This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
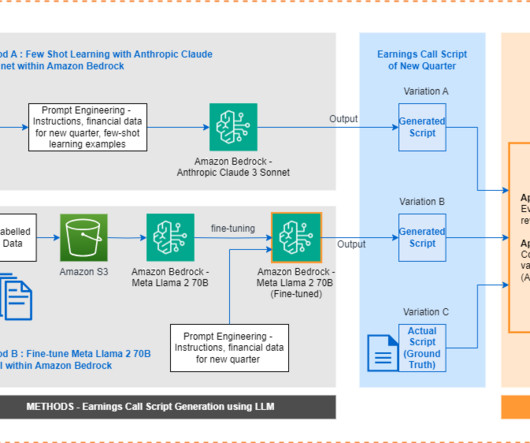
Earnings calls are live conferences where executives present an overview of results, discuss achievements and challenges, and provide guidance for upcoming periods. Traditionally, earnings call scripts have followed similar templates, making it a repeatable task to generate them from scratch each time.
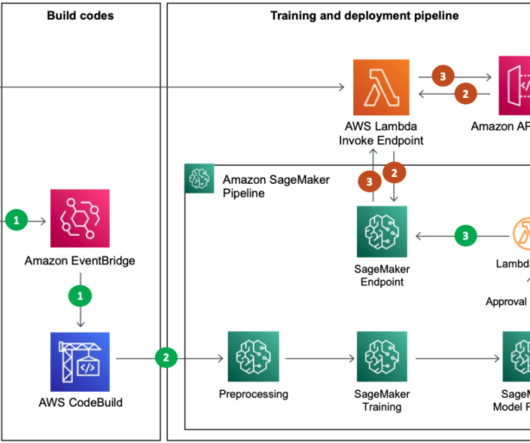
The main AWS services used are SageMaker, Amazon EMR , AWS CodeBuild , Amazon Simple Storage Service (Amazon S3), Amazon EventBridge , AWS Lambda , and Amazon API Gateway. Real-time recommendation inference The inference phase consists of the following steps: The client application makes an inference request to the API gateway.
Here are some features which we will cover: AWS CloudFormation support Private network policies for Amazon OpenSearch Serverless Multiple S3 buckets as data sources Service Quotas support Hybrid search, metadata filters, custom prompts for the RetreiveAndGenerate API, and maximum number of retrievals.
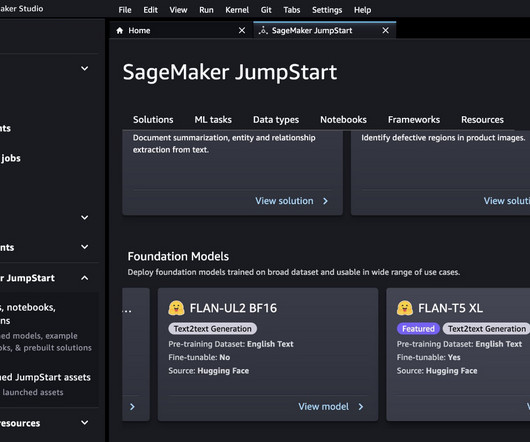
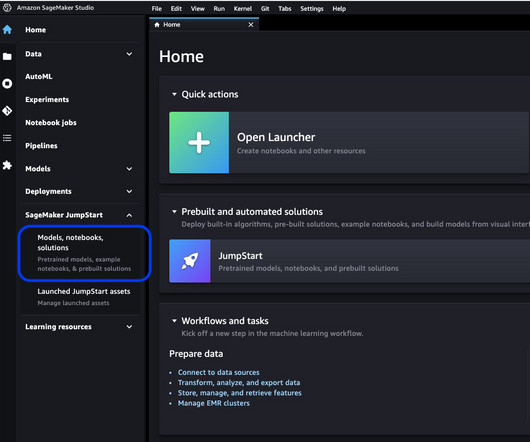
We explore two ways of obtaining the same result: via JumpStart’s graphical interface on Amazon SageMaker Studio , and programmatically through JumpStart APIs. The following sections provide a step-by-step demo to perform inference, both via the Studio UI and via JumpStart APIs. JumpStart overview. Solution overview.
