This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Evaluation algorithm Computes evaluation metrics to model outputs. Different algorithms have different metrics to be specified. It functions as a standalone HTTP server that provides various REST API endpoints for monitoring, recording, and visualizing experiment runs. This allows you to keep track of your ML experiments.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
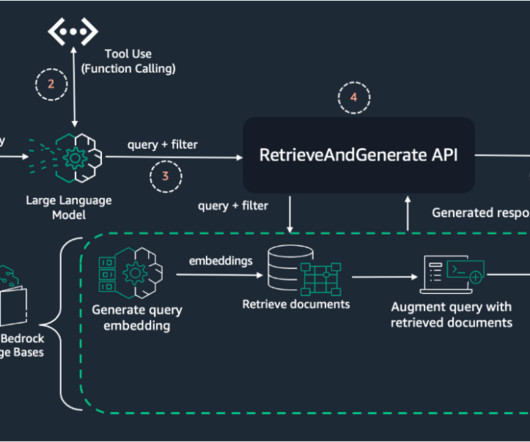
The solution uses the FMs tool use capabilities, accessed through the Amazon Bedrock Converse API. This enables the FMs to not just process text, but to actively engage with various external tools and APIs to perform complex document analysis tasks. For more details on how tool use works, refer to The complete tool use workflow.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Where discrete outcomes with labeled data exist, standard ML methods such as precision, recall, or other classic ML metrics can be used. These metrics provide high precision but are limited to specific use cases due to limited ground truth data. If the use case doesnt yield discrete outputs, task-specific metrics are more appropriate.
In February 2022, Amazon Web Services added support for NVIDIA GPU metrics in Amazon CloudWatch , making it possible to push metrics from the Amazon CloudWatch Agent to Amazon CloudWatch and monitor your code for optimal GPU utilization. Then we explore two architectures. already installed. eks-create.sh 19 private:192.168.128.0/19
Amazon Bedrock agents use LLMs to break down tasks, interact dynamically with users, run actions through API calls, and augment knowledge using Amazon Bedrock Knowledge Bases. In this post, we demonstrate how to use Amazon Bedrock Agents with a web search API to integrate dynamic web content in your generative AI application.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
In this post, we discuss the key elements needed to evaluate the performance aspect of a content moderation service in terms of various accuracy metrics, and a provide an example using Amazon Rekognition Content Moderation API’s. What to evaluate. When evaluating a content moderation service, we recommend the following steps.
The user’s request is sent to AWS API Gateway , which triggers a Lambda function to interact with Amazon Bedrock using Anthropic’s Claude Instant V1 FM to process the user’s request and generate a natural language response of the place location. The class definition is similar to the LangChain ConversationalChatAgent class.
The deployment of agentic systems should focus on well-defined processes with clear success metrics and where there is potential for greater flexibility and less brittleness in process management. You can deploy or fine-tune models through an intuitive UI or APIs, providing flexibility for all skill levels.
Customer Effort Score is a metric, which customer service teams are using to evaluate how easy customers thought it was to get a resolution to their recent contact. The Customer Effort Score metric grew out of a desire to measure the amount of effort customers were experiencing in their service interactions. And the metric works.
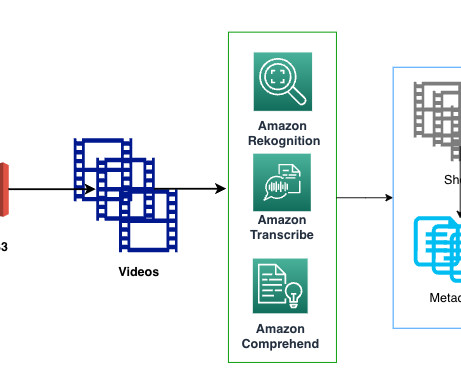
Amazon Transcribe The transcription for the entire video is generated using the StartTranscriptionJob API. The solution runs Amazon Rekognition APIs for label detection , text detection, celebrity detection , and face detection on videos. The metadata generated for each video by the APIs is processed and stored with timestamps.
