This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This blog post is co-written with Renuka Kumar and Thomas Matthew from Cisco. Additionally, if temporary tables or views are used for the data domain, a SQL script is required that, when executed, creates the desired temporary data structures needs to be defined. A domain-specific user prompt.
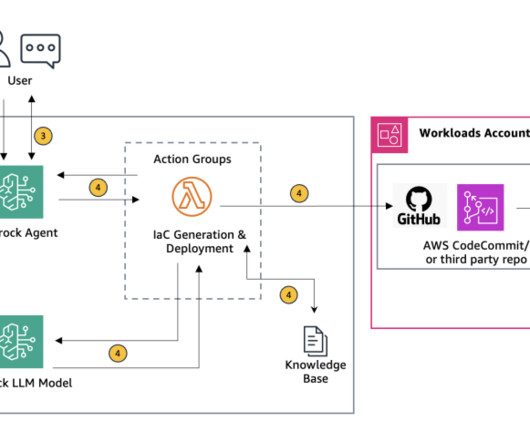
This solution uses Retrieval Augmented Generation (RAG) to ensure the generated scripts adhere to organizational needs and industry standards. In this blog post, we explore how Agents for Amazon Bedrock can be used to generate customized, organization standards-compliant IaC scripts directly from uploaded architecture diagrams.
Ask about: Compatibility with your EHR Secure API integration or SFTP data exchange Real-time appointment syncing and status updates Step 6: Review Call Center Staff Training and Specialization Healthcare calls require knowledgeable and empathetic agents. A signed BAA is standard. A: Not necessarily.
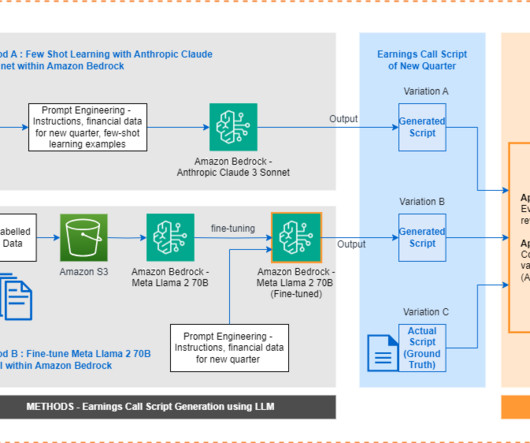
This blog is part of the series, Generative AI and AI/ML in Capital Markets and Financial Services. Traditionally, earnings call scripts have followed similar templates, making it a repeatable task to generate them from scratch each time. Model customization helps you deliver differentiated and personalized user experiences.
In particular, we cover the SMP library’s new simplified user experience that builds on open source PyTorch Fully Sharded Data Parallel (FSDP) APIs, expanded tensor parallel functionality that enables training models with hundreds of billions of parameters, and performance optimizations that reduce model training time and cost by up to 20%.
Customizable Scripts and Call Flows No two practices are alike. The right medical call center will offer customizable scripting and call flow options that align with your office procedures, from intake protocols to escalation processes. This ensures your patients feel understood and respected.
Refer to Getting started with the API to set up your environment to make Amazon Bedrock requests through the AWS API. Test the code using the native inference API for Anthropics Claude The following code uses the native inference API to send a text message to Anthropics Claude. client = boto3.client("bedrock-runtime",
This blog post is co-written with Gene Arnold from Alation. We recommend running similar scripts only on your own data sources after consulting with the team who manages them, or be sure to follow the terms of service for the sources that youre trying to fetch data from. First, you would need build connectors to the data sources.
In this blog post and open source project , we show you how you can pre-train a genomics language model, HyenaDNA , using your genomic data in the AWS Cloud. Solution overview In this blog post we address pre-training a genomic language model on an assembled genome. Then we deploy that model as a SageMaker real-time inference endpoint.
Our latest product innovation, Transaction Risk API , was officially launched a couple of weeks ago at Merchant Risk Council (MRC) 2019. In this three part blog series we will cover why we built it, how we built it, and what value it brings to the market. Introducing our Transaction Risk API. The new era or “Fraud 3.0”
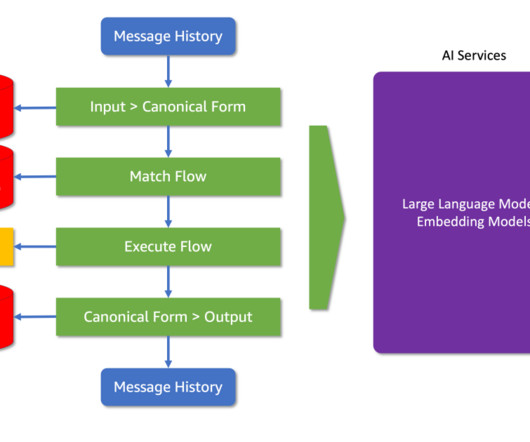
In this blog post, we explore a real-world scenario where a fictional retail store, AnyCompany Pet Supplies, leverages LLMs to enhance their customer experience. Lets delve into a basic Colang script to see how it works: define user express greeting "hello" "hi" "what's up?" model API exposed by SageMaker JumpStart properly.
