This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, we guide you through integrating Amazon Bedrock Agents with enterprise data APIs to create more personalized and effective customer support experiences. An automotive retailer might use inventory management APIs to track stock levels and catalog APIs for vehicle compatibility and specifications.
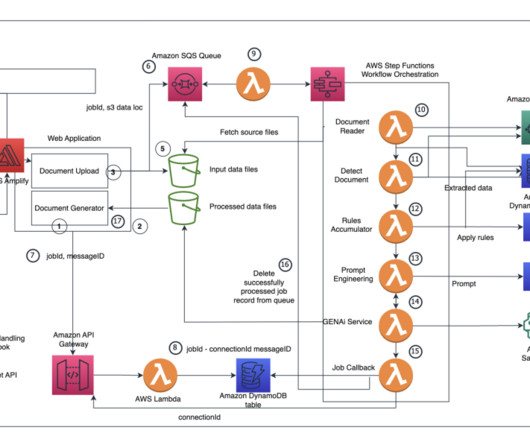
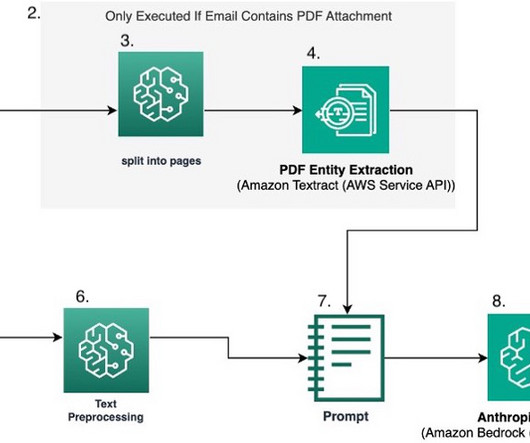
In this post, we focus on one such complex workflow: document processing. Rule-based systems or specialized machine learning (ML) models often struggle with the variability of real-world documents, especially when dealing with semi-structured and unstructured data.
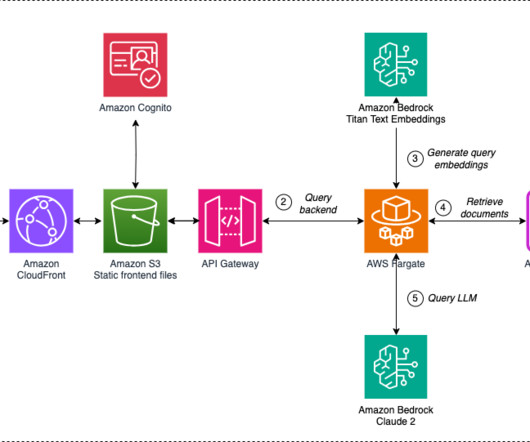
This post presents a solution for developing a chatbot capable of answering queries from both documentation and databases, with straightforward deployment. For documentation retrieval, Retrieval Augmented Generation (RAG) stands out as a key tool. Virginia) AWS Region. The following diagram illustrates the solution architecture.
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. As Principal grew, its internal support knowledge base considerably expanded.
Lets say the task at hand is to predict the root cause categories (Customer Education, Feature Request, Software Defect, Documentation Improvement, Security Awareness, and Billing Inquiry) for customer support cases. We suggest consulting LLM prompt engineering documentation such as Anthropic prompt engineering for experiments.
A key part of the submission process is authoring regulatory documents like the Common Technical Document (CTD), a comprehensive standard formatted document for submitting applications, amendments, supplements, and reports to the FDA. The tedious process of compiling hundreds of documents is also prone to errors.
adds new APIs to customize GraphStorm pipelines: you now only need 12 lines of code to implement a custom node classification training loop. For more details about how to run graph multi-task learning with GraphStorm, refer to Multi-task Learning in GraphStorm in our documentation. introduces refactored graph ML pipeline APIs.
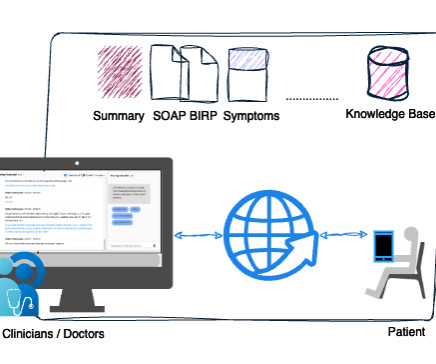
Today, physicians spend about 49% of their workday documenting clinical visits, which impacts physician productivity and patient care. LMA for healthcare is an extended version of the Live Meeting Assistant solution that has been adapted to generate clinical notes automatically during virtual doctor-patient consultations.