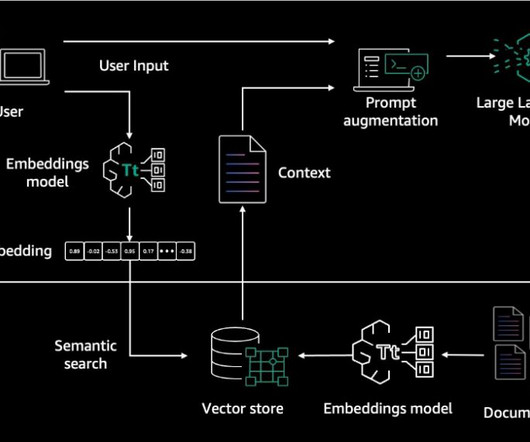
For text generation, Amazon Bedrock provides the RetrieveAndGenerate API to create embeddings of user queries, and retrieves relevant chunks from the vector database to generate accurate responses. Boto3 makes it straightforward to integrate a Python application, library, or script with AWS services.
The Retrieve and RetrieveAndGenerate APIs allow your applications to directly query the index using a unified and standard syntax without having to learn separate APIs for each different vector database, reducing the need to write custom index queries against your vector store.
We explore two ways of obtaining the same result: via JumpStart’s graphical interface on Amazon SageMaker Studio , and programmatically through JumpStart APIs. If you want to jump straight into the JumpStart API code we go through in this post, you can refer to the following sample Jupyter notebook: Introduction to JumpStart – Text to Image.
MLOps – Because the SageMaker endpoint is private and can’t be reached by services outside of the VPC, an AWS Lambda function and Amazon API Gateway public endpoint are required to communicate with CRM. The function then relays the classification back to CRM through the API Gateway public endpoint.
In this post, we provide an overview of how to deploy and run inference with the Stable Diffusion upscaler model in two ways: via JumpStart’s user interface (UI) in Amazon SageMaker Studio , and programmatically through JumpStart APIs available in the SageMaker Python SDK.
In this post, we address these limitations by implementing the access control outside of the MLflow server and offloading authentication and authorization tasks to Amazon API Gateway , where we implement fine-grained access control mechanisms at the resource level using Identity and Access Management (IAM). Adds an IAM authorizer.
In this post, we present a comprehensive guide on deploying and running inference using the Stable Diffusion inpainting model in two methods: through JumpStart’s user interface (UI) in Amazon SageMaker Studio , and programmatically through JumpStart APIs available in the SageMaker Python SDK.
We explore two ways of obtaining the same result: via JumpStart’s graphical interface on Amazon SageMaker Studio , and programmatically through JumpStart APIs. The following sections provide a step-by-step demo to perform semantic segmentation with JumpStart, both via the Studio UI and via JumpStart APIs. Solution overview.
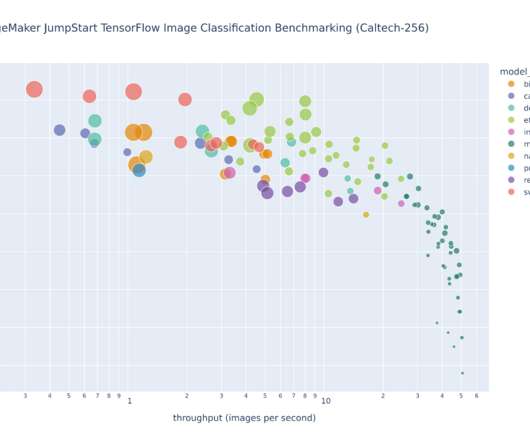
Recently, we also announced the launch of easy-to-use JumpStart APIs as an extension of the SageMaker Python SDK, allowing you to programmatically deploy and fine-tune a vast selection of JumpStart-supported pre-trained models on your own datasets. JumpStart overview. The dataset has been downloaded from TensorFlow. Walkthrough overview.
JumpStart APIs allow you to programmatically deploy and fine-tune a vast selection of JumpStart-supported pre-trained models on your own datasets. JumpStart allows you to train, tune, and deploy models either from the JumpStart console using its UI or with its API. Solution overview.
Dataset collection We followed the methodology outlined in the PMC-Llama paper [6] to assemble our dataset, which includes PubMed papers sourced from the Semantic Scholar API and various medical texts cited within the paper, culminating in a comprehensive collection of 88 billion tokens. Create and launch ParallelCluster in the VPC.
