This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon with a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
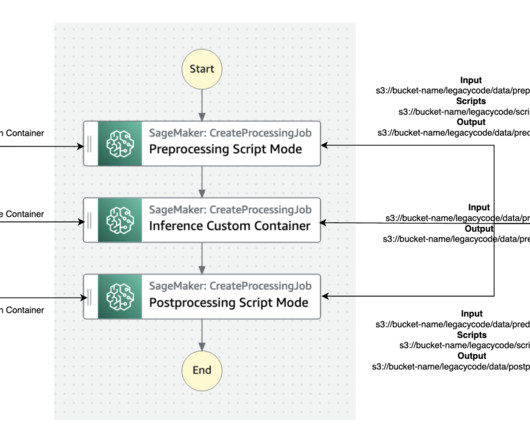
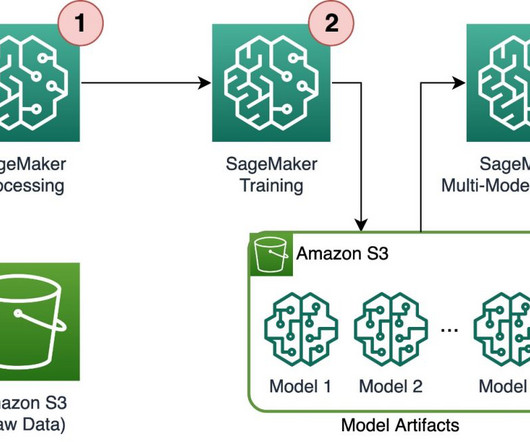
The best practice for migration is to refactor these legacy codes using the Amazon SageMaker API or the SageMaker Python SDK. SageMaker runs the legacy script inside a processing container. Step Functions is a serverless workflow service that can control SageMaker APIs directly through the use of the Amazon States Language.
Amazon Bedrock agents use LLMs to break down tasks, interact dynamically with users, run actions through API calls, and augment knowledge using Amazon Bedrock Knowledge Bases. In this post, we demonstrate how to use Amazon Bedrock Agents with a web search API to integrate dynamic web content in your generative AI application.
Designing the prompt Before starting any scaled use of generative AI, you should have the following in place: A clear definition of the problem you are trying to solve along with the end goal. Refer to Getting started with the API to set up your environment to make Amazon Bedrock requests through the AWS API. client = boto3.client("bedrock-runtime",
Problem definition Traditionally, the recommendation service was mainly provided by identifying the relationship between products and providing products that were highly relevant to the product selected by the customer. Lambda receives the list of recommendations and provides them to the API gateway.
The code to invoke the pipeline script is available in the Studio notebooks, and we can change the hyperparameters and input/output when invoking the pipeline. This is quite different from our earlier method where we had all the parameters hard coded within the scripts and all the processes were inextricably linked. cpu-py39-ubuntu20.04-sagemaker",
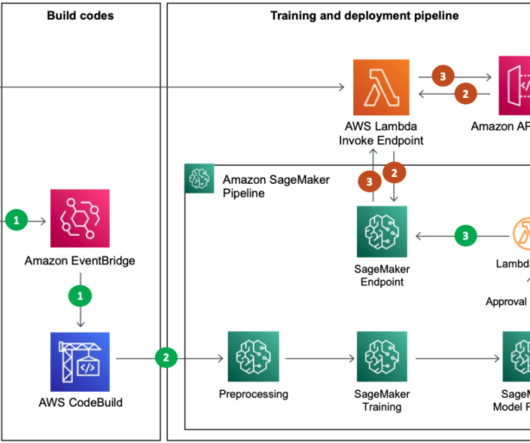
For this we use AWS Step Functions , a serverless workflow service that provides us with API integrations to quickly orchestrate and visualize the steps in our workflow. Create a SageMaker pipeline definition to orchestrate model building. Use the scripts created in step one as part of the processing and training steps.
Amazon Bedrock is a fully managed service that offers an easy-to-use API for accessing foundation models for text, image, and embedding. Amazon Location offers an API for maps, places, and routing with data provided by trusted third parties such as Esri, HERE, Grab, and OpenStreetMap. Point function requires importing shapely library.
If you just want to read about this feature without running it yourself, you can refer to the Python script facet-search-query.py Set up the infrastructure and run the Python script to query the Amazon Kendra index. In the navigation pane, choose Facet definition. For convenience, all the steps are included in one Python script.
