This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Generative AI has transformed customer support, offering businesses the ability to respond faster, more accurately, and with greater personalization. In this post, we guide you through integrating Amazon Bedrock Agents with enterprise data APIs to create more personalized and effective customer support experiences.
In this post, we focus on one such complex workflow: document processing. Rule-based systems or specialized machine learning (ML) models often struggle with the variability of real-world documents, especially when dealing with semi-structured and unstructured data.
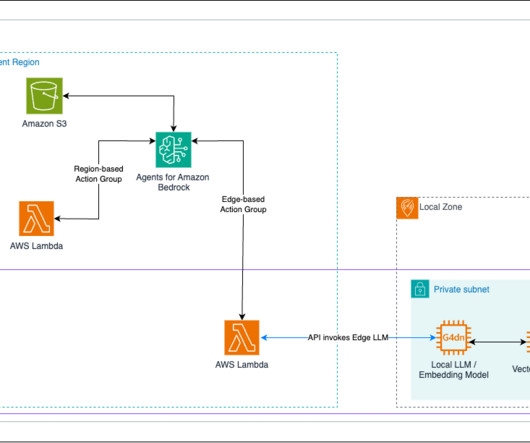
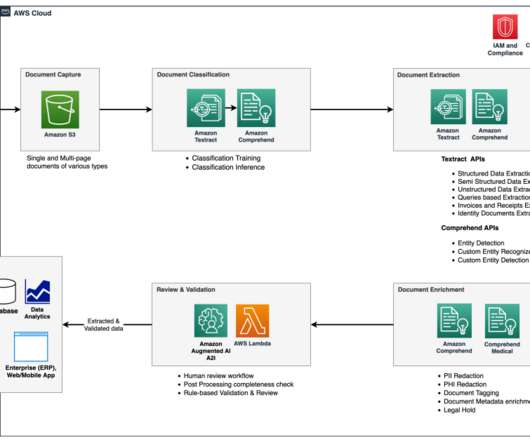
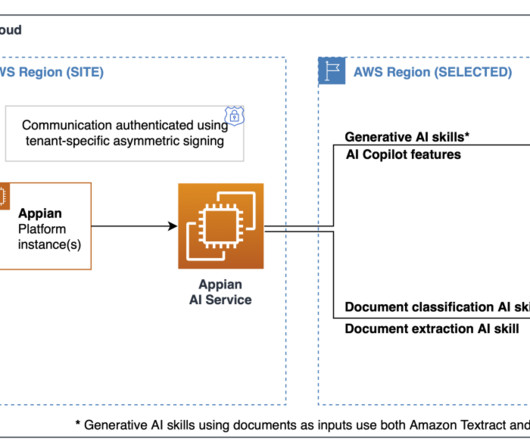
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. The following figure illustrates the high-level design of the solution.
Google Drive supports storing documents such as Emails contain a wealth of information found in different places, such as within the subject of an email, the message content, or even attachments. Types of documents Gmail messages can be sorted and stored inside your email inbox using folders and labels.
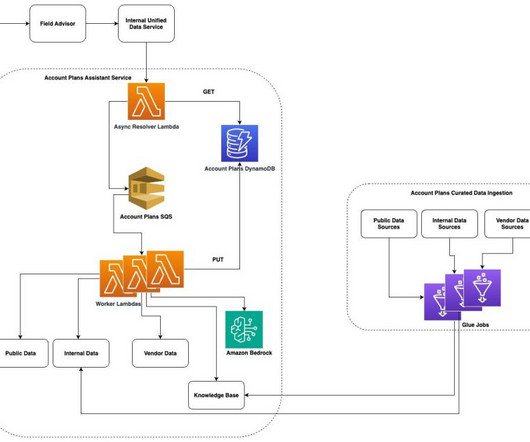
Every year, AWS Sales personnel draft in-depth, forward looking strategy documents for established AWS customers. These documents help the AWS Sales team to align with our customer growth strategy and to collaborate with the entire sales team on long-term growth ideas for AWS customers.
Additionally, TDD facilitates collaboration and knowledge sharing among teams, because tests serve as living documentation and a shared understanding of the expected behavior and constraints. In this post, we present a solution that takes a TDD approach to guardrail development, allowing you to improve your guardrails over time.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. API Gateway is serverless and hence automatically scales with traffic. API Gateway also provides a WebSocket API. Incoming requests to the gateway go through this point.
Amazon Bedrock Knowledge Bases has a metadata filtering capability that allows you to refine search results based on specific attributes of the documents, improving retrieval accuracy and the relevance of responses. Improving document retrieval results helps personalize the responses generated for each user.
