This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, we guide you through integrating Amazon Bedrock Agents with enterprise data APIs to create more personalized and effective customer support experiences. An automotive retailer might use inventory management APIs to track stock levels and catalog APIs for vehicle compatibility and specifications.
However, there are benefits to building an FM-based classifier using an API service such as Amazon Bedrock, such as the speed to develop the system, the ability to switch between models, rapid experimentation for prompt engineering iterations, and the extensibility into other related classification tasks.
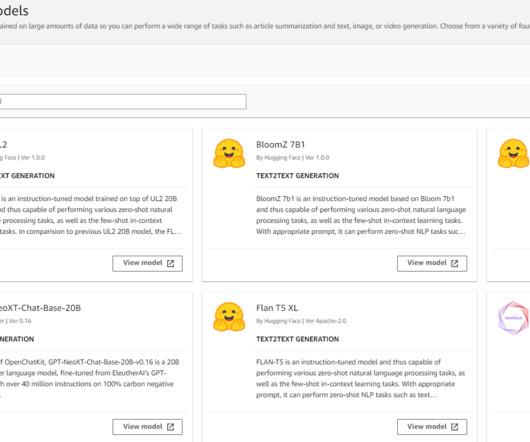
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
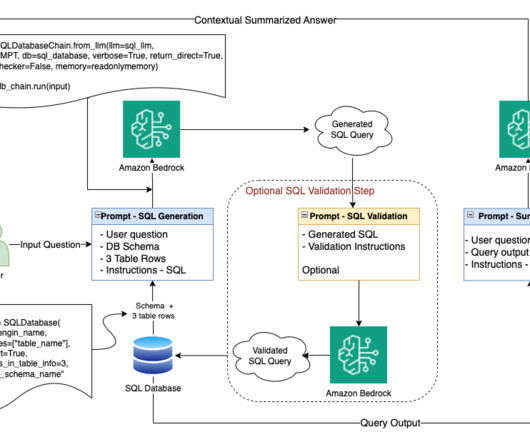
Solution overview Our solution implements a verified semantic cache using the Amazon Bedrock Knowledge Bases Retrieve API to reduce hallucinations in LLM responses while simultaneously improving latency and reducing costs. The function checks the semantic cache (Amazon Bedrock Knowledge Bases) using the Retrieve API.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
This requirement translates into time and effort investment of trained personnel, who could be support engineers or other technical staff, to review tens of thousands of support cases to arrive at an even distribution of 3,000 per category. Sonnet prediction accuracy through prompt engineering. client = boto3.client("bedrock-runtime",
Enabling Global Resiliency for an Amazon Lex bot is straightforward using the AWS Management Console , AWS Command Line Interface (AWS CLI), or APIs. Global Resiliency APIs Global Resiliency provides API support to create and manage replicas. To better understand the solution, refer to the following architecture diagram.
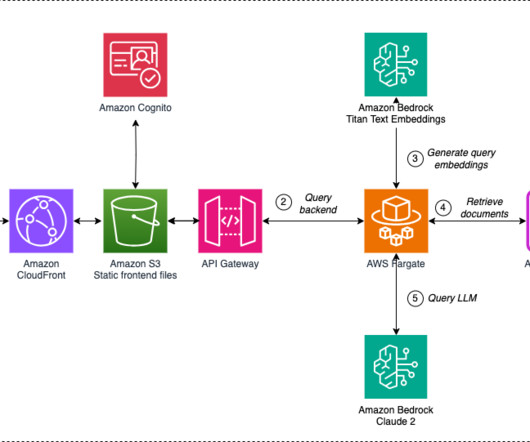
Amazon Bedrock is a fully managed service that makes a wide range of foundation models (FMs) available though an API without having to manage any infrastructure. An Amazon OpenSearch Serverless vector engine to store enterprise data as vectors to perform semantic search. The request is sent by the web application to the API.
