This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The custom Google Chat app, configured for HTTP integration, sends an HTTP request to an API Gateway endpoint. Before processing the request, a Lambda authorizer function associated with the API Gateway authenticates the incoming message. Run the script init-script.bash : chmod u+x init-script.bash./init-script.bash
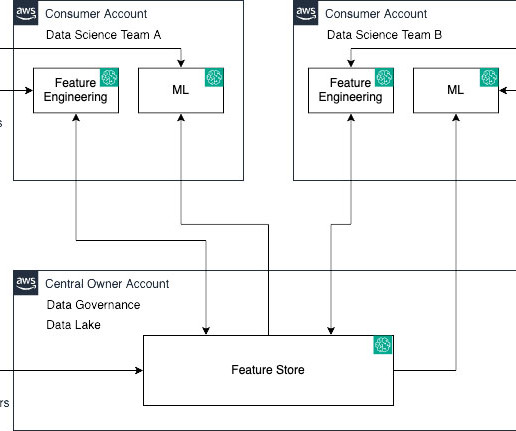
Customers can use the SageMaker Studio UI or APIs to specify the SageMaker Model Registry model to be shared and grant access to specific AWS accounts or to everyone in the organization. We will start by using the SageMaker Studio UI and then by using APIs.
Amazon Bedrock agents use LLMs to break down tasks, interact dynamically with users, run actions through API calls, and augment knowledge using Amazon Bedrock Knowledge Bases. In this post, we demonstrate how to use Amazon Bedrock Agents with a web search API to integrate dynamic web content in your generative AI application.
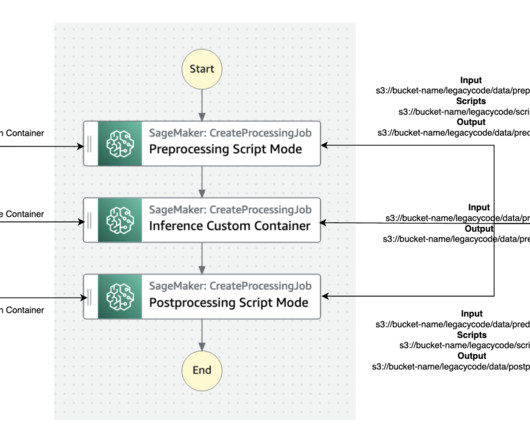
The best practice for migration is to refactor these legacy codes using the Amazon SageMaker API or the SageMaker Python SDK. SageMaker runs the legacy script inside a processing container. Step Functions is a serverless workflow service that can control SageMaker APIs directly through the use of the Amazon States Language.
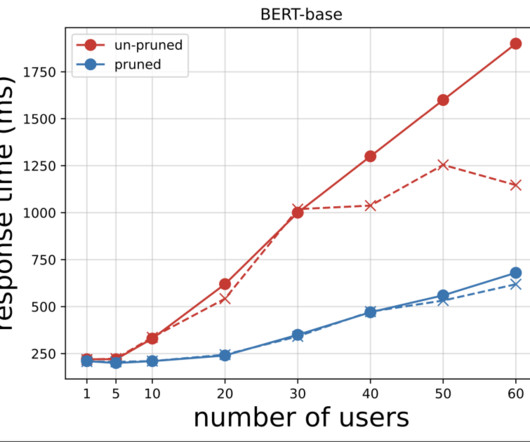
In the following sections, we provide a detailed explanation on how to construct your first prompt, and then gradually improve it to consistently achieve over 90% accuracy. Later, if they saw the employee making mistakes, they might try to simplify the problem and provide constructive feedback by giving examples of what not to do, and why.
