This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
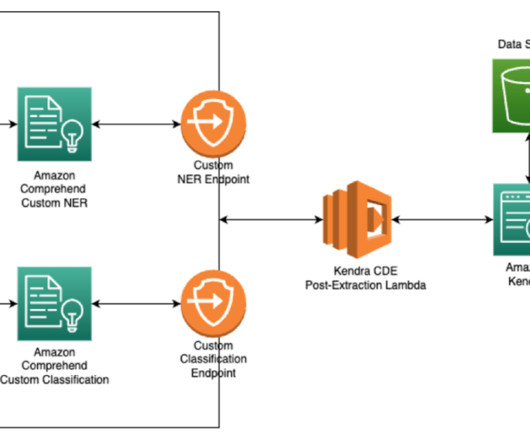
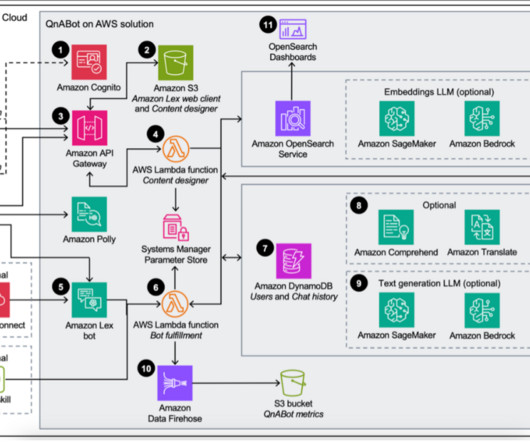
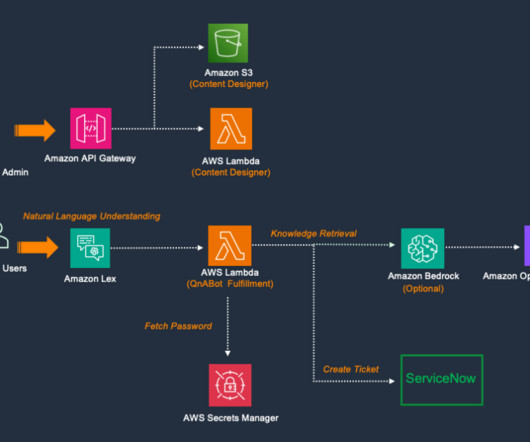
Principal wanted to use existing internal FAQs, documentation, and unstructured data and build an intelligent chatbot that could provide quick access to the right information for different roles. QnABot is a multilanguage, multichannel conversational interface (chatbot) that responds to customers’ questions, answers, and feedback.
Observability empowers you to proactively monitor and analyze your generative AI applications, and evaluation helps you collect feedback, refine models, and enhance output quality. In the context of Amazon Bedrock , observability and evaluation become even more crucial.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. API Gateway is serverless and hence automatically scales with traffic. API Gateway also provides a WebSocket API. Incoming requests to the gateway go through this point.
Lets say the task at hand is to predict the root cause categories (Customer Education, Feature Request, Software Defect, Documentation Improvement, Security Awareness, and Billing Inquiry) for customer support cases. We suggest consulting LLM prompt engineering documentation such as Anthropic prompt engineering for experiments.
Today, we’re introducing the new capability to chat with your document with zero setup in Knowledge Bases for Amazon Bedrock. With this new capability, you can securely ask questions on single documents, without the overhead of setting up a vector database or ingesting data, making it effortless for businesses to use their enterprise data.
Amazon Bedrock is a fully managed service that offers a choice of high-performing Foundation Models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon via a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
Rigorous testing allows us to understand an LLMs capabilities, limitations, and potential biases, and provide actionable feedback to identify and mitigate risk. It functions as a standalone HTTP server that provides various REST API endpoints for monitoring, recording, and visualizing experiment runs.
adds new APIs to customize GraphStorm pipelines: you now only need 12 lines of code to implement a custom node classification training loop. For more details about how to run graph multi-task learning with GraphStorm, refer to Multi-task Learning in GraphStorm in our documentation. introduces refactored graph ML pipeline APIs.