Forecasting Core Features The Ability to Consume Historical Data Whether it’s from a copy/paste of a spreadsheet or an API connection, your WFM platform must have the ability to consume historical data. Scheduling Core Features Matching Schedules to Forecasted Volume The common definition of WFM is “right people, right place, right time”.
The following figure shows schema definition and model which reference it. It provides a unified interface for logging parameters, code versions, metrics, and artifacts, making it easier to compare experiments and manage the model lifecycle. The main parts we use are tracking the server and model registry.
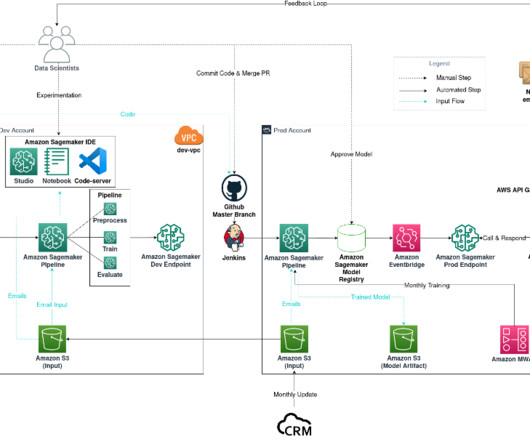
MLOps – Because the SageMaker endpoint is private and can’t be reached by services outside of the VPC, an AWS Lambda function and Amazon API Gateway public endpoint are required to communicate with CRM. The function then relays the classification back to CRM through the API Gateway public endpoint.
Problem definition Traditionally, the recommendation service was mainly provided by identifying the relationship between products and providing products that were highly relevant to the product selected by the customer. Lambda receives the list of recommendations and provides them to the API gateway.
All the training and evaluation metrics were inspected manually from Amazon Simple Storage Service (Amazon S3). For every epoch in our training, we were already sending our training metrics through stdOut in the script. This allows us to compare training metrics like accuracy and precision across multiple runs as shown below.
Additionally, the complexity increases due to the presence of synonyms for columns and internal metrics available. JSONs inherently structured format allows for clear and organized representation of complex data such as table schemas, column definitions, synonyms, and sample queries. I am creating a new metric and need the sales data.
The Cloud-Based Software Behind the Scenes Beyond a simple definition of the term, its impossible to talk about the omnichannel contact center without talking about omnichannel contact center software solutions that make them possible. API and Integrations: WFO solutions arent the only thing your contact center software should connect with.
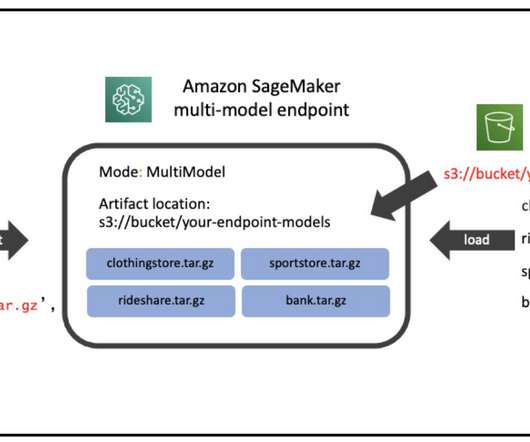
Apart from GPU provisioning, this setup also required data scientists to build a REST API wrapper for each model, which was needed to provide a generic interface for other company services to consume, and to encapsulate preprocessing and postprocessing of model data. Two MMEs were created at Veriff, one for staging and one for production.
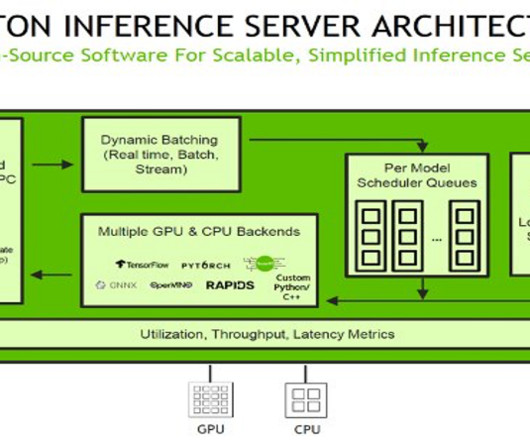
Additionally, NVIDIA Triton Inference Server has been extended to implement MME API contract , to integrate with MME. Get insights into instance and invocation metrics using Amazon CloudWatch. We use the AWS SDK for Python (Boto3) APIs create_model , create_endpoint_config , and create_endpoint to create an MME. Create an MME.
