This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Bedrock announces the preview launch of Session Management APIs, a new capability that enables developers to simplify state and context management for generative AI applications built with popular open source frameworks such as LangGraph and LlamaIndex. Building generative AI applications requires more than model API calls.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. API Gateway is serverless and hence automatically scales with traffic. API Gateway also provides a WebSocket API. At this point, you need to consider the use case and data isolation requirements.
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. For the multiclass classification problem to label support case data, synthetic data generation can quickly result in overfitting.
Concerns about legal implications, accuracy of AI-generated outputs, data privacy, and broader societal impacts have underscored the importance of responsible AI development. This can be useful when you have requirements for sensitive data handling and user privacy.
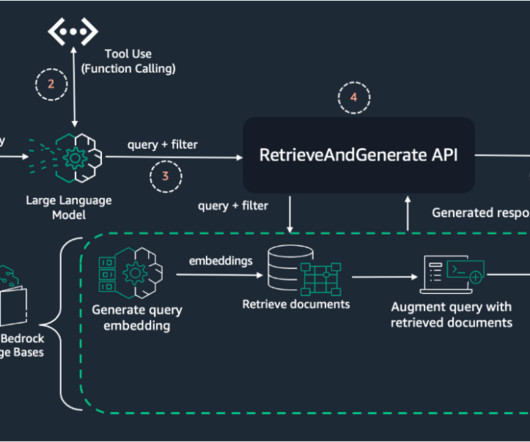
One of the most critical applications for LLMs today is Retrieval Augmented Generation (RAG), which enables AI models to ground responses in enterprise knowledge bases such as PDFs, internal documents, and structured data. How do Amazon Nova Micro and Amazon Nova Lite perform against GPT-4o mini in these same metrics?
Furthermore, evaluation processes are important not only for LLMs, but are becoming essential for assessing prompt template quality, input data quality, and ultimately, the entire application stack. SageMaker is a data, analytics, and AI/ML platform, which we will use in conjunction with FMEval to streamline the evaluation process.
All of this data is centralized and can be used to improve metrics in scenarios such as sales or call centers. These insights are stored in a central repository, unlocking the ability for analytics teams to have a single view of interactions and use the data to formulate better sales and support strategies.
Recently, we’ve been witnessing the rapid development and evolution of generative AI applications, with observability and evaluation emerging as critical aspects for developers, data scientists, and stakeholders. This feature allows you to separate data into logical partitions, making it easier to analyze and process data later.
This approach allows organizations to assess their AI models effectiveness using pre-defined metrics, making sure that the technology aligns with their specific needs and objectives. This format promotes proper processing of evaluation data. Both features use the LLM-as-a-judge technique behind the scenes but evaluate different things.
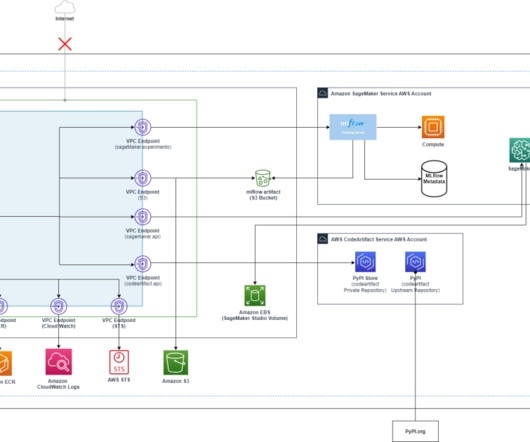
In the initial stages of an ML project, data scientists collaborate closely, sharing experimental results to address business challenges. However, keeping track of numerous experiments, their parameters, metrics, and results can be difficult, especially when working on complex projects simultaneously.
With GraphStorm, you can build solutions that directly take into account the structure of relationships or interactions between billions of entities, which are inherently embedded in most real-world data, including fraud detection scenarios, recommendations, community detection, and search/retrieval problems. Specifically, GraphStorm 0.3
In the rapidly evolving landscape of artificial intelligence, Retrieval Augmented Generation (RAG) has emerged as a game-changer, revolutionizing how Foundation Models (FMs) interact with organization-specific data. More sophisticated metrics are needed to evaluate factual alignment and accuracy.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
The opportunities to unlock value using AI in the commercial real estate lifecycle starts with data at scale. Although CBRE provides customers their curated best-in-class dashboards, CBRE wanted to provide a solution for their customers to quickly make custom queries of their data using only natural language prompts.