This post shows how to configure an Amazon Q Business custom connector and derive insights by creating a generative AI-powered conversation experience on AWS using Amazon Q Business while using access control lists (ACLs) to restrict access to documents based on user permissions. Who are the data stewards for my proprietary database sources?
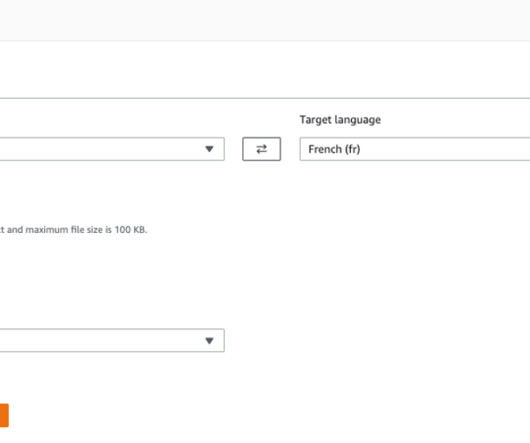
Now, Amazon Translate offers real-time document translation to seamlessly integrate and accelerate content creation and localization. This feature eliminates the wait for documents to be translated in asynchronous batch mode. This feature eliminates the wait for documents to be translated in asynchronous batch mode.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Such data often lacks the specialized knowledge contained in internal documents available in modern businesses, which is typically needed to get accurate answers in domains such as pharmaceutical research, financial investigation, and customer support. For example, imagine that you are planning next year’s strategy of an investment company.
However, there are benefits to building an FM-based classifier using an API service such as Amazon Bedrock, such as the speed to develop the system, the ability to switch between models, rapid experimentation for prompt engineering iterations, and the extensibility into other related classification tasks.
Amazon Bedrock is a fully managed service that makes a wide range of foundation models (FMs) available though an API without having to manage any infrastructure. Amazon API Gateway and AWS Lambda to create an API with an authentication layer and integrate with Amazon Bedrock. The AWS Well-Architected Framework documentation.
Solution overview Our solution implements a verified semantic cache using the Amazon Bedrock Knowledge Bases Retrieve API to reduce hallucinations in LLM responses while simultaneously improving latency and reducing costs. The function checks the semantic cache (Amazon Bedrock Knowledge Bases) using the Retrieve API.
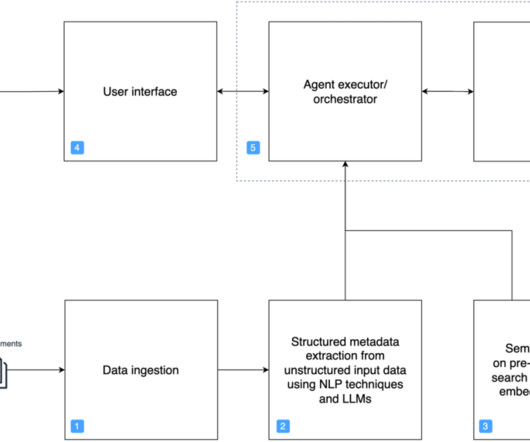
Current challenges faced by enterprises Modern enterprises face numerous challenges, including: Managing vast amounts of unstructured data: Enterprises deal with immense volumes of data generated from various sources such as emails, documents, and customer interactions.
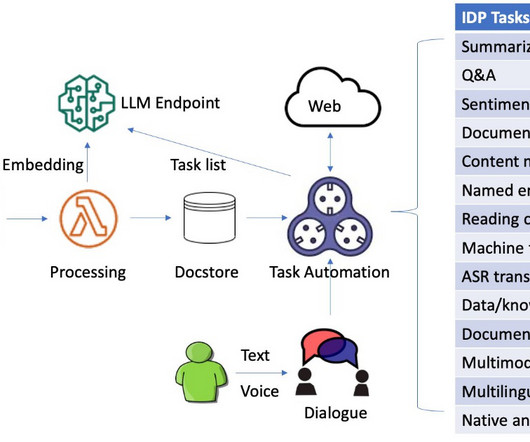
Intelligent document processing (IDP) is a technology that automates the processing of high volumes of unstructured data, including text, images, and videos. The system is capable of processing images, large PDF, and documents in other format and answering questions derived from the content via interactive text or voice inputs.
