This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
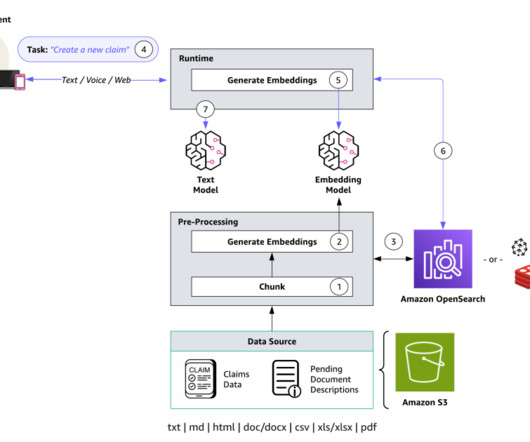
The solution integrates large language models (LLMs) with your organization’s data and provides an intelligent chat assistant that understands conversation context and provides relevant, interactive responses directly within the Google Chat interface. The following figure illustrates the high-level design of the solution.
One of the most critical applications for LLMs today is Retrieval Augmented Generation (RAG), which enables AI models to ground responses in enterprise knowledge bases such as PDFs, internal documents, and structured data. These five webpages act as a knowledge base (source data) to limit the RAG models response. get("message", {}).get("content")
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. For the multiclass classification problem to label support case data, synthetic data generation can quickly result in overfitting.
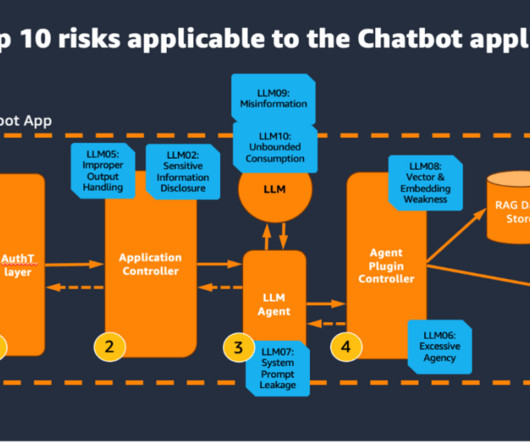
These steps might involve both the use of an LLM and external data sources and APIs. Agent plugin controller This component is responsible for the API integration to external data sources and APIs. Amazon Cognito complements these defenses by enabling user authentication and data synchronization.
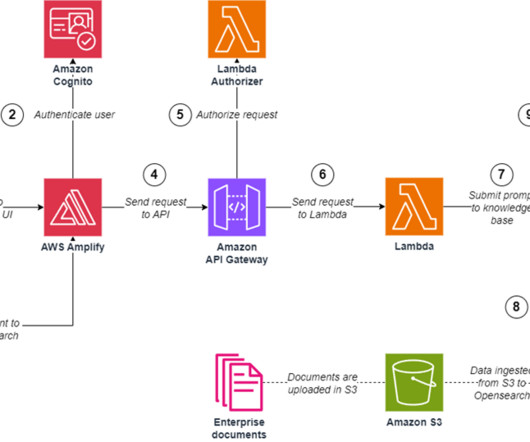
The solution also uses Amazon Cognito user pools and identity pools for managing authentication and authorization of users, Amazon API Gateway REST APIs, AWS Lambda functions, and an Amazon Simple Storage Service (Amazon S3) bucket. To launch the solution in a different Region, change the aws_region parameter accordingly.
Concerns about legal implications, accuracy of AI-generated outputs, data privacy, and broader societal impacts have underscored the importance of responsible AI development. This can be useful when you have requirements for sensitive data handling and user privacy.
Amazon Bedrock is a fully managed service that makes FMs from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. One consistent pain point of fine-tuning is the lack of data to effectively customize these models.
By using the power of LLMs and combining them with specialized tools and APIs, agents can tackle complex, multistep tasks that were previously beyond the reach of traditional AI systems. Whenever local database information is unavailable, it triggers an online search using the Tavily API.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon with a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Many organizations have been using a combination of on-premises and open source data science solutions to create and manage machine learning (ML) models. Data science and DevOps teams may face challenges managing these isolated tool stacks and systems.