The standard definition of PDD can be defined as: “the time or delay that occurs from the time a number has been dialed, until the caller or called party hears ringing.” To sum it up, the Spearline PDD test is a “call answer time” metric that includes any delay added by intermediary networks.
After you’ve initially configured the bot, you should test it internally and iterate on the bot definition. You can use APIs or AWS CloudFormation (see Creating Amazon Lex V2 resources with AWS CloudFormation ) to manage the bot programmatically. Identify user experience metrics – Defining the conversational experience can be hard.
In addition, they use the developer-provided instruction to create an orchestration plan and then carry out the plan by invoking company APIs and accessing knowledge bases using Retrieval Augmented Generation (RAG) to provide an answer to the user’s request. In Part 1, we focus on creating accurate and reliable agents.
We discuss the important components of fine-tuning, including use case definition, data preparation, model customization, and performance evaluation. We also provide insights on how to achieve optimal results for different dataset sizes and use cases, backed by experimental data and performance metrics.
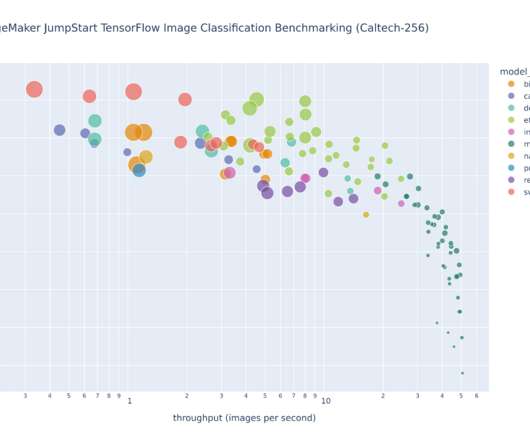
Together with the implementation details in a corresponding example Jupyter notebook , you will have tools available to perform model selection by exploring pareto frontiers, where improving one performance metric, such as accuracy, is not possible without worsening another metric, such as throughput.
This is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API. These metrics will assess how well a machine-generated summary compares to one or more reference summaries.
This module implements an observability solution, including application logs, application performance monitoring (APM), and metrics. Finally, the Logstash service consists of a task definition containing a Logstash container and PII redaction container, ensuring the removal of PII prior to exporting to Elasticsearch.
Triton with PyTorch backend The PyTorch backend is designed to run TorchScript models using the PyTorch C++ API. In the container definition, define the ModelDataUrl to specify the S3 directory that contains all the models that the SageMaker MME will use to load and serve predictions. tar -C triton-serve-pt/ -czf resnet_pt_v0.tar.gz
Their production segment is therefore an integral building block for delivering on their mission—with a clearly stated ambition to become world-leading on metrics such as safety, environmental footprint, quality, and production costs. Yara has built APIs using Amazon API Gateway to expose the sensor data to applications such as ELC.
The definitions of low and high depend on the application, but common practice suggests that scores beyond three standard deviations from the mean score are considered anomalous. JumpStart solutions are not available in SageMaker notebook instances, and you can’t access them through SageMaker APIs or the AWS Command Line Interface (AWS CLI).