Each stage in the ML workflow is broken into discrete steps, with its own script that takes input and output parameters. In the following code, the desired number of actors is passed in as an input argument to the script. Let’s look at sections of the scripts that perform this data preprocessing. get("OfflineStoreConfig").get("S3StorageConfig").get("ResolvedOutputS3Uri")
This often means the method of using a third-party LLM API won’t do for security, control, and scale reasons. It provides an approachable, robust Python API for the full infrastructure stack of ML/AI, from data and compute to workflows and observability. The following figure illustrates this workflow.
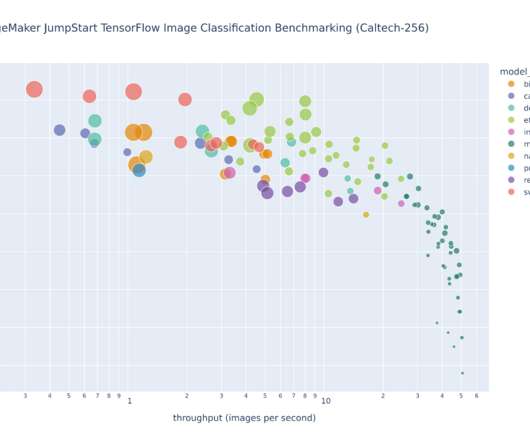
There are many factors you should consider to maximize CPU/GPU utilization when you run your TensorFlow script on SageMaker, such as infrastructure, type of accelerator, distributed training method, data loading method, mixed precision training, and more. SageMaker provisions the infrastructure and runs your script with MPI.
Triton with PyTorch backend The PyTorch backend is designed to run TorchScript models using the PyTorch C++ API. Alternatively, you can use ensemble models or business logic scripting. file in the workspace directory contains scripts to load and save a PyTorch model. client(service_name="sagemaker") runtime_sm_client = boto3.client("sagemaker-runtime")
In this post, we address these limitations by implementing the access control outside of the MLflow server and offloading authentication and authorization tasks to Amazon API Gateway , where we implement fine-grained access control mechanisms at the resource level using Identity and Access Management (IAM). Adds an IAM authorizer.
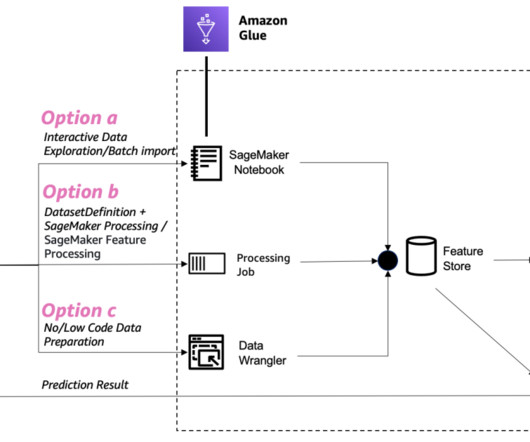
Option B: Use a SageMaker Processing job with Spark In this option, we use a SageMaker Processing job with a Spark script to load the original dataset from Amazon Redshift, perform feature engineering, and ingest the data into SageMaker Feature Store. The environment preparation process may take some time to complete.
The JumpStart APIs allow you to programmatically deploy and fine-tune a vast selection of pre-trained models on your own datasets. These features remove the heavy lifting from each step of the ML process, making it easier to develop high-quality models and reducing time to deployment.
Health – Control health definitions and get more visibility in health reasons to drive the right action. . System Browser Scripts settings – You can now enable/disable session recordings in Global Settings -> General. You can also enable a walkthrough script with a script UR L. .
As we see in the preceding code, ProcessingStep needs to do basically the same preprocessing logic as.run , just without initiating the API call to start the job. For more information on the various SageMaker components that are both standalone Python APIs along with integrated components of Studio, see the SageMaker product page.
Today, we’re excited to announce the new synchronous API for targeted sentiment in Amazon Comprehend, which provides a granular understanding of the sentiments associated with specific entities in input documents. The Targeted Sentiment API provides the sentiment towards each entity.