The opportunities to unlock value using AI in the commercial real estate lifecycle starts with data at scale. Although CBRE provides customers their curated best-in-class dashboards, CBRE wanted to provide a solution for their customers to quickly make custom queries of their data using only natural language prompts.
With the rise of generative artificial intelligence (AI), an increasing number of organizations use digital assistants to have their end-users ask domain-specific questions, using Retrieval Augmented Generation (RAG) over their enterprise data sources. The request is sent by the web application to the API.
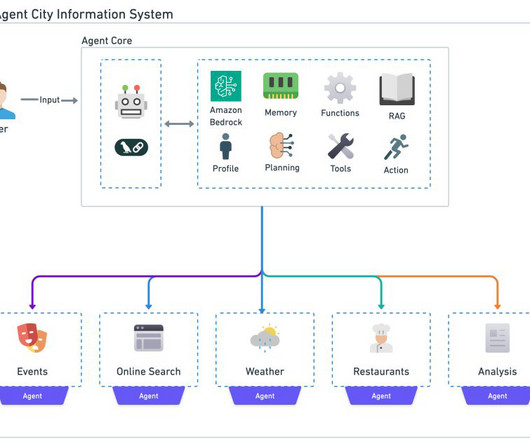
These agents help users complete actions based on organizational data and user input, orchestrating interactions between foundation models (FMs), data sources, software applications, and user conversations. Amazon Bedrock Agents offers developers the ability to build and configure autonomous agents in their applications.
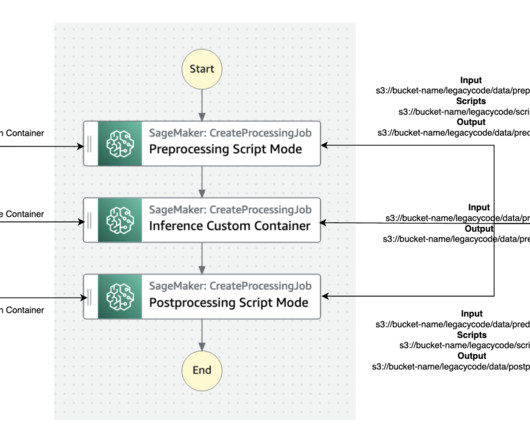
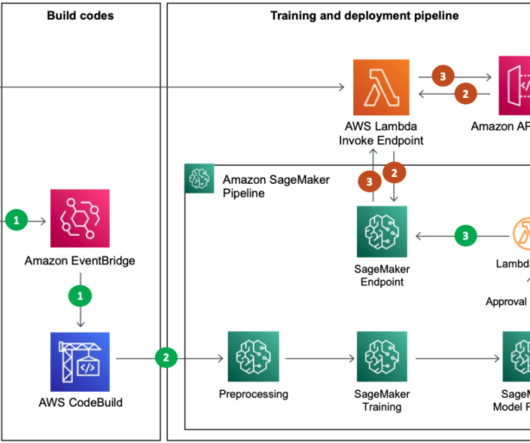
The best practice for migration is to refactor these legacy codes using the Amazon SageMaker API or the SageMaker Python SDK. We demonstrate how two different personas, a data scientist and an MLOps engineer, can collaborate to lift and shift hundreds of legacy models. SageMaker runs the legacy script inside a processing container.
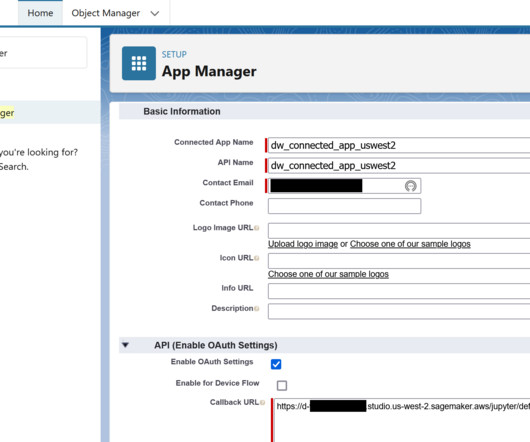
In this post, we show how to configure a new OAuth-based authentication feature for using Snowflake in Amazon SageMaker Data Wrangler. Snowflake is a cloud data platform that provides data solutions for data warehousing to data science. For more information about prerequisites, see Get Started with Data Wrangler.