We recommend running similar scripts only on your own data sources after consulting with the team who manages them, or be sure to follow the terms of service for the sources that youre trying to fetch data from. Solution overview The solution shown of integrating Alations business policies is for demonstration purposes only.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Designing a process from scratch is already a task and a half for your Salesforce org, but re-engineering a process is even a bigger undertaking when the process has been in use for some time. Much like “save early and save often”, proactively keep tabs on how a re-engineered process is received by users. Demo early, demo often.
From our experience, it is the framing phase that is the most time-consuming as you have to consult with all the teams involved in the project and obtain various approvals to start the developments. At Inbenta, it takes us an average of 8 weeks to deploy an AI chatbot, from the framing phase to the launch date. Poor technical documentation.
In the post Secure Amazon SageMaker Studio presigned URLs Part 2: Private API with JWT authentication , we demonstrated how to build a private API to generate Amazon SageMaker Studio presigned URLs that are only accessible by an authenticated end-user within the corporate network from a single account.
REAL TIME - Does your recording solution capture call audio in a real-time streaming manner so your transcription and analytics engine can process the call as it happens, or post-call? To learn more about the capabilities or inabilities of your current audio capture environment, click below for a free consultation. 7111 and OPUS?
The Amazon Lex fulfillment AWS Lambda function retrieves the Talkdesk touchpoint ID and Talkdesk OAuth secrets from AWS Secrets Manager and initiates a request to Talkdesk Digital Connect using the Start a Conversation API. If the request to the Talkdesk API is successful, a Talkdesk conversation ID is returned to Amazon Lex.
Designing a process from scratch is already a task and a half for your Salesforce org, but re-engineering a process is even a bigger undertaking when the process has been in use for some time. Much like “save early and save often”, proactively keep tabs on how a re-engineered process is received by users. Demo early, demo often.
Programmatic setup Alternatively, you can create your labeling job programmatically using the CreateLabelingJob API. Whether you choose the SageMaker console or API approach, the result is the same: a fully configured labeling job ready for your annotation team. documentation. When implementing additional Wavesurfer.js
The solution also uses Amazon Bedrock , a fully managed service that makes foundation models (FMs) from Amazon and third-party model providers accessible through the AWS Management Console and APIs. First, we discuss those two prompt engineering techniques, then we show their implementation using LangChain and Amazon Bedrock.
By the end of the consulting engagement, the team had implemented the following architecture that effectively addressed the core requirements of the customer team, including: Code Sharing – SageMaker notebooks enable data scientists to experiment and share code with other team members.
This is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API. There are many prompt engineering techniques. A prompt task is defined by prompt engineering.
It’s a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like Anthropic, Cohere, Meta, Mistral AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
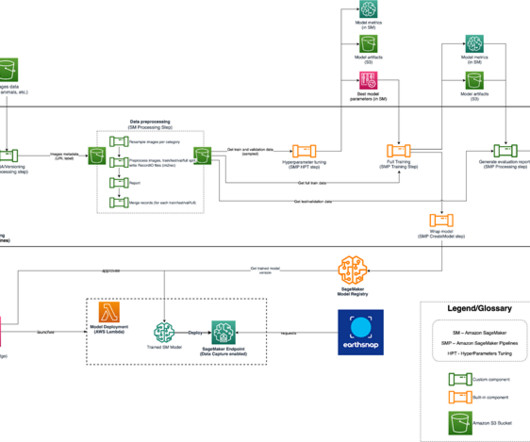
That is where Provectus , an AWS Premier Consulting Partner with competencies in Machine Learning, Data & Analytics, and DevOps, stepped in. Earth.com didn’t have an in-house ML engineering team, which made it hard to add new datasets featuring new species, release and improve new models, and scale their disjointed ML system.