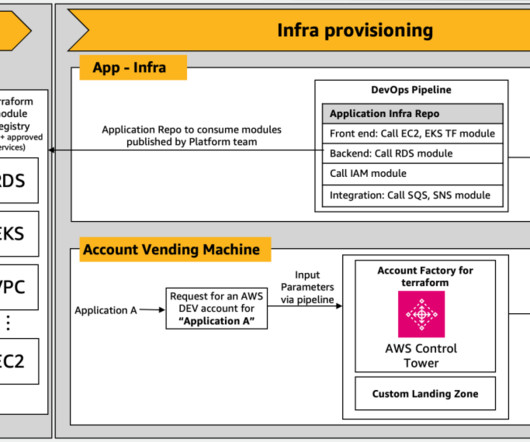
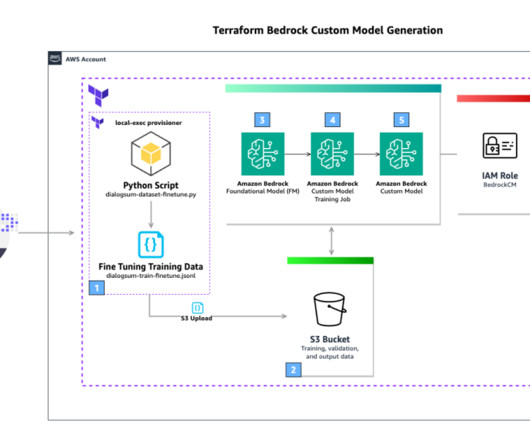
The workflow includes the following steps: The user runs the terraform apply The Terraform local-exec provisioner is used to run a Python script that downloads the public dataset DialogSum from the Hugging Face Hub. file you have been working in and add the terraform_data resource type, uses a local provisioner to invoke your Python script.
In this post, we provide an overview of how to fine-tune the Stable Diffusion model in two ways: programmatically through JumpStart APIs available in the SageMaker Python SDK , and JumpStart’s user interface (UI) in Amazon SageMaker Studio. Fine-tuning large models like Stable Diffusion usually requires you to provide training scripts.
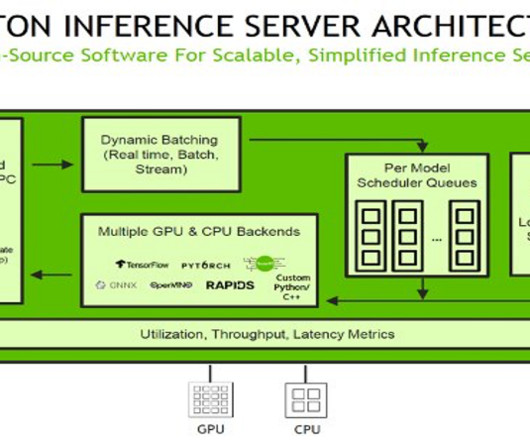
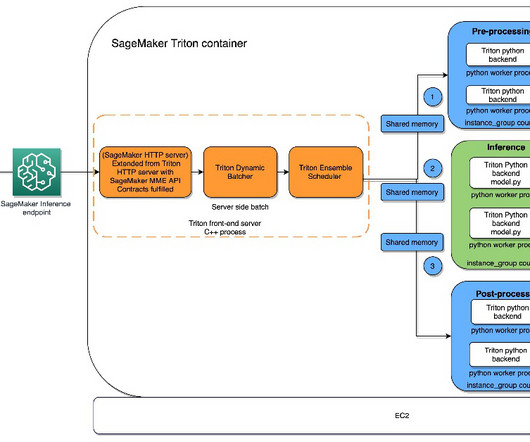
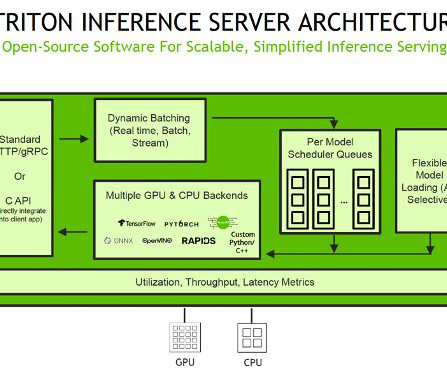
Inference requests arrive at the server via either HTTP/REST or by the C API and are then routed to the appropriate per-model scheduler. SageMaker MMEs offer capabilities for running multiple deep learning or ML models on the GPU at the same time with Triton Inference Server, which has been extended to implement the MME API contract.
To use TensorRT as a backend for Triton Inference Server, you need to create a TensorRT engine from your trained model using the TensorRT API. Inference requests arrive at the server via either HTTP/REST or by the C API , and are then routed to the appropriate per-model scheduler. script from the following cell.