Amazon Comprehend is a fully managed service that can perform NLP tasks like custom entity recognition, topic modelling, sentiment analysis and more to extract insights from data without the need of any prior ML experience. Build your training script for the Hugging Face SageMaker estimator. return tokenized_dataset. to(device).
These agents excel at automating a wide range of routine and repetitive tasks, such as data entry, customer support inquiries, and content generation. These managed agents play conductor, orchestrating interactions between FMs, API integrations, user conversations, and knowledge sources loaded with your data.
These customers need to balance governance, security, and compliance against the need for machine learning (ML) teams to quickly access their data science environments in a secure manner. The workflow steps are as follows: The user authenticates with the Amazon Cognito user pool and receives a token to consume the Studio access API.
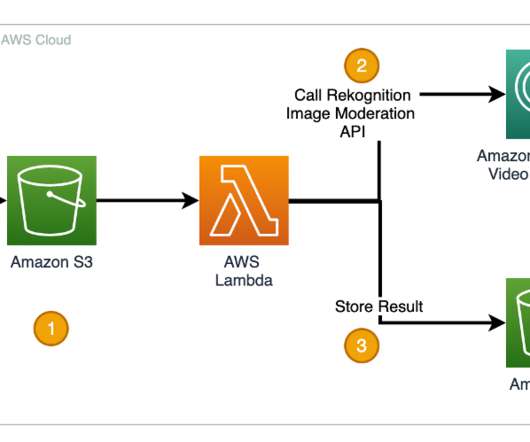
Amazon Rekognition has two sets of APIs that help you moderate images or videos to keep digital communities safe and engaged. One approach to moderate videos is to model video data as a sample of image frames and use image content moderation models to process the frames individually.
To build a generative AI -based conversational application integrated with relevant data sources, an enterprise needs to invest time, money, and people. First, you would need build connectors to the data sources. For a full list of supported data source connectors, see Amazon Q Business connectors.
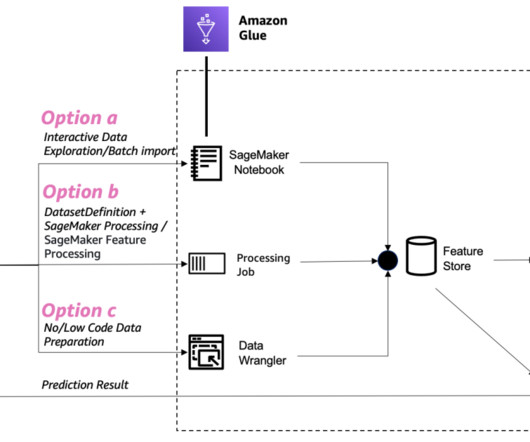
If you use the default lifecycle configuration for your domain or user profile in Amazon SageMaker Studio and use Amazon SageMaker Data Wrangler for data preparation, then this post is for you. Data Wrangler supports standard data types such as CSV, JSON, ORC, and Parquet. For more information, see Jupyter Kernel Gateway.
Highly accurate LLMs can require terabytes of training data and thousands or even millions of hours of accelerator compute time to achieve target accuracy. With this latest major version release of SMP, the library simplifies the user experience by aligning its APIs with open source PyTorch.
This is the second post in a series discussing the integration of Salesforce Data Cloud and Amazon SageMaker. The endpoints are then registered to the Salesforce Data Cloud to activate predictions in Salesforce. To use this dataset in your Data Cloud, refer to Create Amazon S3 Data Stream in Data Cloud.