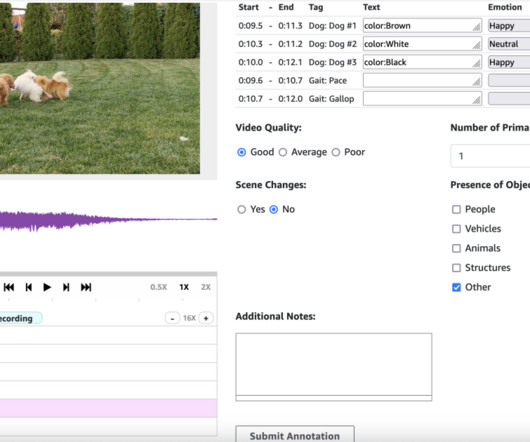
Programmatic setup Alternatively, you can create your labeling job programmatically using the CreateLabelingJob API. Whether you choose the SageMaker console or API approach, the result is the same: a fully configured labeling job ready for your annotation team. documentation. When implementing additional Wavesurfer.js
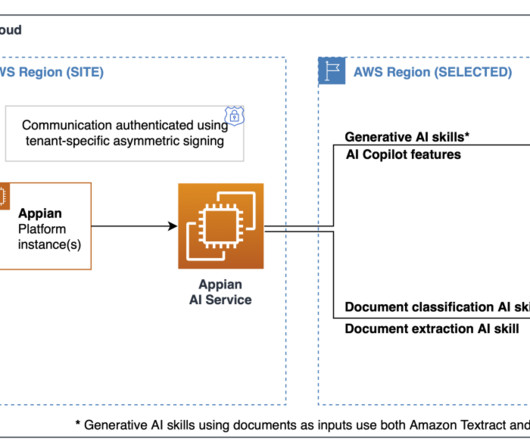
We partnered with Keepler , a cloud-centered data services consulting company specialized in the design, construction, deployment, and operation of advanced public cloud analytics custom-made solutions for large organizations, in the creation of the first generative AI solution for one of our corporate teams.
At the forefront of this evolution sits Amazon Bedrock , a fully managed service that makes high-performing foundation models (FMs) from Amazon and other leading AI companies available through an API. System integration – Agents make API calls to integrated company systems to run specific actions. Gather evidence for claim 5t16u-7v.
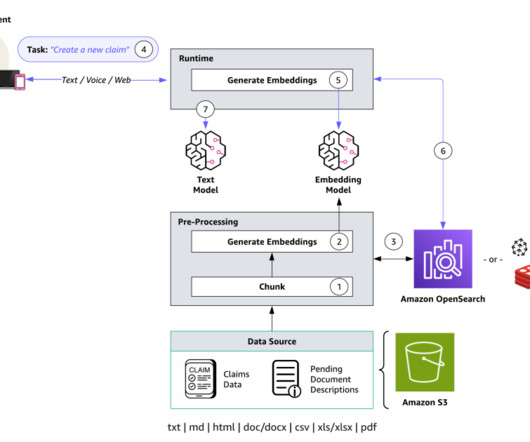
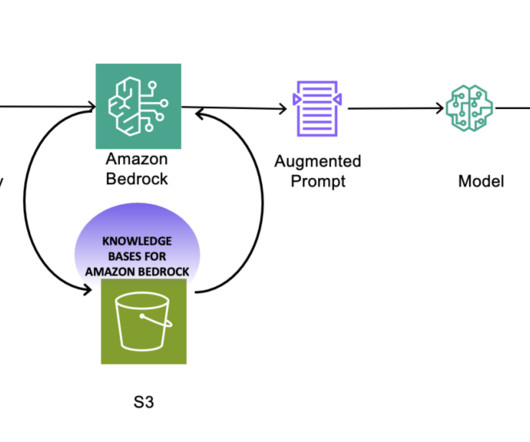
Knowledge Bases for Amazon Bedrock automates synchronization of your data with your vector store, including diffing the data when it’s updated, document loading, and chunking, as well as semantic embedding. It then employs a language model to generate a response by considering both the retrieved documents and the original query.
From our experience, it is the framing phase that is the most time-consuming as you have to consult with all the teams involved in the project and obtain various approvals to start the developments. Poor technical documentation. How long does it take to deploy an AI chatbot?
Challenge 2: Integration with Wearables and Third-Party APIs Many people use smartwatches and heart rate monitors to measure sleep, stress, and physical activity, which may affect mental health. Third-party APIs may link apps to healthcare and meditation services. However, integrating these diverse sources is not straightforward.
Chat with documents (RAG) Command R/R+ can ground its generations. This means that it can generate responses based on a list of supplied document snippets, and it includes citations in its response indicating the source of the information. These can be used to instruct any other application or tool.
The user can use the Amazon Recognition DetectText API to extract text data from these images. Upload documents from the data folder assetpartdoc in the GitHub repository to the S3 bucket listed in the CloudFormation stack outputs. Next, you create the knowledge base for the documents in Amazon S3. Choose Next.