SageMaker MMEs – Multi-model endpoints enable you to host multiple models on a single endpoint, which makes it easy to serve predictions from multiple models using a single API. script containing the training logic: import tarfile import boto3 import os [. script containing the training logic: import tarfile import boto3 import os [.
In addition, they use the developer-provided instruction to create an orchestration plan and then carry out the plan by invoking company APIs and accessing knowledge bases using Retrieval Augmented Generation (RAG) to provide an answer to the user’s request. In Part 1, we focus on creating accurate and reliable agents.
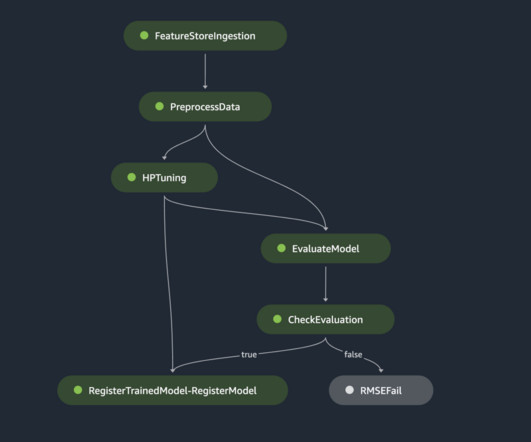
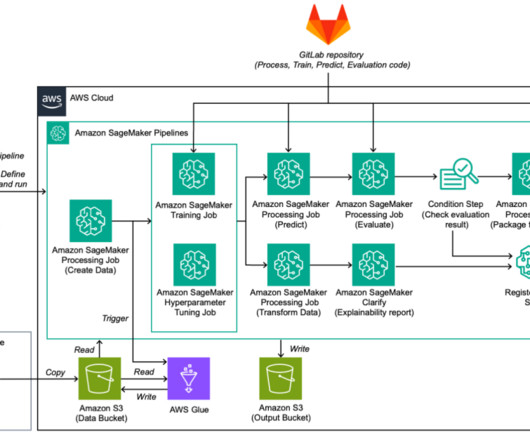
In this example, we use a SageMaker processing job, in which we define an Athena dataset definition. The processing job queries the data via Athena and uses a script to split the data into training, testing, and validation datasets. The following diagram illustrates the data processing procedure.
Developers usually test their processing and training scripts locally, but the pipelines themselves are typically tested in the cloud. Writing the scripts to transform the data is typically an iterative process, where fast feedback loops are important to speed up development. Build your pipeline.
We begin by creating an S3 bucket where we store the script for our AWS Glue streaming job. Run the following command in your terminal to create a new bucket: aws s3api create-bucket --bucket sample-script-bucket-$RANDOM --region us-east-1. s3://sample-script-bucket-30232/glue_streaming/app.py.
For more information, refer to Using the SageMaker Python SDK and Using the Low-Level SageMaker APIs. After you have defined the instance groups, you need to modify your training script to read the SageMaker training environment information that includes heterogeneous cluster configuration. The launcher.py
Download the pipeline definition as a JSON file to your local environment by choosing Export at the bottom of the visual editor. Step #2: Prepare the fine-tuned LLM for deployment Before you deploy the model to an endpoint, you will create the model definition, which includes the model artifacts and Docker container needed to host the model.
Additionally, it’s challenging to construct a streaming data pipeline that can feed incoming events to a GNN real-time serving API. It starts from a RESTful API that queries the graph database in Neptune to extract the subgraph related to an incoming transaction. The code used in this solution is available in src/scripts/glue-etl.py.
Furthermore, proprietary models typically come with user-friendly APIs and SDKs, streamlining the integration process with your existing systems and applications. It offers an easy-to-use API and Python SDK, balancing quality and affordability. Popular uses include generating marketing copy, powering chatbots, and text summarization.
When the message is received by the SQS queue, it triggers the AWS Lambda function to make an API call to the Amp catalog service. Lambda enabled the team to create lightweight functions to run API calls and perform data transformations.
The definitions of low and high depend on the application, but common practice suggests that scores beyond three standard deviations from the mean score are considered anomalous. JumpStart solutions are not available in SageMaker notebook instances, and you can’t access them through SageMaker APIs or the AWS Command Line Interface (AWS CLI).