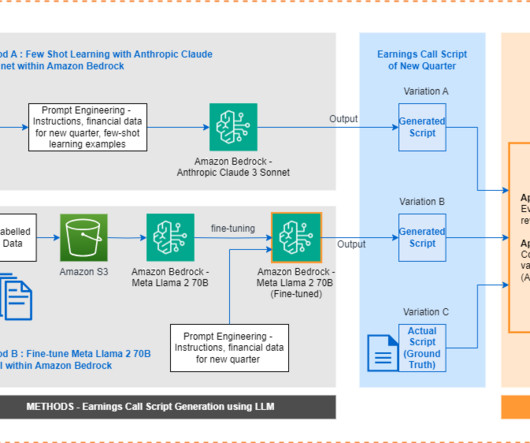
Traditionally, earnings call scripts have followed similar templates, making it a repeatable task to generate them from scratch each time. On the other hand, generative artificial intelligence (AI) models can learn these templates and produce coherent scripts when fed with quarterly financial data.
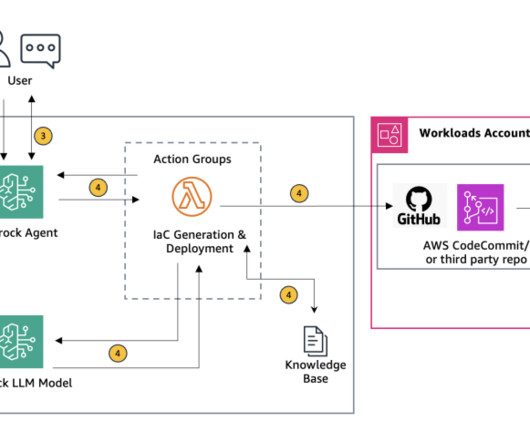
This solution uses Retrieval Augmented Generation (RAG) to ensure the generated scripts adhere to organizational needs and industry standards. In this blog post, we explore how Agents for Amazon Bedrock can be used to generate customized, organization standards-compliant IaC scripts directly from uploaded architecture diagrams.
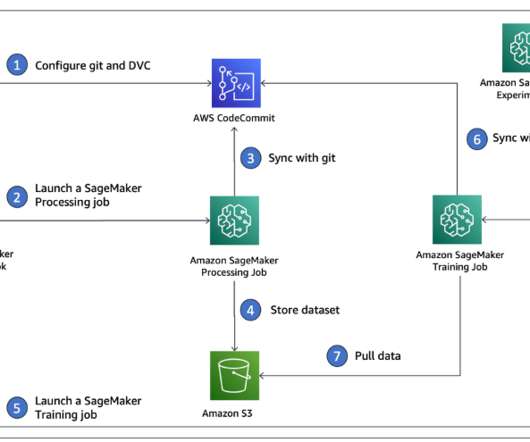
Data scientists often work towards understanding the effects of various data preprocessing and feature engineering strategies in combination with different model architectures and hyperparameters. Data Version Control. These placeholders point to the original data, which is decoupled from source code management.
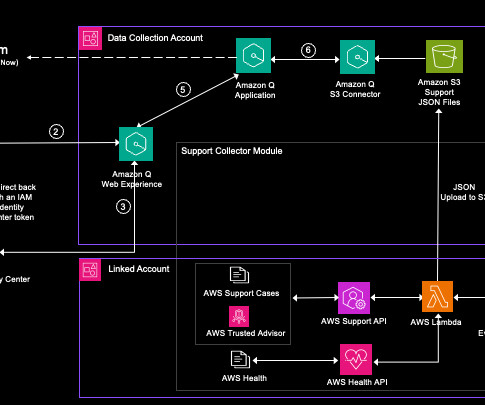
This post shows how to use AWS generative artificial intelligence (AI) services , like Amazon Q Business , with AWS Support cases, AWS Trusted Advisor , and AWS Health data to derive actionable insights based on common patterns, issues, and resolutions while using the AWS recommendations and best practices enabled by support data.
Therefore, we decided to introduce a deep learning-based recommendation algorithm that can identify not only linear relationships in the data, but also more complex relationships. The preprocessing data is loaded into MongoDB, which is used as a feature store along with Amazon S3.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API. The scripts for fine-tuning and evaluation are available on the GitHub repository.
Vonage API Account. To complete this tutorial, you will need a Vonage API account. Once you have an account, you can find your API Key and API Secret at the top of the Vonage API Dashboard. Web Component polyfill --> <script src="[link]. <!-- This tutorial also uses a virtual phone number.