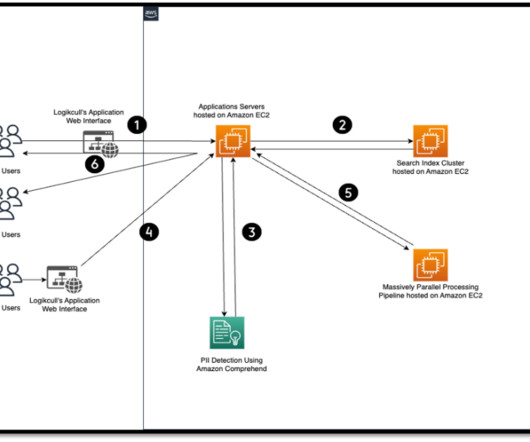
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machine learning (ML), metadata analysis, data classification software, optical character recognition (OCR), document fingerprinting, and encryption.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Conversational AI has come a long way in recent years thanks to the rapid developments in generative AI, especially the performance improvements of large language models (LLMs) introduced by training techniques such as instruction fine-tuning and reinforcement learning from human feedback.
Designed for both image and document comprehension, Pixtral demonstrates advanced capabilities in vision-related tasks, including chart and figure interpretation, document question answering, multimodal reasoning, and instruction followingseveral of which are illustrated with examples later in this post.
As generative AI models advance in creating multimedia content, the difference between good and great output often lies in the details that only human feedback can capture. Amazon SageMaker Ground Truth enables RLHF by allowing teams to integrate detailed human feedback directly into model training.
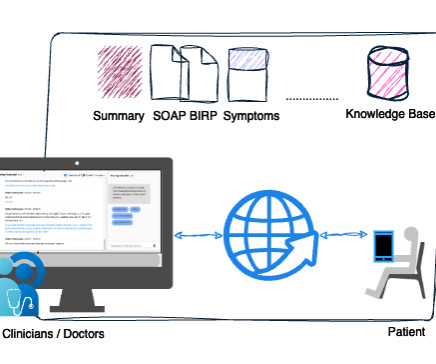
Today, physicians spend about 49% of their workday documenting clinical visits, which impacts physician productivity and patient care. By using the solution, clinicians don’t need to spend additional hours documenting patient encounters. What are the differences between AWS HealthScribe and the LMA for healthcare?
For more information about the SageMaker AI API, refer to the SageMaker AI API Reference. 8B-Instruct to DeepSeek-R1-Distill-Llama-8B, but the new model version has different API expectations. In this use case, you have configured a CloudWatch alarm to monitor for 4xx errors, which would indicate API compatibility issues.
Solution overview Our solution implements a verified semantic cache using the Amazon Bedrock Knowledge Bases Retrieve API to reduce hallucinations in LLM responses while simultaneously improving latency and reducing costs. The function checks the semantic cache (Amazon Bedrock Knowledge Bases) using the Retrieve API.
Customers can use the SageMaker Studio UI or APIs to specify the SageMaker Model Registry model to be shared and grant access to specific AWS accounts or to everyone in the organization. We will start by using the SageMaker Studio UI and then by using APIs. These stages are applicable to both use case and model stages.
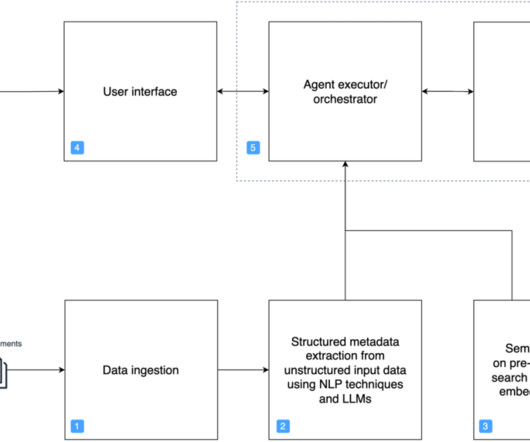
Current challenges faced by enterprises Modern enterprises face numerous challenges, including: Managing vast amounts of unstructured data: Enterprises deal with immense volumes of data generated from various sources such as emails, documents, and customer interactions.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API. This is one of the documents that a customer seeking a loan has uploaded. model on Amazon Bedrock.
Amazon Bedrock , a fully managed service offering high-performing foundation models from leading AI companies through a single API, has recently introduced two significant evaluation capabilities: LLM-as-a-judge under Amazon Bedrock Model Evaluation and RAG evaluation for Amazon Bedrock Knowledge Bases.
To use Automated Reasoning checks, you first create an Automated Reasoning policy by encoding a set of logical rules and variables from available source documentation. Automated Reasoning checks deliver deterministic verification of model outputs against documented rules, complete with audit trails and mathematical proof of policy adherence.
To find an answer, RAG takes an approach that uses vector search across the documents. Rather than scanning every single document to find the answer, with the RAG approach, you turn the texts (knowledge base) into embeddings and store these embeddings in the database. Generate questions from the document using an Amazon Bedrock LLM.