You can now use cross-account support for Amazon SageMaker Pipelines to share pipeline entities across AWS accounts and access shared pipelines directly through Amazon SageMaker API calls. In the workflow, the data scientist and ML engineer perform the following steps: The data scientist (DS) builds a model pipeline in the dev account.
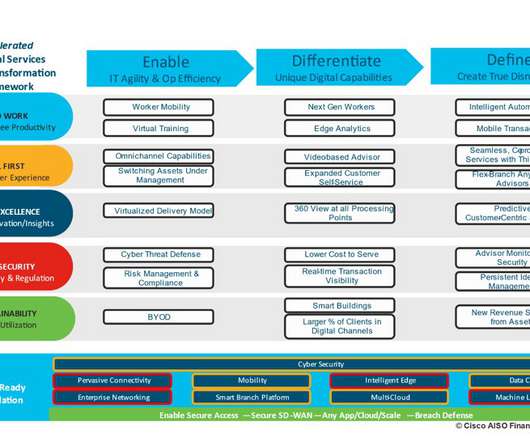
Xentaurs is a next generation consulting and Cisco digital solution integrator partner dedicated to making digital technology transformation a reality. Data breaches, ransomware and other modern cybersecurity threats have dramatically changed the challenges financial institutions and IT teams must solve.
The solution uses the following services: Amazon API Gateway is a fully managed service that makes it easy for developers to publish, maintain, monitor, and secure APIs at any scale. Purina’s solution is deployed as an API Gateway HTTP endpoint, which routes the requests to obtain pet attributes.
In the architecture shown in the following diagram, users input text in the React -based web app, which triggers Amazon API Gateway , which in turn invokes an AWS Lambda function depending on the bias in the user text. Additionally, it highlights the specific parts of your input text related to each category of bias.
You’ll need a Vonage API Account. Please take note of your accounts API Key, API Secret, and the number that comes with it. We have a couple that will handle the meta-data for the translation engine. We will need a method to stop the translation engine. Prerequisites. Buy a Number and Create Application.
We partnered with Keepler , a cloud-centered data services consulting company specialized in the design, construction, deployment, and operation of advanced public cloud analytics custom-made solutions for large organizations, in the creation of the first generative AI solution for one of our corporate teams.
Tobias has over 15 years of experience in customer care technology and the contact center industry with roles spanning engineering, consulting, pre-sales engineering, and product management/marketing. He leads product management for Nexmo, the Vonage API Platform. Twitter: @tpgoebel. Roland Selmer. Vice President Product.
This post was co-written with Anthony Medeiros, Manager of Solutions Engineering and Architecture for North America Artificial Intelligence, and Blake Santschi, Business Intelligence Manager, from Schneider Electric. These filings are available directly on SEC EDGAR or through CorpWatch API.
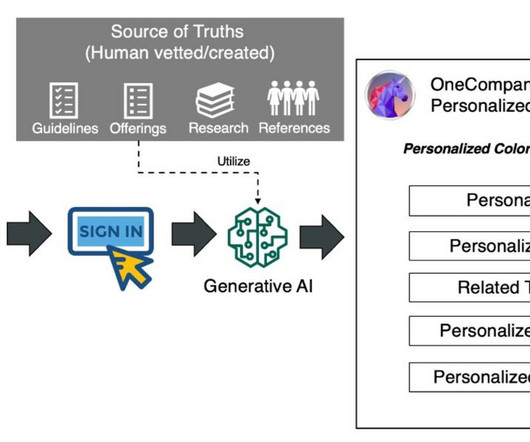
We present our solution through a fictional consulting company, OneCompany Consulting, using automatically generated personalized website content for accelerating business client onboarding for their consultancy service. For this post, we use Anthropic’s Claude models on Amazon Bedrock. Our core values are: 1.
Amazon Bedrock is fully serverless with no underlying infrastructure to manage extending access to available models through a single API. In Q4’s solution, we use Amazon Bedrock as a serverless, API-based, multi-foundation model building block. LangChain supports Amazon Bedrock as a multi-foundation model API.
