This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
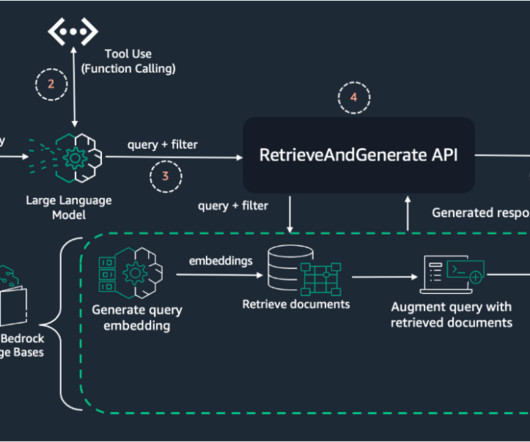
In some use cases, particularly those involving complex user queries or a large number of metadata attributes, manually constructing metadata filters can become challenging and potentially error-prone. By implementing dynamic metadata filtering, you can significantly improve these metrics, leading to more accurate and relevant RAG responses.
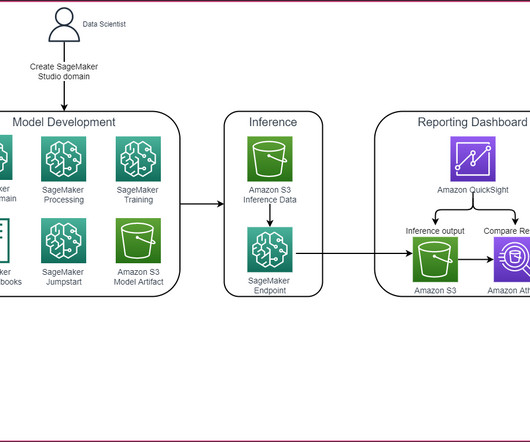
Customers can use the SageMaker Studio UI or APIs to specify the SageMaker Model Registry model to be shared and grant access to specific AWS accounts or to everyone in the organization. With this launch, customers can now seamlessly share and access ML models registered in SageMaker Model Registry between different AWS accounts.
Thanks to this construct, you can evaluate any LLM by configuring the model runner according to your model. Evaluation algorithm Computes evaluation metrics to model outputs. Different algorithms have different metrics to be specified. Model runner Composes input, and invokes and extracts output from your model.
adds new APIs to customize GraphStorm pipelines: you now only need 12 lines of code to implement a custom node classification training loop. Based on customer feedback for the experimental APIs we released in GraphStorm 0.2, introduces refactored graph ML pipeline APIs. Specifically, GraphStorm 0.3 In addition, GraphStorm 0.3
Amazon Bedrock agents use LLMs to break down tasks, interact dynamically with users, run actions through API calls, and augment knowledge using Amazon Bedrock Knowledge Bases. In this post, we demonstrate how to use Amazon Bedrock Agents with a web search API to integrate dynamic web content in your generative AI application.
Where discrete outcomes with labeled data exist, standard ML methods such as precision, recall, or other classic ML metrics can be used. These metrics provide high precision but are limited to specific use cases due to limited ground truth data. If the use case doesnt yield discrete outputs, task-specific metrics are more appropriate.
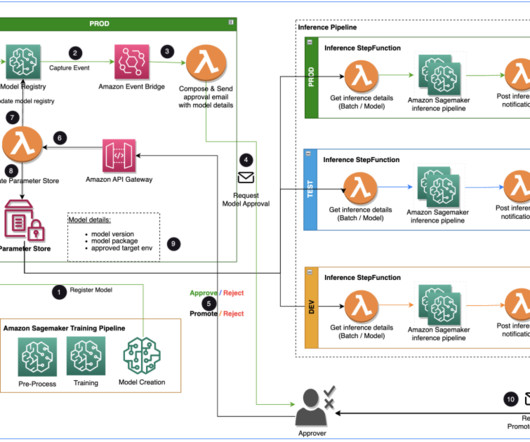
The solution uses AWS Lambda , Amazon API Gateway , Amazon EventBridge , and SageMaker to automate the workflow with human approval intervention in the middle. The EventBridge model registration event rule invokes a Lambda function that constructs an email with a link to approve or reject the registered model.
The user’s request is sent to AWS API Gateway , which triggers a Lambda function to interact with Amazon Bedrock using Anthropic’s Claude Instant V1 FM to process the user’s request and generate a natural language response of the place location. It will then return the place name with the highest similarity score.
It’s a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like Anthropic, Cohere, Meta, Mistral AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Performance metrics and benchmarks Pixtral 12B is trained to understand both natural images and documents, achieving 52.5% You can find detailed usage instructions, including sample API calls and code snippets for integration. To begin using Pixtral 12B, choose Deploy.
