This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Many organizations have been using a combination of on-premises and open source data science solutions to create and manage machine learning (ML) models. Data science and DevOps teams may face challenges managing these isolated tool stacks and systems.
Data-driven decisions fueled by near-real-time insights can enable farmers to close the gap on increased food demand. However, scouting each field on a frequent basis for large fields and farms is not feasible, and successful risk mitigation requires an integrated agronomic data platform that can bring insights at scale.
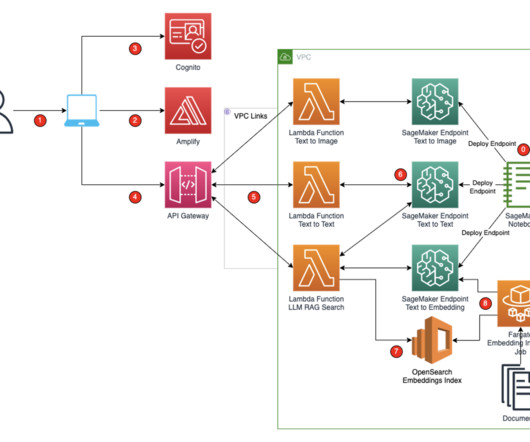
It’s powered by large language models (LLMs) that are pre-trained on vast amounts of data and commonly referred to as foundation models (FMs). These SageMaker endpoints are consumed in the Amplify React application through Amazon API Gateway and AWS Lambda functions. This dataset is a large corpus of legal and administrative data.
Identifying, collecting, and transforming data is the foundation for machine learning (ML). According to a Forbes survey , there is widespread consensus among ML practitioners that data preparation accounts for approximately 80% of the time spent in developing a viable ML model. Overview of solution.
Accenture built a regulatory document authoring solution using automated generative AI that enables researchers and testers to produce CTDs efficiently. By extracting key data from testing reports, the system uses Amazon SageMaker JumpStart and other AWS AI services to generate CTDs in the proper format.
This new feature enables organizations to process large volumes of data when interacting with foundation models (FMs), addressing a critical need in various industries, including call center operations. As the volume of call data grows, traditional analysis methods struggle to keep pace, creating a demand for a scalable solution.
Bosch is a multinational corporation with entities operating in multiple sectors, including automotive, industrialsolutions, and consumer goods. Because neural forecasters are trained on historical data, the forecasts generated based on out-of-distribution data from the more volatile periods could be inaccurate and unreliable.
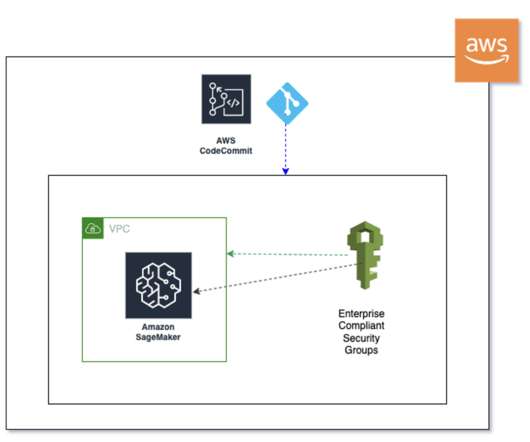
With the increasing use of artificial intelligence (AI) and machine learning (ML) for a vast majority of industries (ranging from healthcare to insurance, from manufacturing to marketing), the primary focus shifts to efficiency when building and training models at scale. Navigate to the AWS Cloud9 console.
Inefficient Business Processes: Complex approval chains, inconsistent data, and convoluted system workflows slow down sales. Sales data gets scattered across systems. Different processes and data formats make consolidation difficult. Centralized Pricing Management: Pricing data gets consolidated within CPQ.
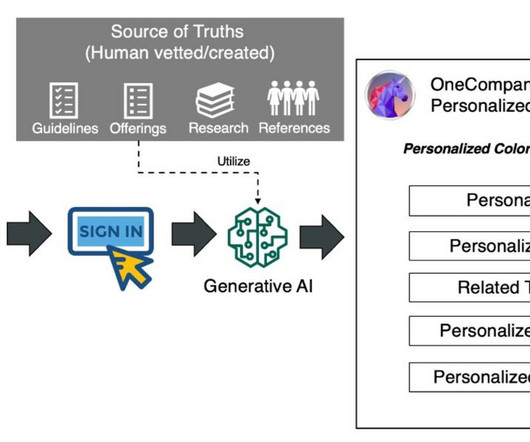
We employed other LLMs available on Amazon Bedrock to synthetically generate fictitious reference materials to avoid potential biases that could arise from Amazon Claude’s pre-training data. Nonetheless, our solution can still be utilized. Construction Technology Solutions - Construction Data Analytics and Reporting.
Amazon SageMaker is a fully managed service to prepare data and build, train, and deploy machine learning (ML) models for any use case with fully managed infrastructure, tools, and workflows. You then can directly deploy the model to production with just one click or iterate on the recommended solutions to further improve the model quality.
This feature empowers customers to import and use their customized models alongside existing foundation models (FMs) through a single, unified API. Having a unified developer experience when accessing custom models or base models through Amazon Bedrock’s API. The training data must be formatted in a JSON Lines (.jsonl)
GuardDuty combines machine learning (ML), anomaly detection, and malicious file discovery, using both AWS and industry-leading third-party sources, to help protect AWS accounts, workloads, and data. Generative AI can make predictions about future security threats or attacks by analyzing historical security data and trends.
These large language models (LLMs) are trained on a vast amount of data from various domains and languages. Solution overview This post outlines a custom multilingual document extraction and content assessment framework using a combination of Anthropic’s Claude 3 on Amazon Bedrock and Amazon A2I to incorporate human-in-the-loop capabilities.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content