This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The GenASL web app invokes the backend services by sending the S3 object key in the payload to an API hosted on Amazon API Gateway. API Gateway instantiates an AWS Step Functions The state machine orchestrates the AI/ML services Amazon Transcribe and Amazon Bedrock and the NoSQL data store Amazon DynamoDB using AWS Lambda functions.
Be mindful that LLM token probabilities are generally overconfident without calibration. TensorRT-LLM requires models to be compiled into efficient engines before deployment. Before introducing this API, the KV cache was recomputed for any newly added requests. For more details, refer to the GitHub repo.
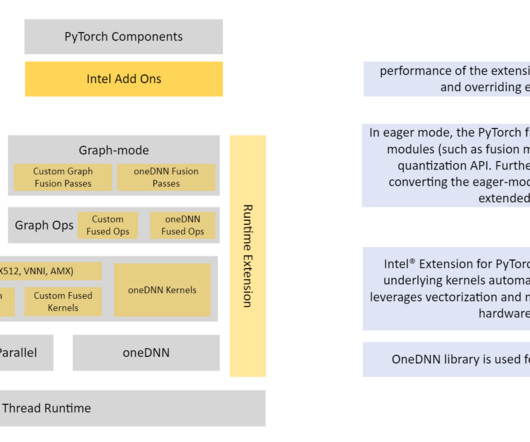
Import intel extensions for PyTorch to help with quantization and optimization and import torch for array manipulations: import intel_extension_for_pytorch as ipex import torch Apply model calibration for 100 iterations. Quantizing the model in PyTorch is possible with a few APIs from Intel PyTorch extensions.
Based on 10 years of historical data, hundreds of thousands of face-offs were used to engineer over 70 features fed into the model to provide real-time probabilities. By continuously listening to NHL’s expertise and testing hypotheses, AWS’s scientists engineered over 100 features that correlate to the face-off event.
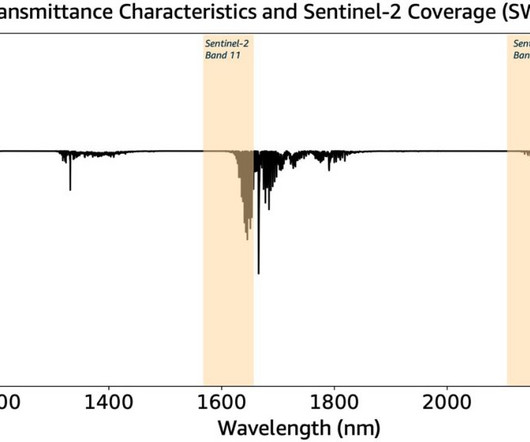
Amazon SageMaker geospatial capabilities make it easier for data scientists and machine learning engineers to build, train, and deploy models using geospatial data. fractional change in reflectance yields good results but this can change from scene to scene and you will have to calibrate this for your specific use case.
Leveraging Call Center Insights for Continuous Improvement Transforming raw call center data into strategic action creates a powerful engine for organizational growth. Call center managers should implement regular calibration sessions where teams review sample interactions to ensure consistent evaluation standards.
To demonstrate how you can use this solution in your existing business infrastructures, we also include an example of making REST API calls to the deployed model endpoint, using AWS Lambda to trigger both the RCF and XGBoost models. This adds a useful calibration to our model. Prerequisites. Launch the solution.
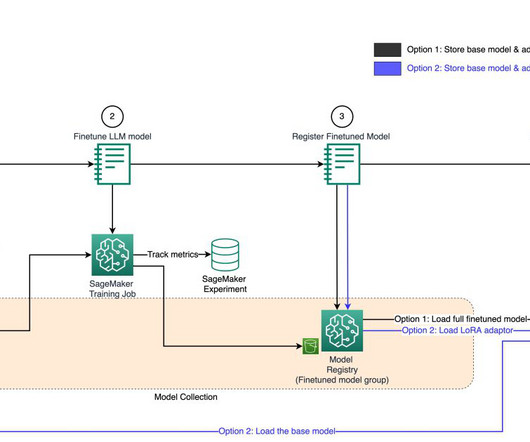
Additionally, optimizing the training process and calibrating the parameters can be a complex and iterative process, requiring expertise and careful experimentation. During fine-tuning, we integrate SageMaker Experiments Plus with the Transformers API to automatically log metrics like gradient, loss, etc.
Better still, you can monitor the script on a daily basis to identify places for change and calibrate your voice. Seamlessly integrate proprietary or third-party CRM applications with our extensive APIs and data dictionary libraries. Remember that designing and using a call script is a daunting process that yields excellent results.
The fact that you can submit a request with JustCall engineers to expand this library of integrations is a cherry on the cake! Not to forget that those having Premium and Custom plans can request API and Webhook access to do it at their will! JuctCall alternatives don’t come close.
Some of these include: AdaAgent Assist, Airkit Assist, Hub Auto, Reach, Balto, Calabrio, PCI Pan Digital Agent Assist, Pypestream, Verint, Zingtree, Talkdesk also offers API access for all plans. When trained and calibrated correctly, the virtual agent can seamlessly guide callers to the correct resolution through self-servicing.
In short, AI is the best decision engine of the intelligent automation platform. It uses API (Application Programming Interface) and user interface interaction to perform repetitive tasks, saving resources and ridding human workers from mundane tasks. AI can learn from its past experiences and formulates predictions based on data.
When processing large-scale data, data scientists and ML engineers often use PySpark , an interface for Apache Spark in Python. SageMaker provides prebuilt Docker images that include PySpark and other dependencies needed to run distributed data processing jobs, including data transformations and feature engineering using the Spark framework.
Founded in 2013 as a search engine for GIFs, Giphy soon expanded to tools that enabled millions of internet users to seamlessly embed the short animations on sites like Facebook and Twitter , helping to make “reaction GIFs” a core medium for digital expression.
Evaluating these models allows continuous model improvement, calibration and debugging. Once in production, ML consumers utilize the model via application-triggered inference through direct invocation or API calls, with feedback loops to model owners for ongoing performance evaluation. html") s3_object = s3.Object(bucket_name=output_bucket,
Theres a risk of reverse engineering or data leakage if not properly implemented. Use the Amazon Bedrock API to generate Python code based on your prompts. The quality of synthetic data heavily depends on the model and data used to generate it. Privacy vs. utility Balancing privacy preservation with data utility is complex.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content