AWS Prototyping successfully delivered a scalable prototype, which solved CBRE’s business problem with a high accuracy rate (over 95%) and supported reuse of embeddings for similar NLQs, and an API gateway for integration into CBRE’s dashboards. The following diagram illustrates the web interface and API management layer.
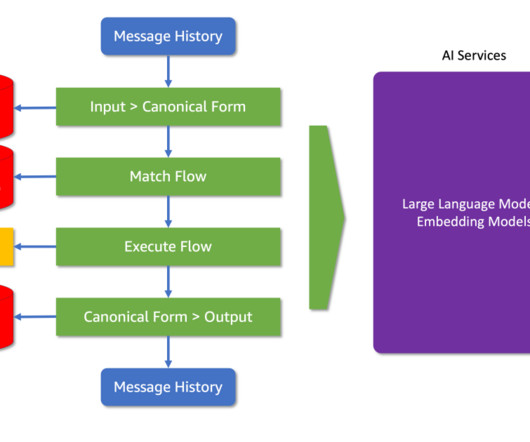
Colang is purpose-built for simplicity and flexibility, featuring fewer constructs than typical programming languages, yet offering remarkable versatility. It leverages natural language constructs to describe dialogue interactions, making it intuitive for developers and simple to maintain. Integrating Llama 3.1 The Llama 3.1
Constructing SQL queries from natural language isn’t a simple task. Figure 2: High level database access using an LLM flow The challenge An LLM can construct SQL queries based on natural language. Figure 2: High level database access using an LLM flow The challenge An LLM can construct SQL queries based on natural language.
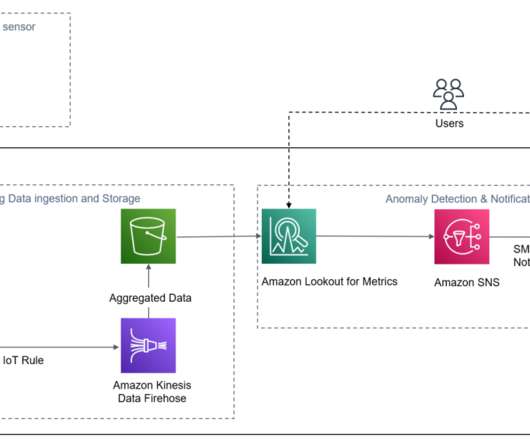
This post shows you how to use an integrated solution with Amazon Lookout for Metrics and Amazon Kinesis Data Firehose to break these barriers by quickly and easily ingesting streaming data, and subsequently detecting anomalies in the key performance indicators of your interest. You don’t need ML experience to use Lookout for Metrics.
You can use the adapter for inference by passing the adapter identifier as an additional parameter to the Analyze Document Queries API request. Adapters can be created via the console or programmatically via the API. You can analyze these metrics either collectively or on a per-document basis. MICR line format).
Prior to the introduction of this feature, customers had to construct these elements using post-processing code and the words and lines response from Amazon Textract. The LAYOUT feature of AnalyzeDocument API can now detect up to ten different layout elements in a document’s page.
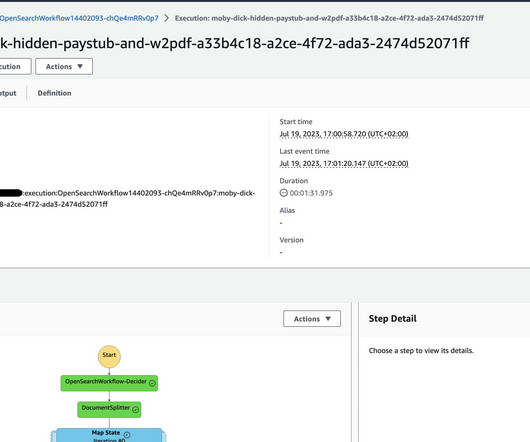
The implementation used in this post utilizes the Amazon Textract IDP CDK constructs – AWS Cloud Development Kit (CDK) components to define infrastructure for Intelligent Document Processing (IDP) workflows – which allow you to build use case specific customizable IDP workflows. The DocumentSplitter is implemented as an AWS Lambda function.
The second approach is a turnkey deployment of various infrastructure components using AWS Cloud Development Kit (AWS CDK) constructs. The AWS CDK construct provides a resilient and flexible framework to process your documents and build an end-to-end IDP pipeline. Now on to our second solution for documents at scale.
