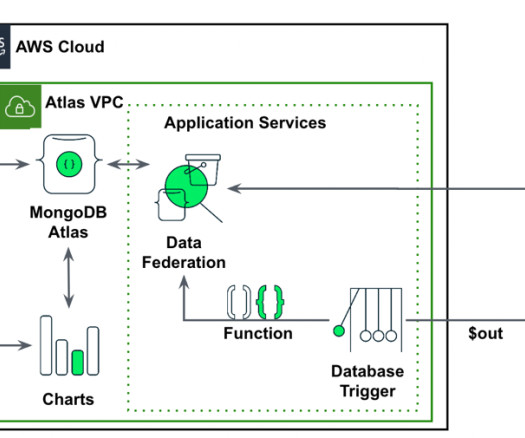
The SageMaker Canvas UI lets you seamlessly integrate data sources from the cloud or on-premises, merge datasets effortlessly, train precise models, and make predictions with emerging data—all without coding. Solution overview Users persist their transactional time series data in MongoDB Atlas. Note we have two folders.
It stores history of ML features in the offline store (Amazon S3) and also provides APIs to an online store to allow low-latency reads of most recent features. SageMaker lets you train and upload ML models and host them by creating and configuring SageMaker endpoints. Data Engineer for Amp on Amazon. Real-time inference.
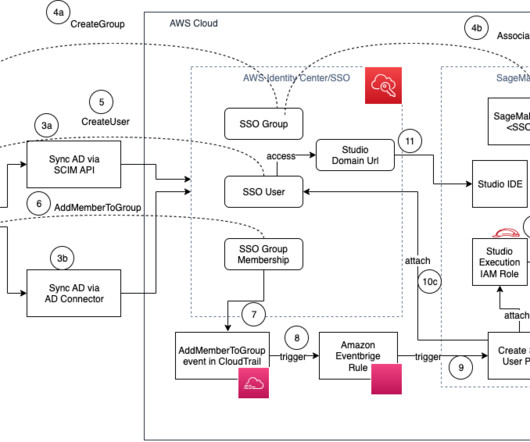
Amazon SageMaker Studio is a web-based integrated development environment (IDE) for machine learning (ML) that lets you build, train, debug, deploy, and monitor your ML models. When the AD user is assigned to an AD group, an IAM Identity Center API ( CreateGroupMembership ) is invoked, and SSO group membership is created.
In addition, features such as predictor retraining can reduce training time and cost by up to 50%. By separating popular from unpopular items and training predictors, we found that predictors can fit the dataset better and enhance model accuracy with different statistical distributions. Solution overview. Summary and next steps.
Pre-trained models and fully managed NLP services have democratised access and adoption of NLP. Amazon Comprehend is a fully managed service that can perform NLP tasks like custom entity recognition, topic modelling, sentiment analysis and more to extract insights from data without the need of any prior ML experience.
As enterprise businesses embrace machine learning (ML) across their organizations, manual workflows for building, training, and deploying ML models tend to become bottlenecks to innovation. Initial phase: During this phase, the data scientists are able to experiment and build, train, and deploy models on AWS using SageMaker services.
As shown in the preceding figure, the ML paradigm is learning (training) followed by inference. In this example figure, features are extracted from raw historical data, which are then are fed into a neural network (NN). Secondly, there was a massive increase in the volume of labeled data available for training.
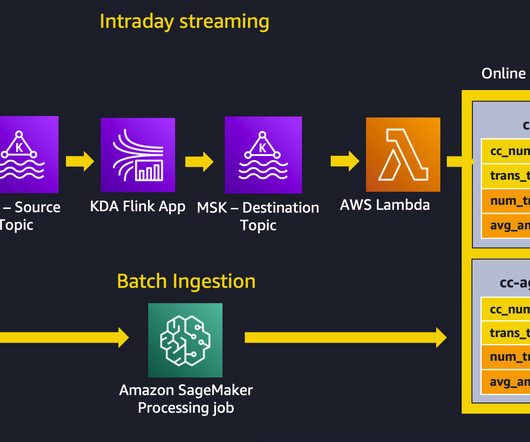
Feature Store lets you define groups of features, use batch ingestion and streaming ingestion, retrieve the latest feature values with single-digit millisecond latency for highly accurate online predictions, and extract point-in-time correct datasets for training. Model training and deployment – This aspect of our solution is straightforward.
Then we train, build, test, and deploy the model using SageMaker Canvas, without writing any code. Solution overview SageMaker Canvas brings together a broad set of capabilities to help data professionals prepare, build, train, and deploy ML models without writing any code. For Training method , select Auto.
Yaoqi Zhang is a Senior BigData Engineer at Mission Cloud. Adrian Martin is a BigData/Machine Learning Lead Engineer at Mission Cloud. Her current areas of interest include federated learning, distributed training, and generative AI. He has extensive experience in English/Spanish interpretation and translation.
However, these models require massive amounts of clean, structured trainingdata to reach their full potential. Most real-world data exists in unstructured formats like PDFs, which requires preprocessing before it can be used effectively. According to IDC , unstructured data accounts for over 80% of all business data today.
This emergent ability in LLMs has compelled software developers to use LLMs as an automation and UX enhancement tool that transforms natural language to a domain-specific language (DSL): system instructions, API requests, code artifacts, and more.
SageMaker Python SDK is used to create or update SageMaker pipelines for training, training with hyperparameter optimization (HPO), and batch inference. SageMaker Pipelines serves as the orchestrator for ML model training and inference workflows.
Model cards enable you to standardize how models are documented, thereby achieving visibility into the lifecycle of a model, from designing, building, training, and evaluation. Auto-populate Model cards for SageMaker trained models. Upload and share model and data evaluation results. SageMaker Model Cards.
Capacity We can think about capacity in two contexts: inference and training model data pipelines. Because the interface between agents and tools is less formally defined than an API contract, you should monitor these traces not only for performance but also to capture new error scenarios.
Amazon SageMaker Studio is a web-based integrated development environment (IDE) for machine learning (ML) that lets you build, train, debug, deploy, and monitor your ML models. The solution also uses SAML attribute mapping to populate the SAML assertion with specific access-relevant data, such as user ID and user team. Custom SAML 2.0
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content