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. The chatbot improved access to enterprise data and increased productivity across the organization.
Automated safety guards Integrated Amazon CloudWatch alarms monitor metrics on an inference component. AlarmName This CloudWatch alarm is configured to monitor metrics on an InferenceComponent. For more information about the SageMaker AI API, refer to the SageMaker AI API Reference.
During these live events, F1 IT engineers must triage critical issues across its services, such as network degradation to one of its APIs. This impacts downstream services that consume data from the API, including products such as F1 TV, which offer live and on-demand coverage of every race as well as real-time telemetry.
Many organizations have been using a combination of on-premises and open source data science solutions to create and manage machine learning (ML) models. Data science and DevOps teams may face challenges managing these isolated tool stacks and systems.
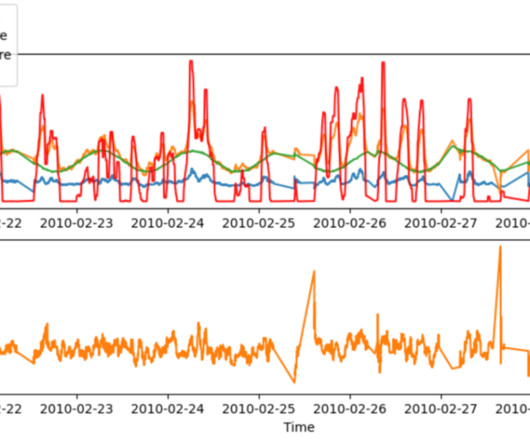
Amazon Lookout for Metrics is a fully managed service that uses machine learning (ML) to detect anomalies in virtually any time-series business or operational metrics—such as revenue performance, purchase transactions, and customer acquisition and retention rates—with no ML experience required.
This serves as an example of how generative AI can streamline operations that involve diverse data types and formats. Rule-based systems or specialized machine learning (ML) models often struggle with the variability of real-world documents, especially when dealing with semi-structured and unstructured data.
To effectively optimize AI applications for responsiveness, we need to understand the key metrics that define latency and how they impact user experience. These metrics differ between streaming and nonstreaming modes and understanding them is crucial for building responsive AI applications.
In the context of generative AI , significant progress has been made in developing multimodal embedding models that can embed various data modalities—such as text, image, video, and audio data—into a shared vector space. Each data point in the database is associated with a vector that encapsulates its attributes or features.
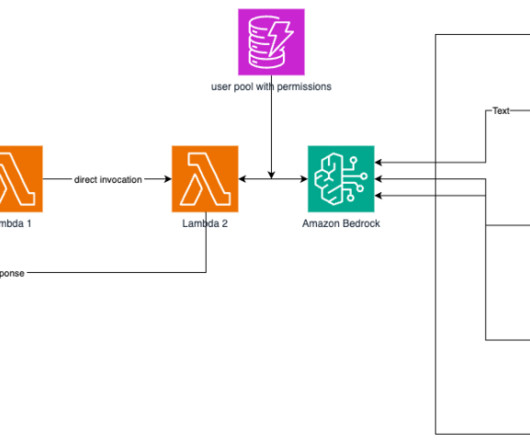
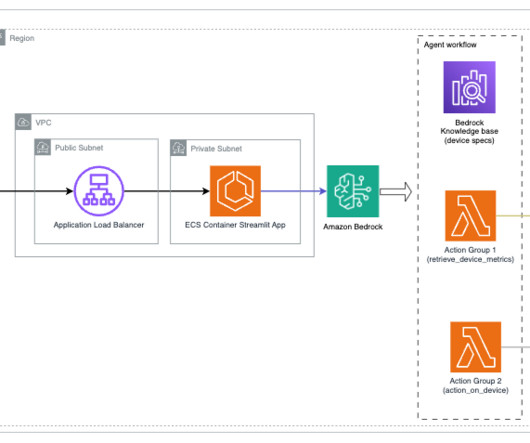
These agents help users complete actions based on organizational data and user input, orchestrating interactions between foundation models (FMs), data sources, software applications, and user conversations. Amazon Bedrock Agents offers developers the ability to build and configure autonomous agents in their applications.