The first allows you to run a Python script from any server or instance including a Jupyter notebook; this is the quickest way to get started. The second approach is a turnkey deployment of various infrastructure components using AWS Cloud Development Kit (AWS CDK) constructs. We have packaged this solution in a.ipynb script and.py
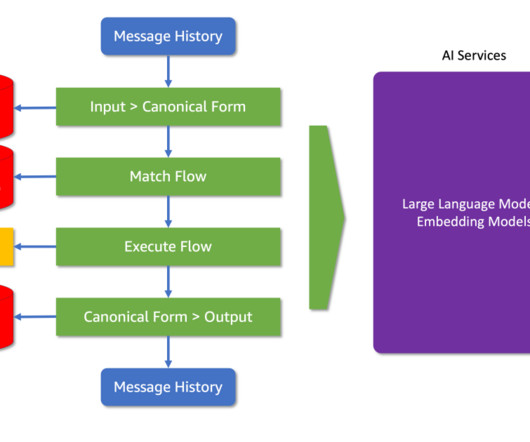
Colang is purpose-built for simplicity and flexibility, featuring fewer constructs than typical programming languages, yet offering remarkable versatility. It leverages natural language constructs to describe dialogue interactions, making it intuitive for developers and simple to maintain. define bot express greeting "Hey there!"
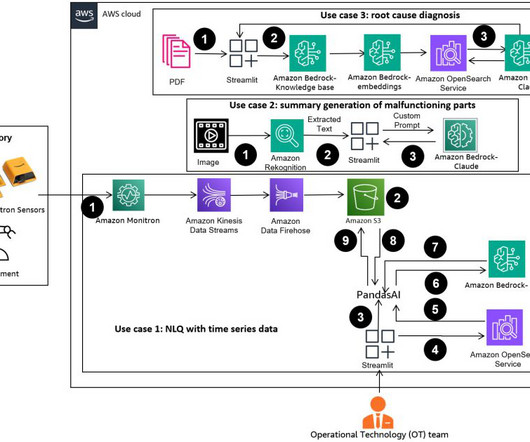
However, complex NLQs, such as time series data processing, multi-level aggregation, and pivot or joint table operations, may yield inconsistent Python script accuracy with a zero-shot prompt. To enhance code generation accuracy, we propose dynamically constructing multi-shot prompts for NLQs. setup.sh. (a a challenge-level question).
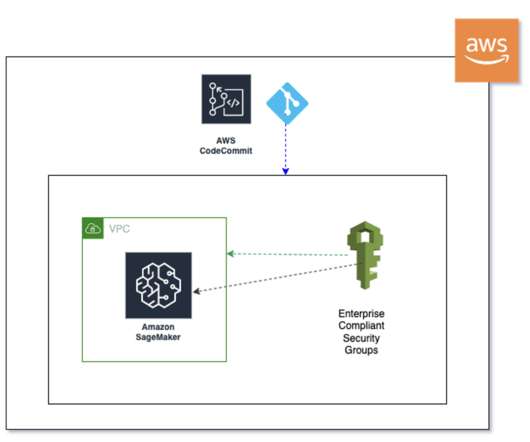
In the post Secure Amazon SageMaker Studio presigned URLs Part 2: Private API with JWT authentication , we demonstrated how to build a private API to generate Amazon SageMaker Studio presigned URLs that are only accessible by an authenticated end-user within the corporate network from a single account.
The endpoints like SageMaker API, SageMaker Studio, and SageMaker notebook facilitate secure and reliable communication between the platform account’s VPC and the SageMaker domain managed by AWS in the SageMaker service account. Notably, each SageMaker domain is provisioned through its individual SageMakerStudioStack.
AWS Prototyping successfully delivered a scalable prototype, which solved CBRE’s business problem with a high accuracy rate (over 95%) and supported reuse of embeddings for similar NLQs, and an API gateway for integration into CBRE’s dashboards. The following diagram illustrates the web interface and API management layer.