Copy these values to.env as follows: NEXMO_API_KEY="YOUR API KEY HERE" NEXMO_API_SECRET="YOUR API SECRET HERE". We must create an application that uses the Voice API and Messages API. To send messages using the Messages API, we need our API Key and API Secret. format(username,api_url) } } } ).json()
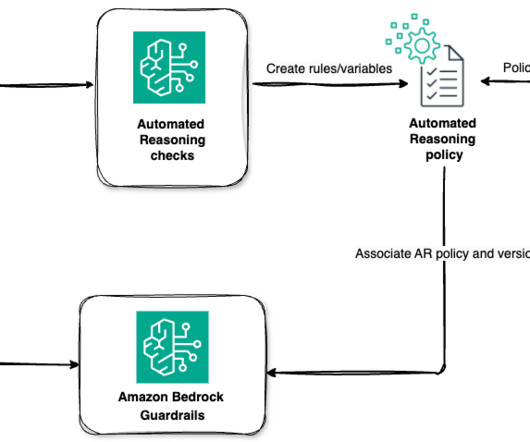
Unlike probabilistic approaches prevalent in machine learning, Automated Reasoning relies on formal mathematical logic to provide definitive guarantees about what can and cant be proven. Unlike probabilistic methods, it uses sound mathematical approaches to provide definitive guarantees about system behaviors within defined parameters.
Throughout this blog post, we will be talking about AutoML to indicate SageMaker Autopilot APIs, as well as Amazon SageMaker Canvas AutoML capabilities. The following diagram depicts the basic AutoMLV2 APIs, all of which are relevant to this post. The diagram shows the workflow for building and deploying models using the AutoMLV2 API.
Add the following inline policies (available in the notebooks/iam-roles folder in the GitHub repository): bedrock-agents-retrieve.json bedrock-invoke-model-all.json lex-invoke-bot.json opensearch-serverless-api-access.json You can revise these roles to limit resource access as needed. run_tests.ipynb – This notebook runs a set of test cases.
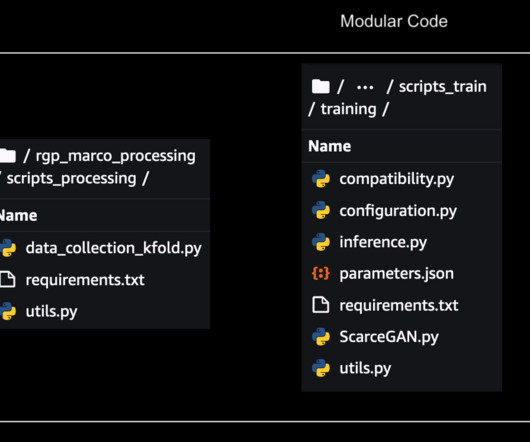
Client package development – A client package was developed that acts as a wrapper around SageMaker APIs and the previously existing code. Evaluate – A PySpark processing job evaluates the model using a custom Spark script. This was crucial in ensuring a smooth transition from on-premises to cloud-based processing.
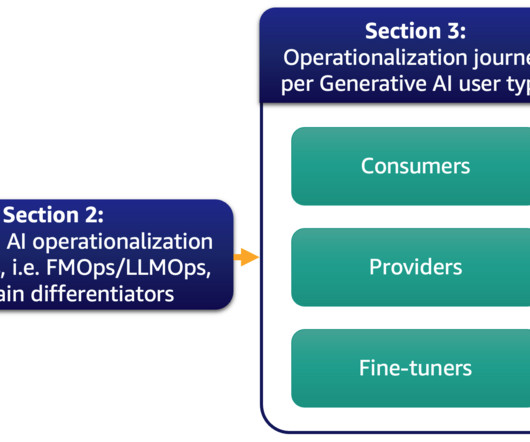
Generative AI definitions and differences to MLOps In classic ML, the preceding combination of people, processes, and technology can help you productize your ML use cases. Some models may be trained on diverse text datasets like internet data, coding scripts, instructions, or human feedback. 15K available FM reference Step 1.
Many data scientists prefer to use this web-based IDE for developing the ML code, quickly debugging the library API, and getting things running with a small sample of data to validate the training script. The Dockerfile used for the Docker build, which contains all dependencies and the training code. The dependencies.
A complete API call from the client is as follows: The client assembles the request and initiates the request to a SageMaker endpoint. The Python script starts the NGINX, Flask, and Triton server. base.py – The abstract method definition that each client requires to implement their inference method.
Let’s dive in and learn why JustCall is probably (definitely) the better option for you. JustCall is easier to integrate: JustCall boasts 100+ integrations for CRMs , webhooks, or APIs, offering seamless compatibility with various business tools. There are also many other important differences between the two (i.e.,
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content