This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The GenASL web app invokes the backend services by sending the S3 object key in the payload to an API hosted on Amazon API Gateway. API Gateway instantiates an AWS Step Functions The state machine orchestrates the AI/ML services Amazon Transcribe and Amazon Bedrock and the NoSQL data store Amazon DynamoDB using AWS Lambda functions.
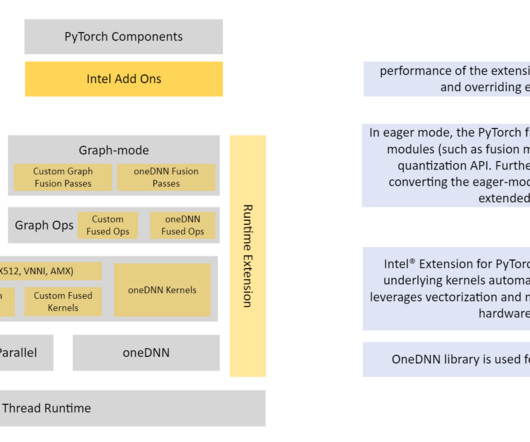
Import intel extensions for PyTorch to help with quantization and optimization and import torch for array manipulations: import intel_extension_for_pytorch as ipex import torch Apply model calibration for 100 iterations. Quantizing the model in PyTorch is possible with a few APIs from Intel PyTorch extensions. Refer to invoke-INT8.py
To demonstrate how you can use this solution in your existing business infrastructures, we also include an example of making REST API calls to the deployed model endpoint, using AWS Lambda to trigger both the RCF and XGBoost models. Lastly, we compare the classification result with the ground truth labels and compute the evaluation metrics.
AV/ADAS teams need to label several thousand frames from scratch, and rely on techniques like label consolidation, automatic calibration, frame selection, frame sequence interpolation, and active learning to get a single labeled dataset. Ground Truth supports these features. First, we download and prepare the date for inference.
Its not just about tracking basic metrics anymoreits about gaining comprehensive insights that drive strategic decisions. Key Metrics for Measuring Success Tracking the right performance indicators separates thriving call centers from struggling operations. This metric transforms support from cost center to growth driver.
Be mindful that LLM token probabilities are generally overconfident without calibration. Before introducing this API, the KV cache was recomputed for any newly added requests. Be mindful that LLM token probabilities are generally overconfident without calibration.
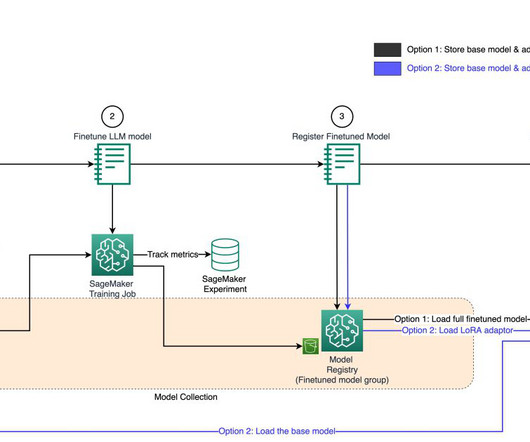
Additionally, optimizing the training process and calibrating the parameters can be a complex and iterative process, requiring expertise and careful experimentation. During fine-tuning, we integrate SageMaker Experiments Plus with the Transformers API to automatically log metrics like gradient, loss, etc.
The decision tree provided the cut-offs for each metric, which we included as rules-based logic in the streaming application. At the end, we found that the LightGBM model worked best with well-calibrated accuracy metrics. To evaluate the performance of the models, we used multiple techniques.
Giphy’s tools are already integrated with many Facebook competitors, including Twitter, Snapchat, Slack, Reddit, TikTok and Bumble , and both companies have said that Giphy’s outside partners will continue to have the same access to its library and API. The collection is priced at $349.
SageMaker Processing jobs allow you to specify the private subnets and security groups in your VPC as well as enable network isolation and inter-container traffic encryption using the NetworkConfig.VpcConfig request parameter of the CreateProcessingJob API. We provide examples of this configuration using the SageMaker SDK in the next section.
Furthermore, these data and metrics must be collected to comply with upcoming regulations. They need evaluation metrics generated by model providers to select the right pre-trained model as a starting point. Evaluating these models allows continuous model improvement, calibration and debugging.
The first post focused on selecting appropriate use cases, preparing data, and implementing metrics to support a human-in-the-loop evaluation process. In this section, we discuss key metrics that need to be included for a RAG generative AI solution. Its crucial to identify which aspects of the solution need evaluation.
Use the Amazon Bedrock API to generate Python code based on your prompts. It works by injecting calibrated noise into the data generation process, making it virtually impossible to infer anything about a single data point or confidential information in the source dataset.
We use the following AWS services: Amazon Bedrock to invoke LLMs AWS Identity and Access Management (IAM) for permission control across various AWS services Amazon SageMaker to host Jupyter notebooks and invoke the Amazon Bedrock API In the following sections, we demonstrate how to use the GitHub repository to run all of the techniques in this post.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content