Amazon Kendra Intelligent Ranking application programming interface (API) – The functions from this API are used to perform tasks related to provisioning execution plans and semantic re-ranking of your search results. Create and start OpenSearch using the Quickstart script. Download the search_processing_kendra_quickstart.sh
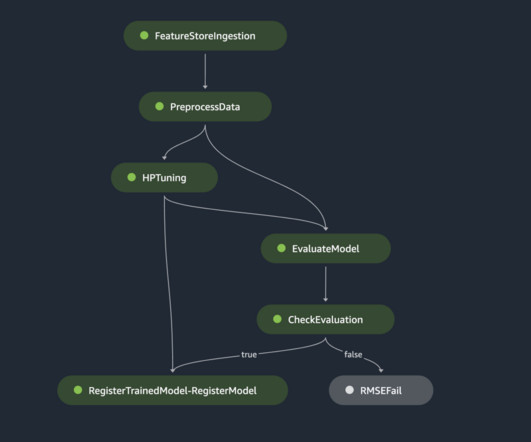
With this format, we can easily query the feature store and work with familiar tools like Pandas to construct a dataset to be used for training later. For this we use AWS Step Functions , a serverless workflow service that provides us with API integrations to quickly orchestrate and visualize the steps in our workflow.
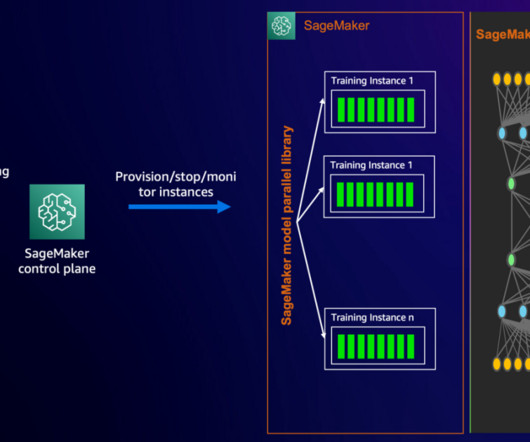
The SMP library uses NVIDIA Megatron to implement expert parallelism and support training MoE models, and runs on top of PyTorch Fully Sharded Data Parallel (FSDP) APIs. With SageMaker training jobs, you can launch and manage clusters of high-performance instances with simple API calls. In this example, we use SageMaker training jobs.
Applications and services can call the deployed endpoint directly or through a deployed serverless Amazon API Gateway architecture. To learn more about real-time endpoint architectural best practices, refer to Creating a machine learning-powered REST API with Amazon API Gateway mapping templates and Amazon SageMaker.
Within the realm of architectural design, Stable Diffusion inpainting can be applied to repair incomplete or damaged areas of building blueprints, providing precise information for construction crews. You have to run end-to-end tests to make sure that the script, the model, and the desired instance work together efficiently.
Additionally, it’s challenging to construct a streaming data pipeline that can feed incoming events to a GNN real-time serving API. It starts from a RESTful API that queries the graph database in Neptune to extract the subgraph related to an incoming transaction. FD_SL_Process_IEEE-CIS_Dataset.ipynb. next(dataProcessTask).next(hyperParaTask).next(trainingJobTask).next(runLoadGraphDataTask).next(modelRepackagingTask).next(createModelTask).next(createEndpointConfigTask).next(c
In order to run inference through SageMaker API, make sure to pass the Predictor class. pre_trained_model = Model( image_uri=deploy_image_uri, model_data=pre_trained_model_uri, role=aws_role, predictor_cls=Predictor, name=pre_trained_name, env=large_model_env, ) # Deploy the pre-trained model.
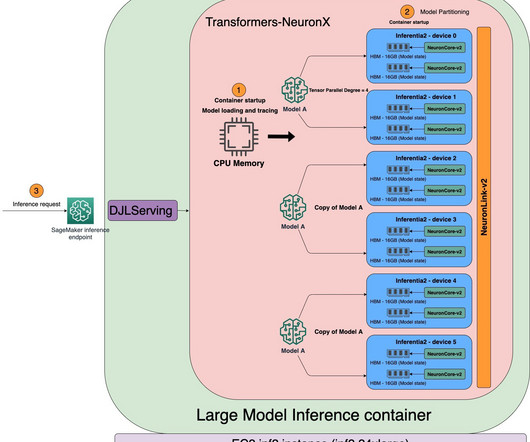
We compile the UNet for one batch (by using input tensors with one batch), then use the torch_neuronx.DataParallel API to load this single batch model onto each core. The directory path for the compiled model is constructed by joining COMPILER_WORKDIR_ROOT with the subdirectory text_encoder : emb = torch.tensor([.])