However, they’re unable to gain insights such as using the information locked in the documents for large language models (LLMs) or search until they extract the text, forms, tables, and other structured data. In the following sections, we first describe the script solution, followed by the AWS CDK construct solution.
Amazon Redshift is the most popular cloud data warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. It provides a single web-based visual interface where you can perform all ML development steps, including preparing data and building, training, and deploying models.
Here are some features which we will cover: AWS CloudFormation support Private network policies for Amazon OpenSearch Serverless Multiple S3 buckets as data sources Service Quotas support Hybrid search, metadata filters, custom prompts for the RetreiveAndGenerate API, and maximum number of retrievals.
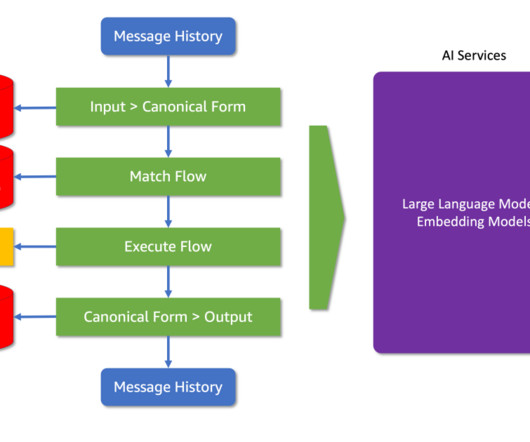
Incorporating your Data into the Conversation to provide factual, grounded responses aligned with your use case goals using retrieval augmented generation or by invoking functions as tools. Retrieval and Execution Rails: These govern how the AI interacts with external tools and data sources. define bot express greeting "Hey there!"
Data scientists and machine learning engineers are constantly looking for the best way to optimize their training compute, yet are struggling with the communication overhead that can increase along with the overall cluster size. speed up compared to PyTorch’s Fully Sharded Data Parallel (FSDP). on 256 GPUs.
Such use cases, which augment a large language model’s (LLM) knowledge with external data sources, are known as Retrieval-Augmented Generation (RAG). The second post outlines how to work with multiple data formats such as structured data (tables, databases) and images. doc,pdf, or.txt).
Knowledge Bases for Amazon Bedrock automates synchronization of your data with your vector store, including diffing the data when it’s updated, document loading, and chunking, as well as semantic embedding. RAG is a popular technique that combines the use of private data with large language models (LLMs).
In this blog post and open source project , we show you how you can pre-train a genomics language model, HyenaDNA , using your genomic data in the AWS Cloud. Genomic language models Genomic language models represent a new approach in the field of genomics, offering a way to understand the language of DNA.
This post introduces a best practice for managing custom code within your Amazon SageMaker Data Wrangler workflow. Data Wrangler is a low-code tool that facilitates data analysis, preprocessing, and visualization. This post shows how you can use code stored in AWS CodeCommit in the Data Wrangler custom transform step.
Amazon Rekognition makes it easy to add image analysis capability to your applications without any machine learning (ML) expertise and comes with various APIs to fulfil use cases such as object detection, content moderation, face detection and analysis, and text and celebrity recognition, which we use in this example.
However, as a new product in a new space for Amazon, Amp needed more relevant data to inform their decision-making process. Part 1 shows how data was collected and processed using the data and analytics platform, and Part 2 shows how the data was used to create show recommendations using Amazon SageMaker , a fully managed ML service.
This is the second part of a series that showcases the machine learning (ML) lifecycle with a data mesh design pattern for a large enterprise with multiple lines of business (LOBs) and a Center of Excellence (CoE) for analytics and ML. In this post, we address the analytics and ML platform team as a consumer in the data mesh.
R is a popular analytic programming language used by data scientists and analysts to perform data processing, conduct statistical analyses, create data visualizations, and build machine learning (ML) models. The following screenshot shows an example of the data: Fig4: COVID-19 Public dataset.
With this architecture, the experts specialize in processing different aspects of the input data. During training, different data is routed to the different devices, with each device handling the computation for the experts it contains. A trainable gate network called a router determines which input tokens are sent to which expert.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




































Let's personalize your content