Vonage API Account. To complete this tutorial, you will need a Vonage API account. Once you have an account, you can find your API Key and API Secret at the top of the Vonage API Dashboard. Web Component polyfill --> <script src="[link]. <!-- This tutorial also uses a virtual phone number.
And thus I thought it’d be fun to design and build something with Nexmo’s Voice and SMS APIs to do just that. Replace the API Key, API Secret, App ID, and your Nexmo Number. The post How to Create an Interactive Scavenger Hunt with Nexmo’s SMS and Voice API appeared first on Nexmo Developer Blog.
Users can also interact with data with ODBC, JDBC, or the Amazon Redshift Data API. In this blog post, we will show you how to use both of these services together to efficiently perform analysis on massive data sets in the cloud while addressing the challenges mentioned above. Solution overview.
In this blog post, we show how we optimized torch.compile performance on AWS Graviton3-based EC2 instances, how to use the optimizations to improve inference performance, and the resulting speedups. We benchmarked 45 models using the scripts from the TorchBench repo. Save the following script as google_t5_small_text_translation.py.
We explore two ways of obtaining the same result: via JumpStart’s graphical interface on Amazon SageMaker Studio , and programmatically through JumpStart APIs. If you want to jump straight into the JumpStart API code we go through in this post, you can refer to the following sample Jupyter notebook: Introduction to JumpStart – Text to Image.
AI Makes It Possible (Blog Series). Blog #4 of 4 The MORE you know. Key Learnings from Kate Leggett and Steve Nattress. The more YOU KNOW. . How AI-Enabled Super-Agents Improve CX. Treat Automation like a member of your staff with assigned KPIs, reviews and ongoing re-training.
This is a guest blog post co-written with Hussain Jagirdar from Games24x7. The code to invoke the pipeline script is available in the Studio notebooks, and we can change the hyperparameters and input/output when invoking the pipeline. This helps in validating if our custom scripts will run on SageMaker instances.
We explore two ways of obtaining the same result: via JumpStart’s graphical interface on Amazon SageMaker Studio , and programmatically through JumpStart APIs. Review training videos and blogs – JumpStart also provides numerous blog posts and videos that teach you how to use different functionalities within SageMaker.
The retrieve_and_generate API does both the retrieval and a call to an FM (Amazon Titan or Anthropic’s Claude family of models on Amazon Bedrock ), for a fully managed solution. An additional FM call, potentially with another model, can be used to assess the response instead of using the more rigid approach of the Python script.
We’re proud to announce that we’ve “officially” launched our Agent Scripting for call centers. Also, we’d love to get in touch if you write a blog or enjoy writing about customer service, call center technology, or awesome new companies in our industry. And you know what that means? Press release time !
The Slack application sends the event to Amazon API Gateway , which is used in the event subscription. API Gateway forwards the event to an AWS Lambda function. We will cover this in a later blog post. In the following sections, we guide you through the process of setting up a Slack integration for Amazon Bedrock.
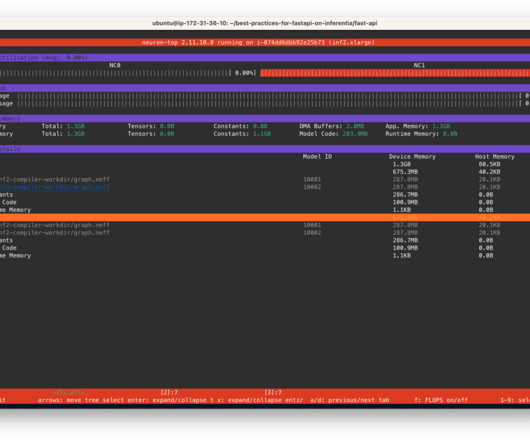
If the model changes on the server side, the client has to know and change its API call to the new endpoint accordingly. We demonstrate the use of Neuron Top at the end of this blog. Clone the Github repository The GitHub repo provides all the scripts necessary to deploy models using FastAPI on NeuronCores on AWS Inferentia instances.
You need to complete three steps to deploy your model: Create a SageMaker model: This will contain, among other parameters, the information about the model file location, the container that will be used for the deployment, and the location of the inference script. (If The inference script URI is needed in the INFERENCE_SCRIPT_S3_LOCATION.