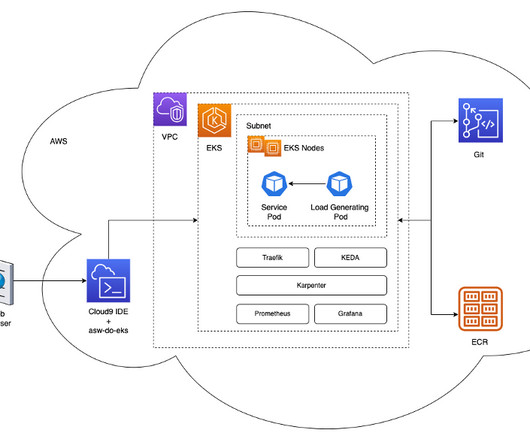
The Kubernetes semantics used by the provisioners support directed scheduling using Kubernetes constructs such as taints or tolerations and affinity or anti-affinity specifications; they also facilitate control over the number and types of GPU instances that may be scheduled by Karpenter. A managed node group with two c5.xlarge
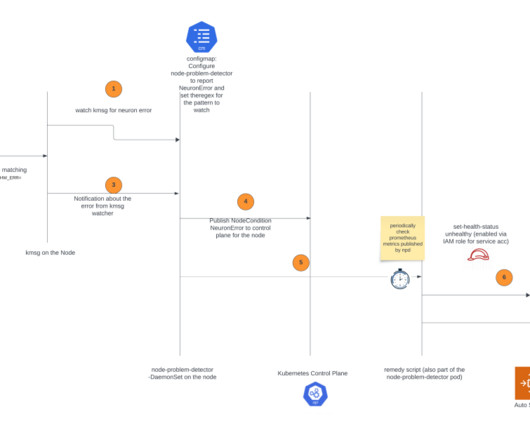
If it detects error messages specifically related to the Neuron device (which is the Trainium or AWS Inferentia chip), it will change NodeCondition to NeuronHasError on the Kubernetes API server. The node recovery agent is a separate component that periodically checks the Prometheus metrics exposed by the node problem detector.
For a quantitative analysis of the generated impression, we use ROUGE (Recall-Oriented Understudy for Gisting Evaluation), the most commonly used metric for evaluating summarization. This metric compares an automatically produced summary against a reference or a set of references (human-produced) summary or translation.
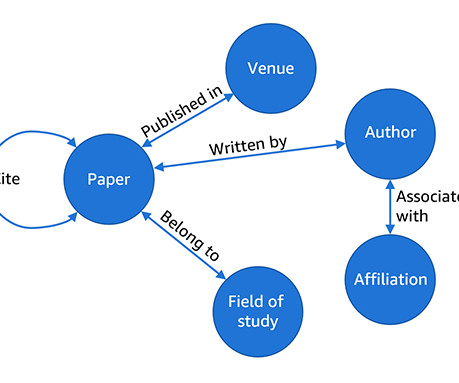
Basically, by using the API of this layer, you can focus on the model development without worrying about how to scale the model training. TB RAM) to construct the OAG graph. After constructing a graph, you can use gs_link_prediction to train a link prediction model on four g5.48xlarge instances.
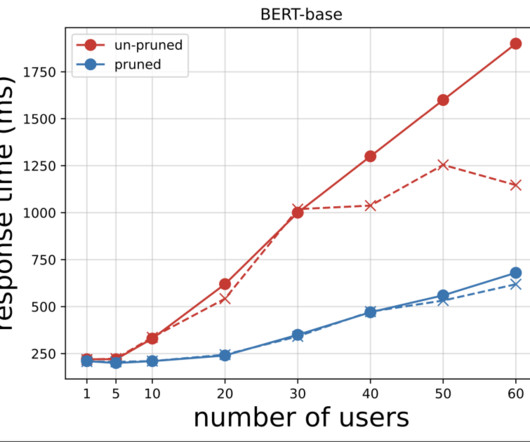
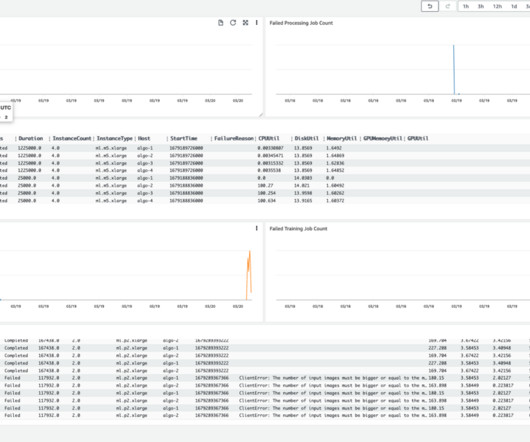
You can also fetch these metrics and analyze them using TrainingJobAnalytics : df = TrainingJobAnalytics(training_job_name=training_job_name).dataframe() dataframe() #It will produce a dataframe with different metrics df.head(10) The following graph shows different metrics collected from the CloudWatch log using TrainingJobAnalytics.