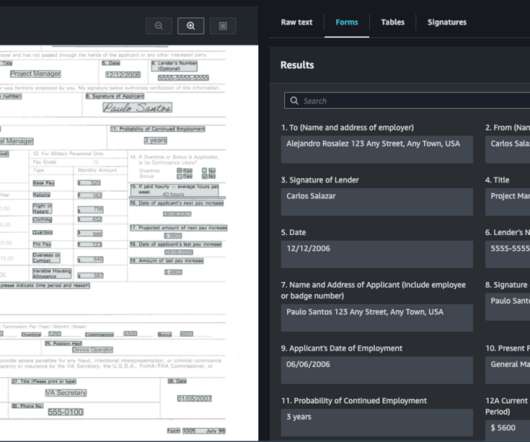
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from scanned documents. Queries is a feature that enables you to extract specific pieces of information from varying, complex documents using natural language. personal or cashier’s checks), financial institution and country (e.g.,
In today’s data-driven business landscape, the ability to efficiently extract and process information from a wide range of documents is crucial for informed decision-making and maintaining a competitive edge. The Anthropic Claude 3 Haiku model then processes the documents and returns the desired information, streamlining the entire workflow.
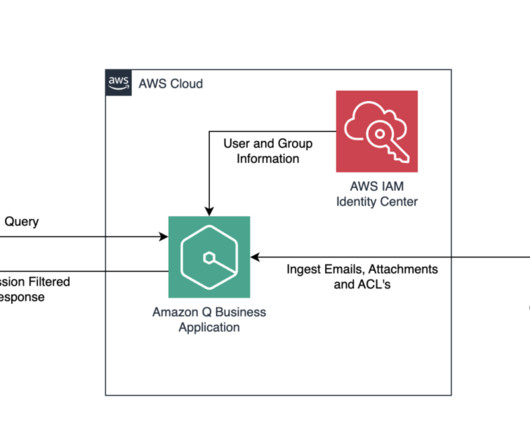
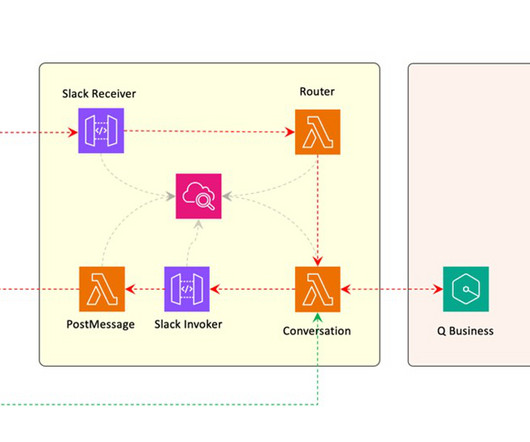
This enables sales teams to interact with our internal sales enablement collateral, including sales plays and first-call decks, as well as customer references, customer- and field-facing incentive programs, and content on the AWS website, including blog posts and service documentation.
Personalization can improve the user experience of shopping, entertainment, and news sites by using our past behavior to recommend the products and content that best match our interests. You can also apply personalization to conversational interactions with an AI-powered assistant.
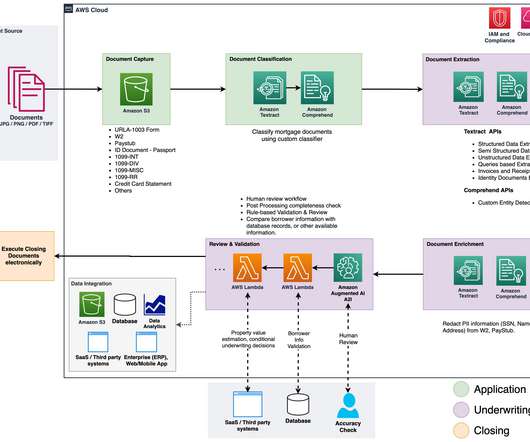
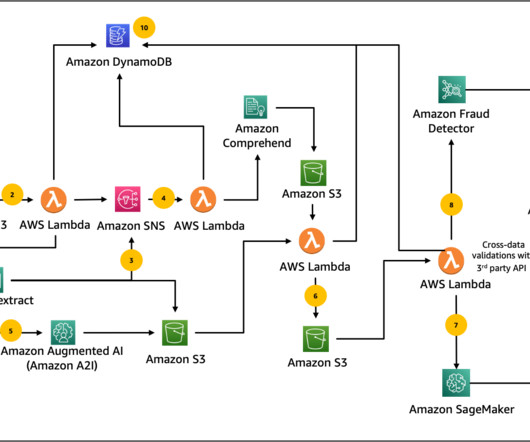
Organizations in the lending and mortgage industry process thousands of documents on a daily basis. From a new mortgage application to mortgage refinance, these business processes involve hundreds of documents per application. At the start of the process, documents are uploaded to an Amazon Simple Storage Service (Amazon S3) bucket.
Additionally, Cropwise AI enables personalized recommendations at scale, tailoring seed choices to align with local conditions and specific farm needs, creating a more precise and accessible selection process. It facilitates real-time data synchronization and updates by using GraphQL APIs, providing seamless and responsive user experiences.