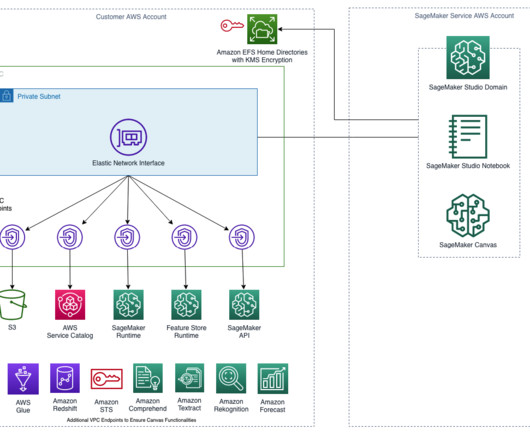
You must also associate a security group for your VPC with these endpoints to allow all inbound traffic from port 443: SageMaker API: com.amazonaws.region.sagemaker.api. This is required to communicate with the SageMaker API. Solution walkthrough In this blog post, we demonstrate how to deploy the Terraform solution.
In this post, we provide an overview of how to deploy and run inference with the Stable Diffusion upscaler model in two ways: via JumpStart’s user interface (UI) in Amazon SageMaker Studio , and programmatically through JumpStart APIs available in the SageMaker Python SDK.
We talk about Zapier a lot on our blog because it makes automation of business tasks so simple; you can even use it for free with the most basic plan. Using The VirtualPBX API to Assist. You can also manage your hooks outside of the VirtualPBX web interface by taking advantage of our API. Combining SMS, Webhooks, and Zapier.
We explore two ways of obtaining the same result: via JumpStart’s graphical interface on Amazon SageMaker Studio , and programmatically through JumpStart APIs. Review training videos and blogs – JumpStart also provides numerous blog posts and videos that teach you how to use different functionalities within SageMaker.
Continuous integration and continuous delivery (CI/CD) pipeline – Using the customer’s GitHub repository enabled code versioning and automated scripts to launch pipeline deployment whenever new versions of the code are committed. Wipro has used the input filter and join functionality of SageMaker batch transformation API.
Amazon API Gateway with AWS Lambda integration that converts the input text to the target language using the Amazon Translate SDK. The following steps set up API Gateway, Lambda, and Amazon Translate resources using the AWS CDK. Take note of the API key and the API endpoint created during the deployment. Prerequisites.
And testingRTC offers multiple ways to export these metrics, from direct collection from webhooks, to downloading results in CSV format using the REST API. Flip the script With testingRTC, you only need to write scripts once, you can then run them multiple times and scale them up or down as you see fit. Happy days!
Amazon API Gateway hosts a REST API with various endpoints to handle user requests that are authenticated using Amazon Cognito. Finally, the response is sent back to the user via a HTTPs request through the Amazon API Gateway REST API integration response. The web application front-end is hosted on AWS Amplify.
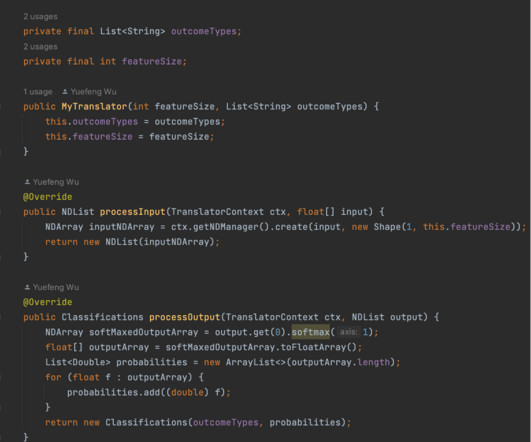
Steps to fine tune embedding models on Amazon SageMaker In the following sections, we use a SageMaker JupyterLab to walk through the steps of data preparation, creating a training script, training the model, and deploying it as a SageMaker endpoint. Python script that serves as the entry point. expand(token_embeddings.size()).float()
Therefore, users without ML expertise can enjoy the benefits of a custom labels model through an API call, because a significant amount of overhead is reduced. A Python script is used to aid in the process of uploading the datasets and generating the manifest file. then((response) => { resolve(Buffer.from(response.data, "binary").toString("base64"));
Creates an API Gateway that adds an additional layer of security between the web app user interface and Lambda. Wait until the script provisions all the required resources and finishes running. Copy the API Gateway URL that the AWS CDK script prints out and save it. (We The S3 path to the movie node file.