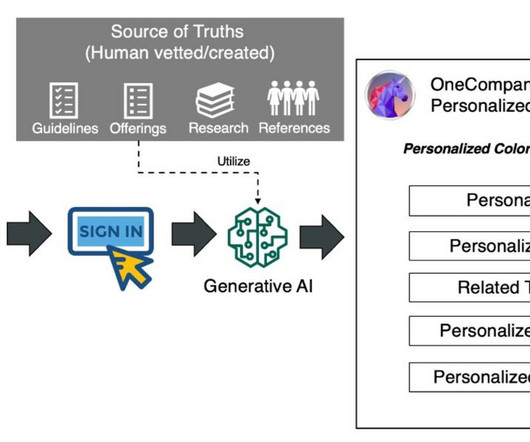
We present our solution through a fictional consulting company, OneCompany Consulting, using automatically generated personalized website content for accelerating business client onboarding for their consultancy service. For this post, we use Anthropic’s Claude models on Amazon Bedrock. Our core values are: 1.
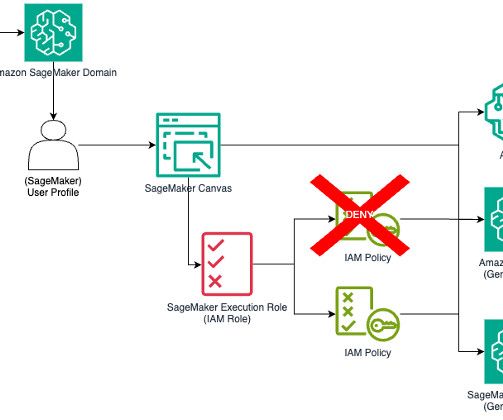
To use a specific LLM from Amazon Bedrock, SageMaker Canvas uses the model ID of the chosen LLM as part of the API calls. Limit access to all Amazon Bedrock models To restrict access to all Amazon Bedrock models, you can modify the SageMaker role to explicitly deny these APIs. This prevents the creation of endpoints using these models.
Amazon Bedrock is a fully managed service that makes foundational models (FMs) from leading artificial intelligence (AI) companies and Amazon available through an API, so you can choose from a wide range of FMs to find the model that’s best suited for your use case.
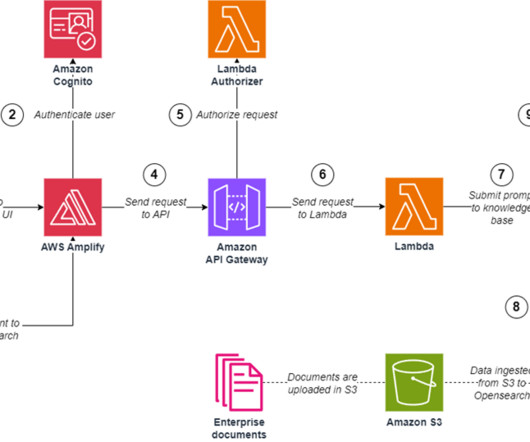
This solution uses an Amazon Cognito user pool as an OAuth-compatible identity provider (IdP), which is required in order to exchange a token with AWS IAM Identity Center and later on interact with the Amazon Q Business APIs. Amazon Q uses the chat_sync API to carry out the conversation.
Local cultural consultants help align content. Translation Accuracy Mistakes, inconsistencies, omissions and misinterpretations are simply not acceptable when you are dealing with regulated content like medical device IFUs or financial documentation. Precise quality assurance, linguistic and subject matter expertise is crucial.
Access and permissions to configure IDP to register Data Wrangler application and set up the authorization server or API. Configure the IdP To set up your IdP, you must register the Data Wrangler application and set up your authorization server or API. Provide the users within the IdP access to Data Wrangler.
Note: For any considerations of adopting this architecture in a production setting, it is imperative to consult with your company specific security policies and requirements. model API exposed by SageMaker JumpStart properly. encode("utf-8") def transform_output(self, output): output_data = json.loads(output.read().decode("utf-8"))
To enable quick information retrieval, we use Amazon Kendra as the index for these documents. Amazon Kendra uses natural language processing (NLP) to understand user queries and find the most relevant documents. Karn Chahar is a Security Consultant with the shared delivery team at AWS.