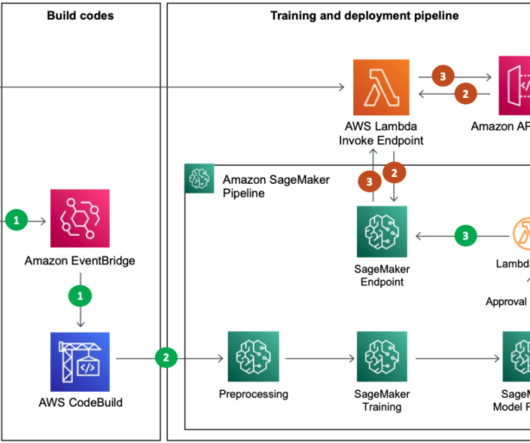
For this we use AWS Step Functions , a serverless workflow service that provides us with API integrations to quickly orchestrate and visualize the steps in our workflow. Create a SageMaker pipeline definition to orchestrate model building. Use the scripts created in step one as part of the processing and training steps.
Theres no one clear definition of CX platform. A customer journey or interaction analytics platform may collect and analyze aspects of customer interactions to offer insights on how to improve key service or sales metrics. Real-Time Dashboards and Reporting: Monitor key metrics and track performance within intuitive dashboards.
This often means the method of using a third-party LLM API won’t do for security, control, and scale reasons. It provides an approachable, robust Python API for the full infrastructure stack of ML/AI, from data and compute to workflows and observability. The following figure illustrates this workflow.
SageMaker hosting services are used to deploy models, while SageMaker Model Monitor and SageMaker Clarify are used to monitor models for drift, bias, custom metric calculators, and explainability. Amazon API Gateway is used to expose the functionality with an API endpoint to be consumed from their web portal. Data service.
In this post, we address these limitations by implementing the access control outside of the MLflow server and offloading authentication and authorization tasks to Amazon API Gateway , where we implement fine-grained access control mechanisms at the resource level using Identity and Access Management (IAM). Adds an IAM authorizer.
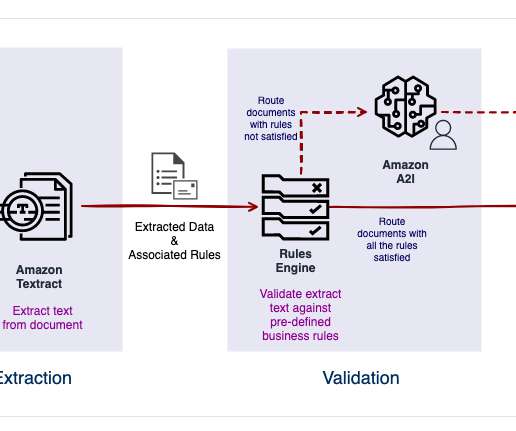
Call the Amazon Textract analyze_document API using the Queries feature to extract text from the page. In the sample solution, we call the Amazon Textract analyze_document API query feature to extract fields by asking specific questions. You can find the detailed JSON structure definition in the GitHub repo.
Amp wanted a scalable data and analytics platform to enable easy access to data and perform machine leaning (ML) experiments for live audio transcription, content moderation, feature engineering, and a personal show recommendation service, and to inspect or measure business KPIs and metrics. This post is the first in a two-part series.
Some people will definitely reply to your texts for more information about your service/offer. Thanks to SMS gateways and APIs, you can schedule and automatically send pre-written messages to thousands of customers today. While there are several metrics to track, the two major ones that you should not be missing are: 1.
In Part 1, we saw how to use Amazon Textract APIs to extract information like forms and tables from documents, and how to analyze invoices and identity documents. It can be difficult to automatically extract information from such types of documents where there is no definite structure. Extraction phase. client('comprehend').
In addition, all SageMaker real-time endpoints benefit from built-in capabilities to manage and monitor models, such as including shadow variants , auto scaling , and native integration with Amazon CloudWatch (for more information, refer to CloudWatch Metrics for Multi-Model Endpoint Deployments ).
Role context – Start each prompt with a clear role definition. This involves benchmarking new models against our current selections across various metrics, running A/B tests, and gradually incorporating high-performing models into our production pipeline. For example, “You are an AWS Account Manager preparing for a customer meeting.”
Throughout this blog post, we will be talking about AutoML to indicate SageMaker Autopilot APIs, as well as Amazon SageMaker Canvas AutoML capabilities. The following diagram depicts the basic AutoMLV2 APIs, all of which are relevant to this post. The diagram shows the workflow for building and deploying models using the AutoMLV2 API.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content