It enables you to privately customize the FM of your choice with your data using techniques such as fine-tuning, prompt engineering, and retrieval augmented generation (RAG) and build agents that run tasks using your enterprise systems and data sources while adhering to security and privacy requirements.
Meraki APIs allow businesses to automate repetitive and time-consuming tasks, and configure and deploy networks quickly at a scale. Developrs can leverage API operations to retrieve performance metrics, monitor network health, analyze traffic data and create custom reports to gain insights into the network usage.
At The Very Group , which operates digital retailer Very, security is a top priority in handling data for millions of customers. However, this can mean processing customer data in the form of personally identifiable information (PII) in relation to activities such as purchases, returns, use of flexible payment options, and account management.
Although automated metrics are fast and cost-effective, they can only evaluate the correctness of an AI response, without capturing other evaluation dimensions or providing explanations of why an answer is problematic. Human evaluation, although thorough, is time-consuming and expensive at scale.
Performance metrics and benchmarks Pixtral 12B is trained to understand both natural images and documents, achieving 52.5% You can find detailed usage instructions, including sample API calls and code snippets for integration. In this particular use case, we use Pixtral 12B to analyze an intricate image containing GDP data.
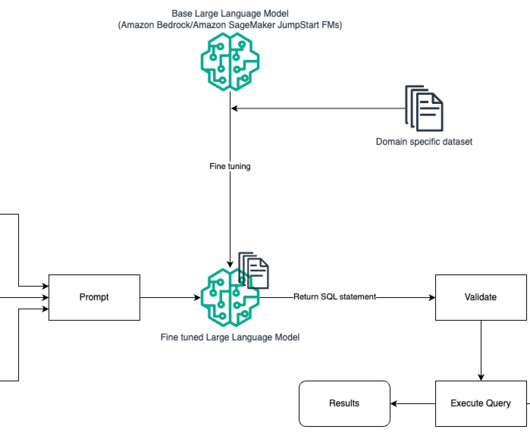
One such area that is evolving is using natural language processing (NLP) to unlock new opportunities for accessing data through intuitive SQL queries. Instead of dealing with complex technical code, business users and data analysts can ask questions related to data and insights in plain language.
In this post, we discuss the key elements needed to evaluate the performance aspect of a content moderation service in terms of various accuracy metrics, and a provide an example using Amazon Rekognition Content Moderation API’s. To annotate your image data, you can use Amazon SageMaker Ground Truth (GT)to manage image annotation.
With the use of cloud computing, big data and machine learning (ML) tools like Amazon Athena or Amazon SageMaker have become available and useable by anyone without much effort in creation and maintenance. This dilemma hampers the creation of efficient models that use data to generate business-relevant insights.
To build a generative AI -based conversational application integrated with relevant data sources, an enterprise needs to invest time, money, and people. First, you would need build connectors to the data sources. For a full list of supported data source connectors, see Amazon Q Business connectors.
Fine-tuning pre-trained language models allows organizations to customize and optimize the models for their specific use cases, providing better performance and more accurate outputs tailored to their unique data and requirements. Amazon Bedrock prioritizes security through a comprehensive approach to protect customer data and AI workloads.
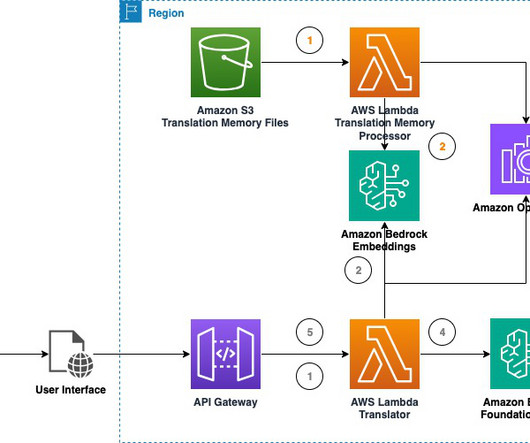
It can help collect more data on the value of LLMs for your content translation use cases. Translation Memory eXchange (TMX) is a widely used open standard for representing and exchanging TM data. Also note the completion metrics on the left pane, displaying latency, input/output tokens, and quality scores.