In this post, we address these limitations by implementing the access control outside of the MLflow server and offloading authentication and authorization tasks to Amazon API Gateway , where we implement fine-grained access control mechanisms at the resource level using Identity and Access Management (IAM). Adds an IAM authorizer.
Another driver behind RAG’s popularity is its ease of implementation and the existence of mature vector search solutions, such as those offered by Amazon Kendra (see Amazon Kendra launches Retrieval API ) and Amazon OpenSearch Service (see k-Nearest Neighbor (k-NN) search in Amazon OpenSearch Service ), among others.
The Kubernetes semantics used by the provisioners support directed scheduling using Kubernetes constructs such as taints or tolerations and affinity or anti-affinity specifications; they also facilitate control over the number and types of GPU instances that may be scheduled by Karpenter. A managed node group with two c5.xlarge
The combination of Ray and SageMaker provides end-to-end capabilities for scalable ML workflows, and has the following highlighted features: Distributed actors and parallelism constructs in Ray simplify developing distributed applications. In the following code, the desired number of actors is passed in as an input argument to the script.
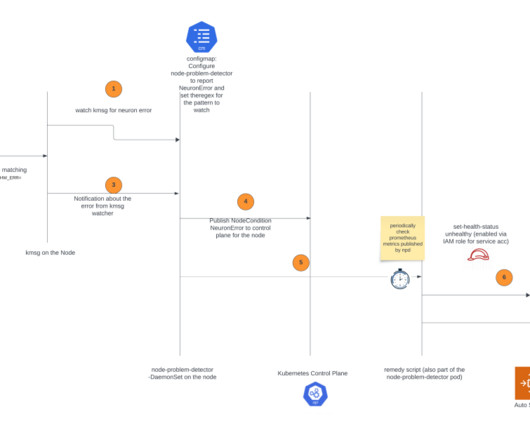
If it detects error messages specifically related to the Neuron device (which is the Trainium or AWS Inferentia chip), it will change NodeCondition to NeuronHasError on the Kubernetes API server. To create the policy, aws cli can be used as shown below where npd-policy-trimmed.json is the policy json constructed from the template above.
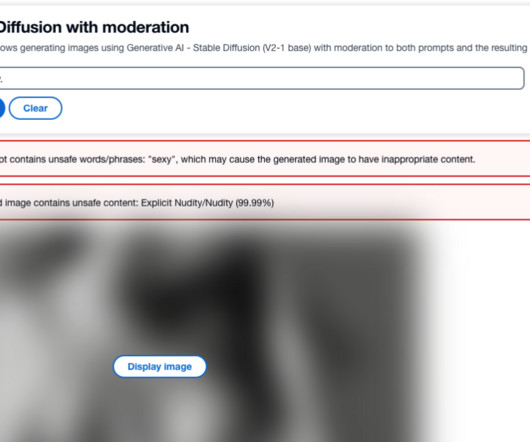
Solution overview Amazon Rekognition and Amazon Comprehend are managed AI services that provide pre-trained and customizable ML models via an API interface, eliminating the need for machine learning (ML) expertise. The RESTful API will return the generated image and the moderation warnings to the client if unsafe information is detected.
The TGI framework underpins the model inference layer, providing RESTful APIs for robust integration and effortless accessibility. Supplementing our auditory data processing, the Whisper ASR is also furnished with a RESTful API, enabling streamlined voice-to-text conversions.