The JumpStart APIs allow you to programmatically deploy and fine-tune a vast selection of pre-trained models on your own datasets. These features remove the heavy lifting from each step of the ML process, making it easier to develop high-quality models and reducing time to deployment.
At the 2024 NVIDIA GTC conference, we announced support for NVIDIA NIM Inference Microservices in Amazon SageMaker Inference. This allows developers to take advantage of the power of these advanced models using SageMaker APIs and just a few lines of code, accelerating the deployment of cutting-edge AI capabilities within their applications.
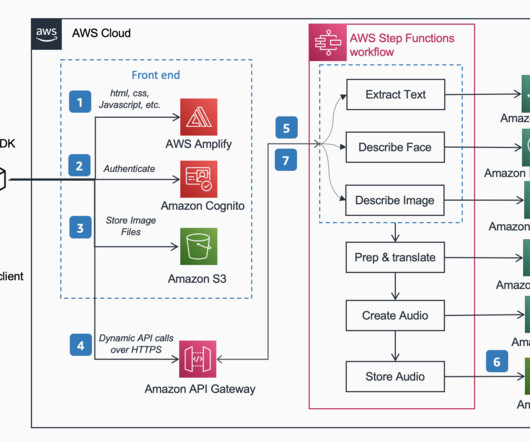
At the 2022 AWS re:Invent conference in Las Vegas, we demonstrated “Describe for Me” at the AWS Builders’ Fair, a website which helps the visually impaired understand images through image caption, facial recognition, and text-to-speech, a technology we refer to as “Image to Speech.” Accessibility has come a long way, but what about images?
In this post, we provide an overview of how to fine-tune the Stable Diffusion model in two ways: programmatically through JumpStart APIs available in the SageMaker Python SDK , and JumpStart’s user interface (UI) in Amazon SageMaker Studio. Fine-tuning large models like Stable Diffusion usually requires you to provide training scripts.
As a JumpStart model hub customer, you get improved performance without having to maintain the model script outside of the SageMaker SDK. The inference script is prepacked with the model artifact. nYou can access Amazon Comprehend document analysis capabilities using the Amazon Comprehend console or using the Amazon Comprehend APIs.
The TGI framework underpins the model inference layer, providing RESTful APIs for robust integration and effortless accessibility. Supplementing our auditory data processing, the Whisper ASR is also furnished with a RESTful API, enabling streamlined voice-to-text conversions.
We implement the RAG functionality inside an AWS Lambda function with Amazon API Gateway to handle routing all requests to the Lambda. We implement a chatbot application in Streamlit which invokes the function via the API Gateway and the function does a similarity search in the OpenSearch Service index for the embeddings of user question.
In this post, we provide an overview of how to deploy and run inference with the AlexaTM 20B model programmatically through JumpStart APIs, available in the SageMaker Python SDK. To use a large language model in SageMaker, you need an inferencing script specific for the model, which includes steps like model loading, parallelization and more.
The JumpStart APIs allow you to programmatically deploy and fine-tune a vast selection of pre-trained models on your own datasets. deploy_source_uri – Use the script_uris utility API to retrieve the S3 URI that contains scripts to run pre-trained model inference. We specify the script_scope as inference.
We use the custom terminology dictionary to compile frequently used terms within video transcription scripts. She holds 30+ patents and has co-authored 100+ journal/conference papers. MagellanTV , a leading streaming platform for documentaries, wants to broaden its global presence through content internationalization.
This notebook demonstrates how to use the JumpStart API for text classification. To run inference on this model, we first need to download the inference container ( deploy_image_uri ), inference script ( deploy_source_uri ), and pre-trained model ( base_model_uri ). Text classification.
Even if you already have a pre-trained model, it may still be easier to use its corollary in SageMaker and input the hyperparameters you already know rather than port it over and write a training script yourself. The training and inference scripts for the selected model or algorithm.
To demonstrate how you can use this solution in your existing business infrastructures, we also include an example of making REST API calls to the deployed model endpoint, using AWS Lambda to trigger both the RCF and XGBoost models. He has published many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Series A journal.
script with llava_inference.py , and create a model.tar.gz script has additional code to allow reading an image file from Amazon S3 and running inference on it. Tip You can use OpenSearch Dashboards to interact with the OpenSearch API to run quick tests on your index and ingested data. file for this model. The model.tar.gz
Note that you need to pass the Predictor class when deploying model through the Model class to be able to run inference through the SageMaker API. You can access Amazon Comprehend document analysis capabilities using the Amazon Comprehend console or using the Amazon Comprehend APIs.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon via a single API. This is because such tasks require organization-specific data and workflows that typically need custom programming.