This post shows you how to use an integrated solution with Amazon Lookout for Metrics to break these barriers by quickly and easily detecting anomalies in the key performance indicators (KPIs) of your interest. Lookout for Metrics automatically detects and diagnoses anomalies (outliers from the norm) in business and operational data.
However, scaling up generative AI and making adoption easier for different lines of businesses (LOBs) comes with challenges around making sure data privacy and security, legal, compliance, and operational complexities are governed on an organizational level. In this post, we discuss how to address these challenges holistically.
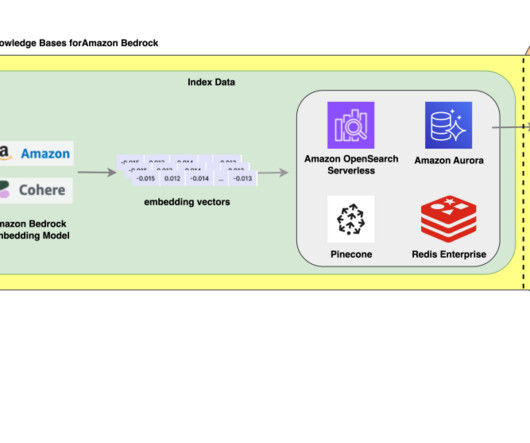
RAG is the process of optimizing the output of an LLM so it references an authoritative knowledge base outside of its training data sources before generating a response. RAG also scales better with more data compared to pure generative models, and it doesn’t require fine-tuning of the model when new data is added to the knowledge base.
Our commitment to innovation led us to a pivotal challenge: how to harness the power of machine learning (ML) to further enhance our competitive edge while balancing this technological advancement with strict data security requirements and the need to streamline access to our existing internal resources.
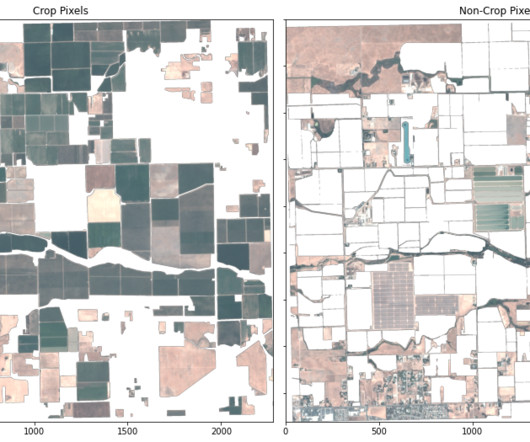
This guest post is co-written by Lydia Lihui Zhang, Business Development Specialist, and Mansi Shah, Software Engineer/Data Scientist, at Planet Labs. In late 2023, Planet announced a partnership with AWS to make its geospatial data available through Amazon SageMaker.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon using a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
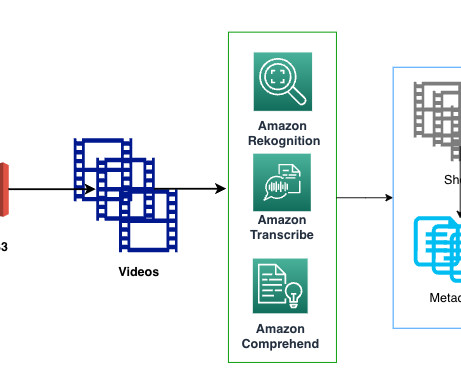
We match the most relevant videos to text-based search queries by incorporating new multimodal embedding models like Amazon Titan Multimodal Embeddings to encode all visual, visual-meta, and transcription data. Amazon Transcribe The transcription for the entire video is generated using the StartTranscriptionJob API.
Frontier large language models (LLMs) like Anthropic Claude on Amazon Bedrock are trained on vast amounts of data, allowing Anthropic Claude to understand and generate human-like text. The fine-tuning as a deep level of customization represents a key differentiating factor by using your own unique data.
Such use cases, which augment a large language model’s (LLM) knowledge with external data sources, are known as Retrieval-Augmented Generation (RAG). The second post outlines how to work with multiple data formats such as structured data (tables, databases) and images. doc,pdf, or.txt).
Performance metrics and benchmarks According to Mistral, the instruction-tuned version of the model achieves over 81% accuracy on Massive Multitask Language Understanding (MMLU) with 150 tokens per second latency, making it currently the most efficient model in its category. It doesnt support Converse APIs or other Amazon Bedrock tooling.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content