Query the property file eta = JsonGet( step_name=step_process.name, property_file=hyperparam_report, json_path="hyperparam.eta.value", ) Parameterize a variable in pipeline definition Parameterizing variables so that they can be used at runtime is often desirable—for example, to construct an S3 URI. 1", instance_type="ml.m5.xlarge",
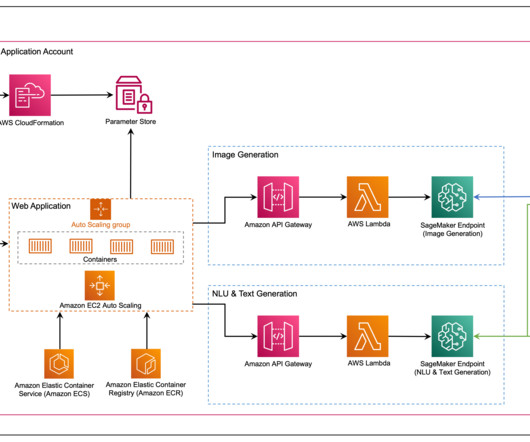
The web application interacts with the models via Amazon API Gateway and AWS Lambda functions as shown in the following diagram. API Gateway provides the web application and other clients a standard RESTful interface, while shielding the Lambda functions that interface with the model. Clone and set up the AWS CDK application.
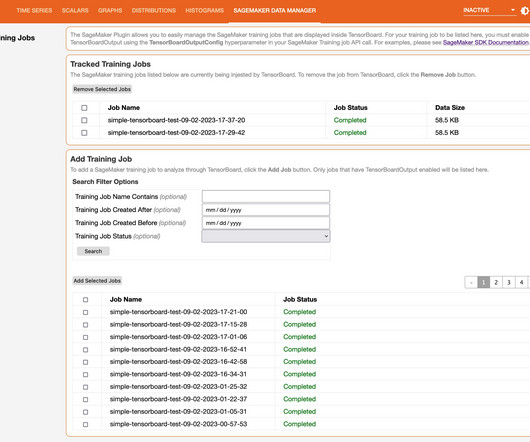
When they create a SageMaker training job, domain users can use TensorBoard using the SageMaker Python SDK or Boto3 API. Solution overview A typical training job for deep learning in SageMaker consists of two main steps: preparing a training script and configuring a SageMaker training job launcher. x_test / 255.0 session.Session().region_name
In this post, we provide an overview of how to fine-tune the Stable Diffusion model in two ways: programmatically through JumpStart APIs available in the SageMaker Python SDK , and JumpStart’s user interface (UI) in Amazon SageMaker Studio. Fine-tuning large models like Stable Diffusion usually requires you to provide training scripts.
When our tuning job is complete, we look at some of the methods available to explore the results, both via the AWS Management Console and programmatically via the AWS SDKs and APIs. We use the XGBoost algorithm, one of many algorithms provided as a SageMaker built-in algorithm (no training script required!). Construct the estimator.
The framework works by posing the sequence to be classified as an NLI premise and constructs a hypothesis from each candidate label. For example, if we want to evaluate whether a sequence belongs to the class politics , we could construct a hypothesis of “This text is about politics.” We specify the script_scope as inference.
In addition to the SageMaker native events, AWS CloudTrail publishes events when you make API calls, which also streams to EventBridge so that this can be utilized by many downstream automation or monitoring use cases. Input Description Example Home Region The Region where the workloads run. aws/config. Keep the / at the end of the path.
In this post, we enable the provisioning of different components required for performing log analysis using Amazon SageMaker on AWS DeepRacer via AWS CDK constructs. An administrator can run the AWS CDK script provided in the GitHub repo via the AWS Management Console or in the terminal after loading the code in their environment.
We walk through an end-to-end example, from loading the Faster R-CNN object detection model weights, to saving them to an Amazon Simple Storage Service (Amazon S3) bucket, and to writing an entrypoint file and understanding the key parameters in the PyTorchModel API. Step 4: Building ML model inference scripts. Step 1: Setup.