Recently, we also announced the launch of easy-to-use JumpStart APIs as an extension of the SageMaker Python SDK, allowing you to programmatically deploy and fine-tune a vast selection of JumpStart-supported pre-trained models on your own datasets. JumpStart overview. The dataset has been downloaded from TensorFlow. Walkthrough overview.
In this blog post, we’ll first take a closer look at the key differentiators of sharded data parallelism and when to use it. To get started, follow Modify a PyTorch Training Script to adapt SMPs’ APIs in your training script. The notebook uses the script data_prep_512.py return loss. Prepare the dataset.
Our data scientists train the model in Python using tools like PyTorch and save the model as PyTorch scripts. Ideally, we instead want to load the model PyTorch scripts, extract the features from model input, and run model inference entirely in Java. However, a few issues came with this solution.
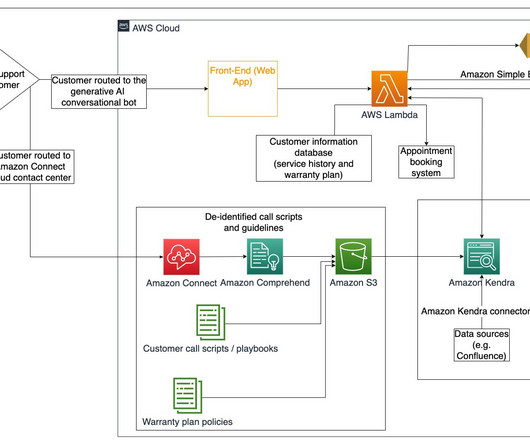
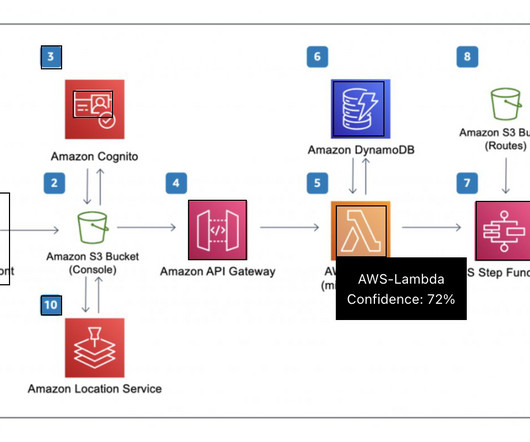
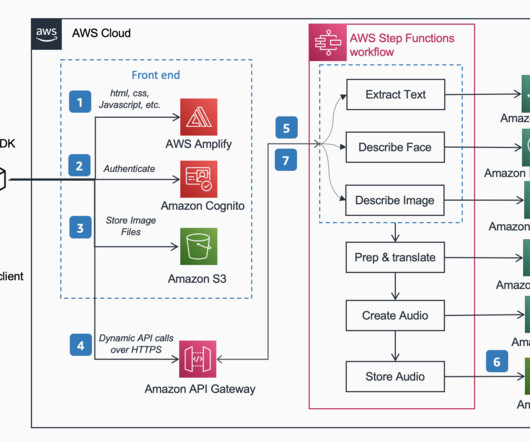
In this blog post we walk you through the Solution Architecture behind “Describe For Me”, and the design considerations of our solution. The DescribeForMe web app invokes the backend AI services by sending the Amazon S3 object Key in the payload to Amazon API Gateway Amazon API Gateway instantiates an AWS Step Functions workflow.
This blog post is co-written with Marat Adayev and Dmitrii Evstiukhin from Provectus. The ML components for data ingestion, preprocessing, and model training were available as disjointed Python scripts and notebooks, which required a lot of manual heavy lifting on the part of engineers.
We implement the RAG functionality inside an AWS Lambda function with Amazon API Gateway to handle routing all requests to the Lambda. We implement a chatbot application in Streamlit which invokes the function via the API Gateway and the function does a similarity search in the OpenSearch Service index for the embeddings of user question.
This blog post demonstrates how to perform ML inference using an object detection model from the PyTorch Model Zoo within SageMaker. Setting up these ML models as a SageMaker endpoint or SageMaker Batch Transform job for online or offline inference is easy with the steps outlined in this blog post. Solution overview. Step 1: Setup.
In this post, we provide an overview of how to fine-tune the Stable Diffusion model in two ways: programmatically through JumpStart APIs available in the SageMaker Python SDK , and JumpStart’s user interface (UI) in Amazon SageMaker Studio. Fine-tuning large models like Stable Diffusion usually requires you to provide training scripts.
A Vonage APIs (formerly Nexmo) account. Express web service, using the Vonage Voice API to answer the call and return a Nexmo Call Control Object (NCCO) telling the API to use text-to-speech to speak a phrase and then wait for user input via the phone keypad. Vonage APIs Setup. An ngrok account. A Heroku account.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content