Documents are a primary tool for record keeping, communication, collaboration, and transactions across many industries, including financial, medical, legal, and real estate. The millions of mortgage applications and hundreds of millions of W2 tax forms processed each year are just a few examples of such documents.
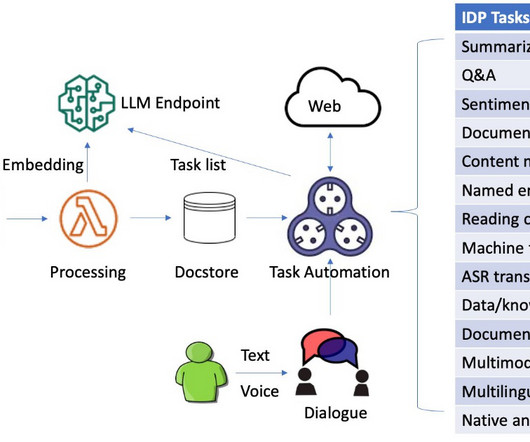
Intelligent document processing (IDP) is a technology that automates the processing of high volumes of unstructured data, including text, images, and videos. The system is capable of processing images, large PDF, and documents in other format and answering questions derived from the content via interactive text or voice inputs.
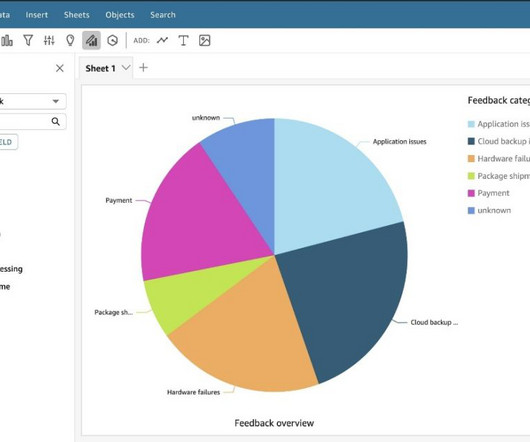
Extracting valuable insights from customer feedback presents several significant challenges. Scalability becomes an issue as the amount of feedback grows, hindering the ability to respond promptly and address customer concerns. Large language models (LLMs) have transformed the way we engage with and process natural language.
Students can take personalized quizzes and get immediate feedback on their performance. It is typically helpful when working with lengthy documents such as entire books. on Amazon Bedrock would be equivalent to roughly 150,000 words or over 500 pages of documents. The JSON file is returned to API Gateway.
With this launch, you can programmatically run notebooks as jobs using APIs provided by Amazon SageMaker Pipelines , the ML workflow orchestration feature of Amazon SageMaker. Furthermore, you can create a multi-step ML workflow with multiple dependent notebooks using these APIs.
Investing in a tool for collecting customer feedback can help you to better understand what customers are asking for. Do we need documentation tools? Ultimately, determining whether to build or buy a customer feedback tool comes down to balancing the cost with the benefits of customization. Troubleshooting tools? Click To Tweet.
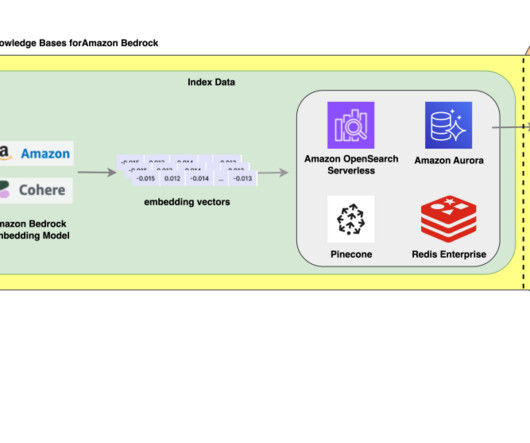
Knowledge Bases for Amazon Bedrock automates synchronization of your data with your vector store, including diffing the data when it’s updated, document loading, and chunking, as well as semantic embedding. It then employs a language model to generate a response by considering both the retrieved documents and the original query.
Solution overview Responses are personalized by Amazon Q Business by determining if the user’s query could be enhanced by augmenting the query with known attributes of the user and transparently using the personalized query to retrieve documents from its search index. or OIDC is used for the provider.
Cloud providers have recognized the need to offer model inference through an API call, significantly streamlining the implementation of AI within applications. Although a single API call can address simple use cases, more complex ones may necessitate the use of multiple calls and integrations with other services.