Their task is to construct and oversee efficient data pipelines. The second script accepts the AWS RAM invitations to discover and access cross-account feature groups from the owner level. Drawing data from source systems, they mold raw data attributes into discernable features. Take “age” for instance.
It lays out a type of internal monologue or cognitive path for the LLM to follow in order to comprehend the key information within the question, determine what kind of response is needed, and construct that response in an appropriate and accurate way. For more details see the OpenSearch documentation on structuring a search query.
The Neuron runtime consists of kernel driver and C/C++ libraries, which provide APIs to access AWS Inferentia and Trainium Neuron devices. xlarge" ) Refer to Developer Flows for more details on typical development flows of Inf2 on SageMaker with sample scripts. These endpoints are fully managed and support auto scaling.
You can access Amazon Comprehend document analysis capabilities using the Amazon Comprehend console or using the Amazon Comprehend APIs. The University of the Philippines (UP) is set to construct a new building for its College of Medicine and Health Sciences (CMHS) in the campus of the University of Santo Tomas (UST) in Bacolod City.
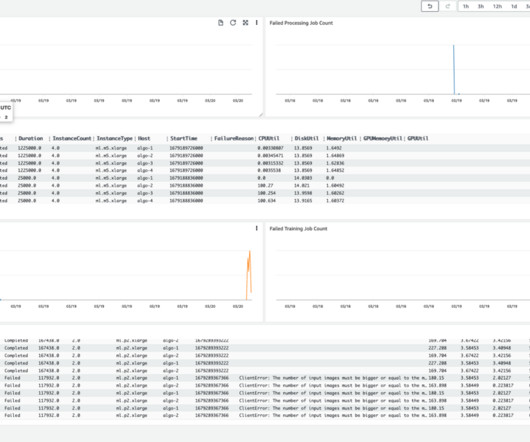
For detailed diagnosis, run the training jobs with Amazon SageMaker Debugger to profile resource utilization status, statistics, and framework operations, by adding a profiler configuration when you construct a SageMaker estimator using the SageMaker Python SDK. Distribute training scripts and dependencies to instances. The launcher.py
Phrase 2: A bearded man pulls a rope We load the textual recognizing entailment dataset from the GLUE benchmarking suite via the dataset library from Hugging Face within our training script (./training.py Then we construct a request metadata and record the start time to be used for load testing. training.py ).
This notebook demonstrates how to use the JumpStart API for text classification. To run inference on this model, we first need to download the inference container ( deploy_image_uri ), inference script ( deploy_source_uri ), and pre-trained model ( base_model_uri ). Text classification.
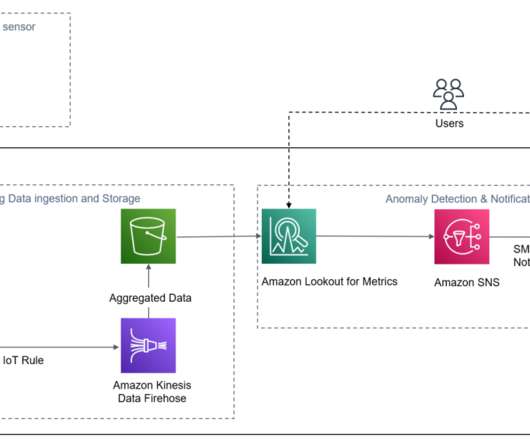
Download the Python script ( publish.py ) and data file from the GitHub repo. This is required to simulate sensor data for the current date using the IoT simulator script. It also provides the capability to query the anomalies via APIs. The following diagram illustrates our solution architecture. Prerequisites. Conclusion.
The Execute code step type was introduced along with the new visual editor and provides three execution modes in which code can be run: Jupyter Notebooks, Python functions, and Shell or Python scripts. For more information about the Execute code step type, see the developer guide. In this example, you will use a Python function.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content