Additionally, it’s challenging to construct a streaming data pipeline that can feed incoming events to a GNN real-time serving API. It starts from a RESTful API that queries the graph database in Neptune to extract the subgraph related to an incoming transaction. FD_SL_Process_IEEE-CIS_Dataset.ipynb. next(dataProcessTask).next(hyperParaTask).next(trainingJobTask).next(runLoadGraphDataTask).next(modelRepackagingTask).next(createModelTask).next(createEndpointConfigTask).next(c
The sheer number of metrics make it hard to filter down to ones that are truly relevant for their use-cases. Amazon SageMaker Clarify now provides AWS customers with foundation model (FM) evaluations, a set of capabilities designed to evaluate and compare model quality and responsibility metrics for any LLM, in minutes.
Another driver behind RAG’s popularity is its ease of implementation and the existence of mature vector search solutions, such as those offered by Amazon Kendra (see Amazon Kendra launches Retrieval API ) and Amazon OpenSearch Service (see k-Nearest Neighbor (k-NN) search in Amazon OpenSearch Service ), among others.
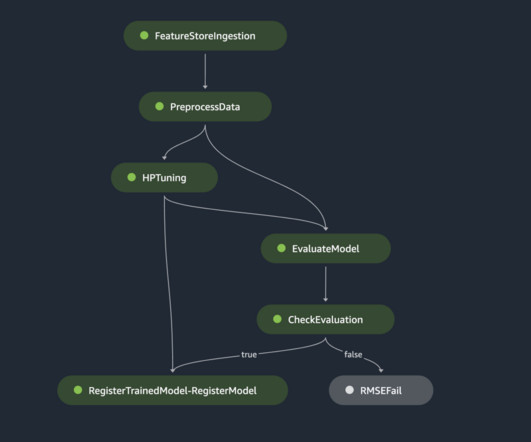
With this format, we can easily query the feature store and work with familiar tools like Pandas to construct a dataset to be used for training later. For this we use AWS Step Functions , a serverless workflow service that provides us with API integrations to quickly orchestrate and visualize the steps in our workflow.
In this post, we address these limitations by implementing the access control outside of the MLflow server and offloading authentication and authorization tasks to Amazon API Gateway , where we implement fine-grained access control mechanisms at the resource level using Identity and Access Management (IAM). Adds an IAM authorizer.
Open-sourcing Falcon 40B enables users to construct and customize AI tools that cater to unique users needs, facilitating seamless integration and ensuring the long-term preservation of data assets. TII used transient clusters provided by the SageMaker Training API to train the Falcon LLM, up to 48 ml.p4d.24xlarge
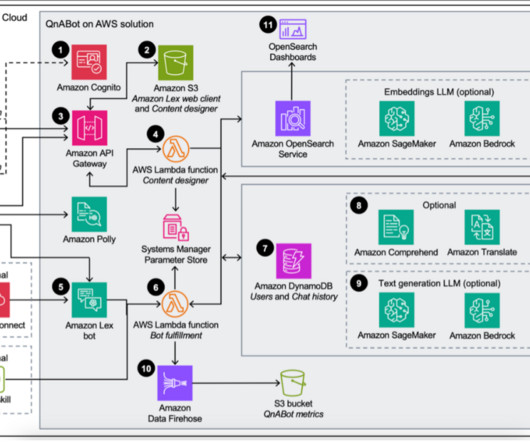
After authentication, Amazon API Gateway and Amazon S3 deliver the contents of the Content Designer UI. The admin configures questions and answers in the Content Designer and the UI sends requests to API Gateway to save the questions and answers. input – A placeholder for the current user utterance or question.
Defining the right objective metric matching your task. When our tuning job is complete, we look at some of the methods available to explore the results, both via the AWS Management Console and programmatically via the AWS SDKs and APIs. Collects metrics and logs. Amazon SageMaker Automatic Model Tuning. Runs the training.