The Retrieve and RetrieveAndGenerate APIs allow your applications to directly query the index using a unified and standard syntax without having to learn separate APIs for each different vector database, reducing the need to write custom index queries against your vector store.
Command R/R+ in Tool Use mode creates API payloads (JSONs with specific parameters) based on user interactions and conversational history. Prior to AWS, Pradeep has held various leadership positions at consulting companies such as Slalom, Deloitte, and Wipro. Pradeep holds a Bachelor’s degree in Engineering and is based in Dallas, TX.
Tobias has over 15 years of experience in customer care technology and the contact center industry with roles spanning engineering, consulting, pre-sales engineering, and product management/marketing. He leads product management for Nexmo, the Vonage API Platform. Twitter: @tpgoebel. Roland Selmer. Vice President Product.
If you want to learn more about this use case or have a consultative session with the Mission team to review your specific generative AI use case, feel free to request one through AWS Marketplace. in Mechanical Engineering from the University of Notre Dame. Yaoqi Zhang is a Senior Big Data Engineer at Mission Cloud.
Since its launch a few months ago, the Visual Intelligence Platform has delivered analysis and insights within both TechSee’s products and via API integrations into third-party solutions like chatbots or workflows. Today’s mobile devices, even budget devices, pack incredible processing power.
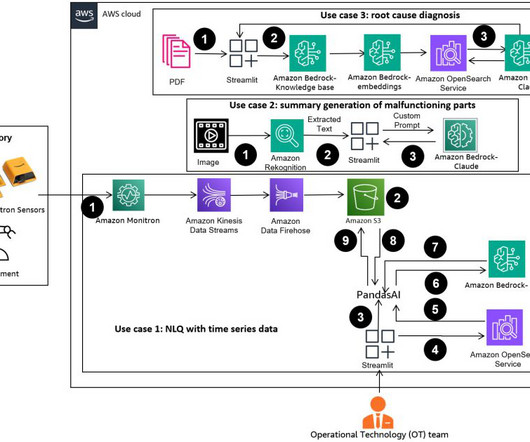
Workers gain productivity through AI-generated insights, engineers can proactively detect anomalies, supply chain managers optimize inventories, and plant leadership makes informed, data-driven decisions. The user can use the Amazon Recognition DetectText API to extract text data from these images.
The AI platform team’s key objective is to ensure seamless access to Workbench services and SageMaker Studio for all Deutsche Bahn teams and projects, with a primary focus on data scientists and ML engineers. The AI platform managed service, built on SageMaker Studio, seamlessly aligns with Deutsche Bahn’s group-wide platform strategy.
Data Wrangler simplifies the data preparation and feature engineering process, reducing the time it takes from weeks to minutes by providing a single visual interface for data scientists to select and clean data, create features, and automate data preparation in ML workflows without writing any code. Configure Snowflake.
The workflow starts with a request to an API endpoint hosted on Amazon API Gateway originating from a claims management system, which invokes an AWS Step Functions workflow that uses AWS Lambda to complete the following steps: The input data of the REST API request is transformed into encoded features, which is utilized by the ML model.
Q: What about finding all of the skilled engineers required to train computer vision models? Our engine will then auto-tag every subsequent frame. All the user needs to do is to review the tags assigned by the engine. Furthermore, VI’s APIs make these AI insights instantly available across any business application.
Our latest product innovation, Transaction Risk API , was specifically built for easy integration into sophisticated machine learning (ML) models and is designed to help eCommerce merchants, marketplaces, payment processors, and others manage payment fraud. Transaction Risk API delivers a response within 100 ms to meet this need.
The router initiates an open session (this API is defined by the client; it could be some other name like start_session ) with the model server, in this case TorchServe, and responds back with 200 OK along with the session ID and time to live (TTL), which is sent back to the client. Lingran Xia is a software development engineer at AWS.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content