In the current scenario, you need to dedicate resources to accomplish such tasks using human review and complex scripts. Amazon Bedrock is a fully managed service that makes FMs from leading AI startups and Amazon available through an API, so you can find the model that best suits your requirements.
script that matches the model’s expected input and output. The important thing is to review available VQA models, at the time you read this, and be prepared to deploy the model you choose, which will have its own API request and response contract. As you read this, the mix of available VQA models may change. References Ahmed, E.
We make this possible in a few API calls in the JumpStart Industry SDK. Using the SageMaker API, we downloaded annual reports ( 10-K filings ; see How to Read a 10-K for more information) for a large number of companies. We select Amazon’s SEC filing reports for years 2021–2022 as the training data to fine-tune the GPT-J 6B model.
As a SageMaker JumpStart model hub customer, you can use ASR without having to maintain the model script outside of the SageMaker SDK. In this post, we demonstrate how to deploy the Whisper API using the SageMaker Studio console or a SageMaker Notebook and then use the deployed model for speech recognition and language translation.
You can access Amazon Comprehend document analysis capabilities using the Amazon Comprehend console or using the Amazon Comprehend APIs. The model URI, which contains the inference script, and the URI of the Docker container are obtained through the SageMaker SDK. Provide a predictor_cls to use the SageMaker API for inference.
You can serialize pipelines to YAML files , expose them via a REST API , and scale them flexibly with your workloads, making it easy to move your application from a prototype stage to production. script to preprocess and index the provided demo data. script to fit your needs if you chose to use your own data.
Since everything is managed in a separate tool, no code deployments are required which confers greater agility and lower cost to the business. Built from the ground up as a Data API for integration with your applications, also accessible via web-based user interface.
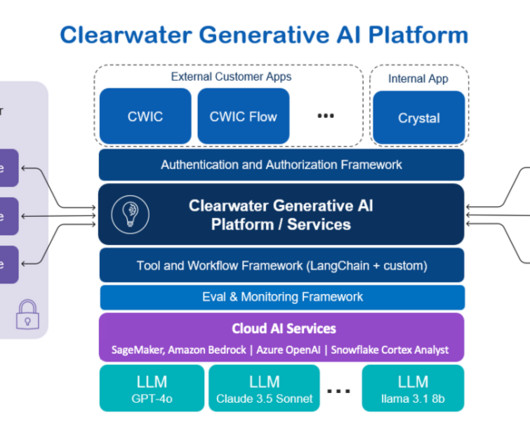
By September of the same year, Clearwater unveiled its generative AI customer offerings at the Clearwater Connect User Conference, marking a significant milestone in their AI-driven transformation. Crystal shares CWICs core functionalities but benefits from broader data sources and API access.
Agent scripting – Agents can be provided with predetermined scripts to increase customer engagement. 8×8 provides solutions for VoIP calls, video conferencing, APIs for SMS and chat, and so on, and also integrates with third-party solutions like Microsoft Teams, Salesforce, Google Workspace, and Freshdesk.
In some cases, the focus is on automation, where emerging AI-driven applications can take on manual tasks, such as scheduling meetings, or transcribing conference calls. Another example would be using APIs to customize applications quickly and easily, such as IVR scripts or time-sensitive notifications.
per user per month Premium – Message, video, and phone features and an open API at $33.74 per user per month Ultimate – Message, video, and phone features and an open API at $44.99 per user, per month for a customized UCaaS platform with dashboards, analytics, and open APIs. per user per month. Microsoft Teams.
Global conferencing – Global dial-in so teams from any location can be added to conference calls. month for up to 40k emails WhatsApp Business API – Starting at $0.0042 per WhatsApp Template message and $0.005 for session messages SMS, WhatsApp, Chat, and MMS – Starting at $0.05 5 Capterra– 4.6/5 5 TrustRadius– 8.5/10
Users have expressed satisfaction with Genesys product performance and services that help them to integrate the system into their infrastructure with API, activity dashboard and CRM integration. It does offer open API to help users customize systems. The company offers phone and online support.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content