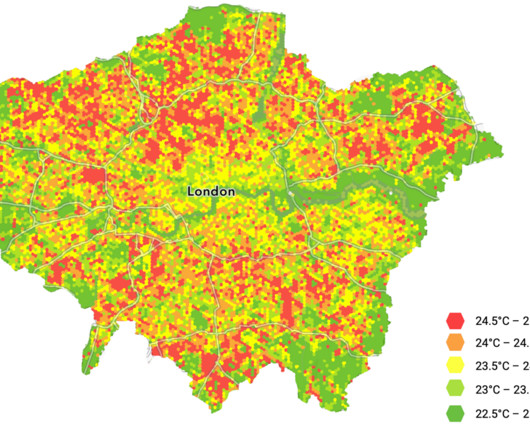
Informing design decisions towards more sustainable choices reduces the overall urban heat islands (UHI) effect and improves quality of life metrics for air quality, water quality, urban acoustics, biodiversity, and thermal comfort. The solution presented here is to direct decision-making processes for resilient city design.
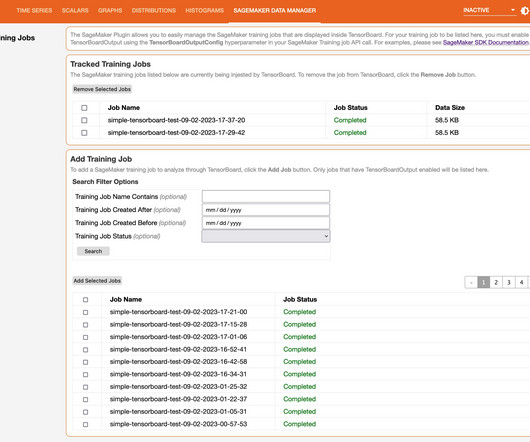
It provides a suite of tools for visualizing training metrics, examining model architectures, exploring embeddings, and more. When they create a SageMaker training job, domain users can use TensorBoard using the SageMaker Python SDK or Boto3 API. x_test / 255.0 x_test / 255.0 x_test / 255.0 strftime("%d-%m-%Y-%H-%M-%S") region = boto3.session.Session().region_name
Throughout this blog post, we will be talking about AutoML to indicate SageMaker Autopilot APIs, as well as Amazon SageMaker Canvas AutoML capabilities. The following diagram depicts the basic AutoMLV2 APIs, all of which are relevant to this post. The diagram shows the workflow for building and deploying models using the AutoMLV2 API.
The goal of NAS is to find the optimal architecture for a given problem by searching over a large set of candidate architectures using techniques such as gradient-free optimization or by optimizing the desired metrics. The performance of the architecture is typically measured using metrics such as validation loss.
In this scenario, the generative AI application, designed by the consumer, must interact with the fine-tuner backend via APIs to deliver this functionality to the end-users. If an organization has no AI/ML experts in their team, then an API service might be better suited for them. 15K available FM reference Step 1.
Call the Amazon Textract analyze_document API using the Queries feature to extract text from the page. In the sample solution, we call the Amazon Textract analyze_document API query feature to extract fields by asking specific questions. The sample dashboard includes basic metrics. Extract text using an Amazon Textract query.
You can scrape the filings from EDGAR directly, or use APIs in Amazon SageMaker with a few lines of code, for any period of time and for a large number of tickers (i.e., The primary limitation of TACP lies in constructing task-specific LLMs instead of foundation LLMs, owing to the sole use of unlabeled task data for training.
SageMaker services, such as Processing, Training, and Hosting, collect metrics and logs from the running instances and push them to users’ Amazon CloudWatch accounts. One example is performing a metric query on the SageMaker job host’s utilization metrics when a job completion event is received.
This solution uses the asynchronous StartDocumentTextDetection API to build the document processing workflow that handles Amazon Textract asynchronous invocation, raw response extraction, and persistence in Amazon Simple Storage Service (Amazon S3). These metrics are used to measure the quality of text extractions.
The combination of Ray and SageMaker provides end-to-end capabilities for scalable ML workflows, and has the following highlighted features: Distributed actors and parallelism constructs in Ray simplify developing distributed applications. Ray AI Runtime (AIR) reduces friction of going from development to production.
Amazon SageMaker distributed training jobs enable you with one click (or one API call) to set up a distributed compute cluster, train a model, save the result to Amazon Simple Storage Service (Amazon S3), and shut down the cluster when complete. colsample_bytree – Subsample ratio of columns when constructing each tree.
Evaluate model performance on the hold-out test data with various evaluation metrics. This notebook demonstrates how to use the JumpStart API for text classification. After the fine-tuning job is complete, we deploy the model, run inference on the hold-out test dataset, and compute evaluation metrics. Text classification.
There are service limits (or quotas) for these services to avoid over-provisioning and to limit request rates on API operations, protecting the services from abuse. Collect metrics from the IDP workflow, automate responses to alarms, and send notifications as required to your workflow and business objectives.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content