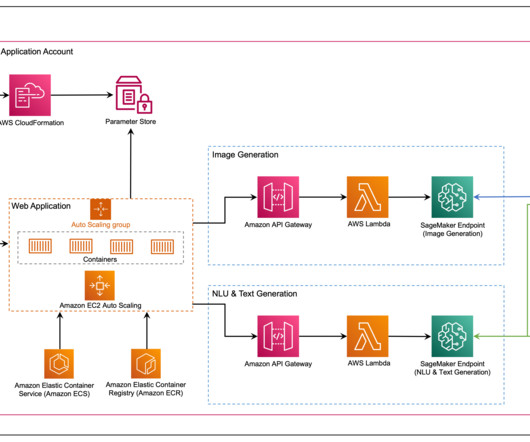
Original content production, code generation, customer service enhancement, and document summarization are typical use cases of generative AI. The web application interacts with the models via Amazon API Gateway and AWS Lambda functions as shown in the following diagram. Clone and set up the AWS CDK application. Choose Generate image.
Since its launch a few months ago, the Visual Intelligence Platform has delivered analysis and insights within both TechSee’s products and via API integrations into third-party solutions like chatbots or workflows. The VI Mobile SDK can automatically identify your specific hardware models and components. Field Service Job Confirmation.
Brad Butler, Contact Center Software Consultant @NobelBiz The Importance of Customer Data in Call Centers Customer Data Platform (CDP) software allows contact centers (and other business models, for that matter) to pull in customer data from any channel, system, or data stream to build a unified customer profile.
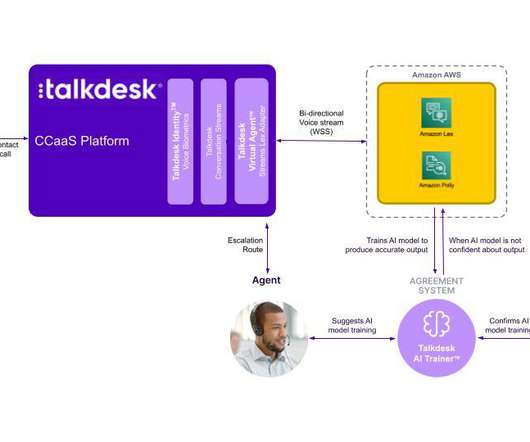
For more information, visit the Talkdesk Voice Biometric documentation. How Talkdesk integrates with Amazon Lex When the call reaches Talkdesk Virtual Agent , Talkdesk uses the continuous streaming capability of the Amazon Lex API to enable conversation with the Amazon Lex bot.
With MLSL’s expertise in ML consulting and execution, Schneider Electric was able to develop an AI architecture that would reduce the manual effort in their linking workflows, and deliver faster data access to their downstream analytics teams. These filings are available directly on SEC EDGAR or through CorpWatch API.
This is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API. It’s serverless, so you don’t have to manage any infrastructure.
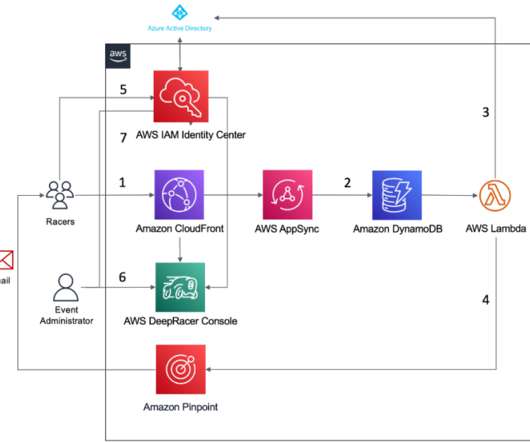
Consult your IdP’s documentation for more details. The event portal registration form calls a customer API endpoint that stores email addresses in Amazon DynamoDB through AWS AppSync. For more information, refer to Send email by using the Amazon Pinpoint API.
The TGI framework underpins the model inference layer, providing RESTful APIs for robust integration and effortless accessibility. Supplementing our auditory data processing, the Whisper ASR is also furnished with a RESTful API, enabling streamlined voice-to-text conversions. of OBELICS multimodal web documents.
In this post, we explore how companies can improve visibility into their models with centralized dashboards and detailed documentation of their models using two new features: SageMaker Model Cards and the SageMaker Model Dashboard. Both these features are available at no additional charge to SageMaker customers.
Amazon Kendra supports a variety of document formats , such as Microsoft Word, PDF, and text from various data sources. In this post, we focus on extending the document support in Amazon Kendra to make images searchable by their displayed content. USD Amazon Textract 100% detect document text on 10,000 images 15.00
Amazon Bedrock is a fully managed service that provides access to a range of high-performing foundation models from leading AI companies through a single API. The second component converts these extracted frames into vector embeddings directly by calling the Amazon Bedrock API with Amazon Titan Multimodal Embeddings.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content