This short timeframe is made possible by: An API with a multitude of proven functionalities; A proprietary and patented NLP technology developed and perfected over the course of 15 years by our in-house Engineers and Linguists; A well-established development process. Poor technical documentation.
This is because trades involve different counterparties and there is a high degree of variation among documents containing commercial terms (such as trade date, value date, and counterparties). Intelligent document processing (IDP) applies AI/ML techniques to automate data extraction from documents.
Intelligent document processing , translation and summarization, flexible and insightful responses for customer support agents, personalized marketing content, and image and code generation are a few use cases using generative AI that organizations are rolling out in production.
Challenge 2: Integration with Wearables and Third-Party APIs Many people use smartwatches and heart rate monitors to measure sleep, stress, and physical activity, which may affect mental health. Third-party APIs may link apps to healthcare and meditation services. However, integrating these diverse sources is not straightforward.
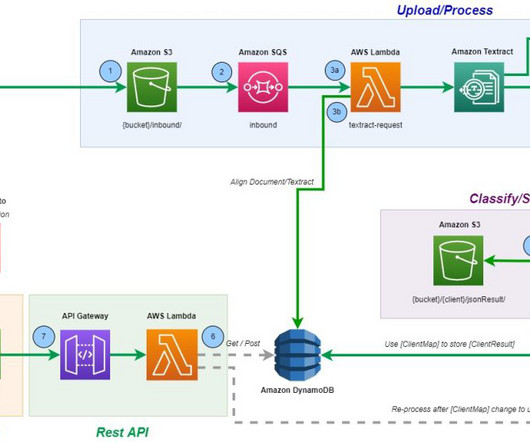
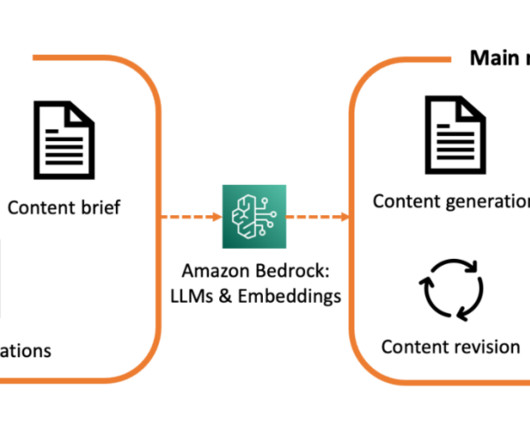
This is accomplished through an automated revision functionality, which allows the user to interact and send instructions and comments directly to the LLM via an interactive feedback loop. Amazon Textract : for documents parsing, text, and layout extraction. Amazon Simple Storage Service (S3) : for documents and processed data caching.
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
Great examples of automated distribution include survey integrations and Application Programming Interface (API) connections. And, setting up APIs can link two applications to one another for data sharing/interacting purposes, making manual uploads a thing of the past. Create custom APIs for more complex use cases. Not to worry!
Document categorization or classification has significant benefits across business domains – Improved search and retrieval – By categorizing documents into relevant topics or categories, it makes it much easier for users to search and retrieve the documents they need. politics, sports) that a document belongs to.
Lastly, if you don’t want to set up custom integrations with large data sources, you can simply upload your documents and support multi-turn conversations. After authentication, Amazon API Gateway and Amazon S3 deliver the contents of the Content Designer UI. input – A placeholder for the current user utterance or question.
In addition, to enable safeguarding applications using different FMs, Amazon Bedrock Guardrails now supports the ApplyGuardrail API to evaluate user inputs and model responses for custom and third-party FMs available outside of Amazon Bedrock. The response of the API provides the following details: If the guardrail intervened.
A number of techniques are typically used to improve the accuracy and performance of an LLM’s output, such as fine-tuning with parameter efficient fine-tuning (PEFT) , reinforcement learning from human feedback (RLHF) , and performing knowledge distillation. This is a challenge you are often faced with when working with larger documents.
The customized UI allows you to implement special features like handling feedback, using company brand colors and templates, and using a custom login. Amazon Q uses the chat_sync API to carry out the conversation. Amazon Q returns the response as a JSON object (detailed in the Amazon Q documentation ).
Solution overview QnABot on AWS is a multi-channel, multi-language chatbot that responds to your customer’s questions, answers, and feedback. The workflow includes the following steps: A QnABot administrator can configure the questions using the Content Designer UI delivered by Amazon API Gateway and Amazon Simple Storage Service (Amazon S3).
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content