Furthermore, these notes are usually personal and not stored in a central location, which is a lost opportunity for businesses to learn what does and doesn’t work, as well as how to improve their sales, purchasing, and communication processes. With Lambda integration, we can create a web API with an endpoint to the Lambda function.
We developed the Document Translation app, which uses Amazon Translate , to address these issues. The Document Translation app uses Amazon Translate for performing translations. Amazon Translate provides high-quality document translations for contextual, accurate, and fluent translations. 1 – Translating a document.
This includes setting up Amazon API Gateway , AWS Lambda functions, and Amazon Athena to enable querying the structured sales data. Navigate to the AWS Secrets Manager console and find the secret -api-keys. Import the API schema from the openapi_schema.json file that you downloaded earlier. Download all three sample data files.
For information on what is included in the tiers of user subscriptions, see Amazon Q Business pricing document. ServiceNow Obtain a ServiceNow Personal Developer Instance or use a clean ServiceNow developer environment. Each unit is 20,000 documents. See Index types for more information. Number of units : Enter 1. Choose Next.
Today, we are excited to announce three launches that will help you enhance personalized customer experiences using Amazon Personalize and generative AI. Amazon Personalize is a fully managed machine learning (ML) service that makes it easy for developers to deliver personalized experiences to their users.
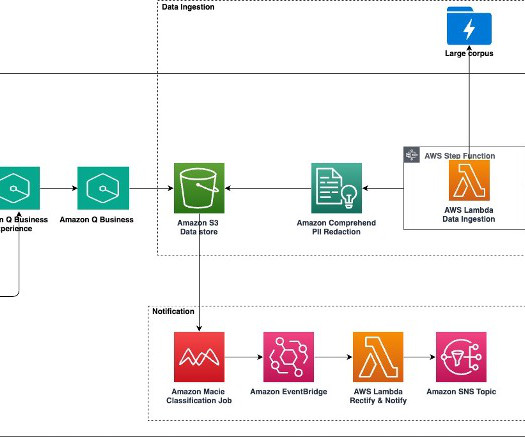
Today, personally identifiable information (PII) is everywhere. PII is sensitive in nature and includes various types of personal data, such as name, contact information, identification numbers, financial information, medical information, biometric data, date of birth, and so on.
Large-scale data ingestion is crucial for applications such as document analysis, summarization, research, and knowledge management. These tasks often involve processing vast amounts of documents, which can be time-consuming and labor-intensive. For example, the Datastore API might require certain input like date periods to query data.
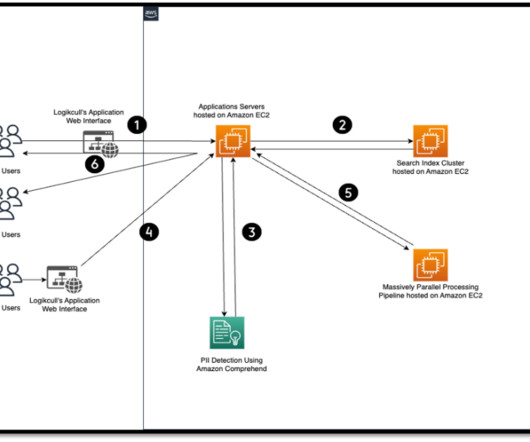
Solution overview For organizations processing or storing sensitive information such as personally identifiable information (PII), customers have asked for AWS Global Infrastructure to address these specific localities, including mechanisms to make sure that data is being stored and processed in compliance with local laws and regulations.
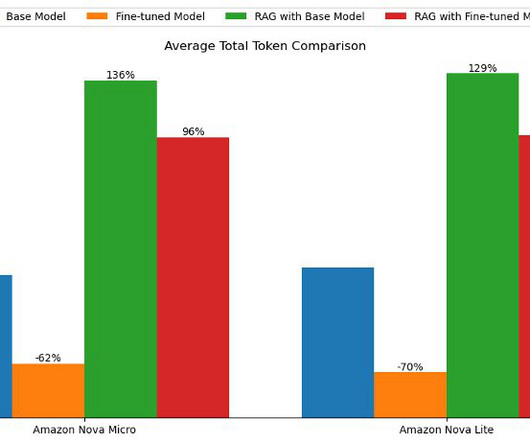
Although RAG excels at real-time grounding in external data and fine-tuning specializes in static, structured, and personalized workflows, choosing between them often depends on nuanced factors. On the Configure data source page, provide the following information: Specify the Amazon S3 location of the documents. Choose Next.
This is the scenario for companies that rely on manual processes for document generationcaught in a cycle of repetitive data entry, missing critical details, non-compliance, and whatnot. Every document you produce is an opportunity to reinforce your brands identity, tone, and professionalism. What is Document Generation Software?
Amazon Textract is a machine learning (ML) service that automatically extracts text, handwriting, and data from any document or image. AnalyzeDocument Signatures is a feature within Amazon Textract that offers the ability to automatically detect signatures on any document. Lastly, we share some best practices for using this feature.
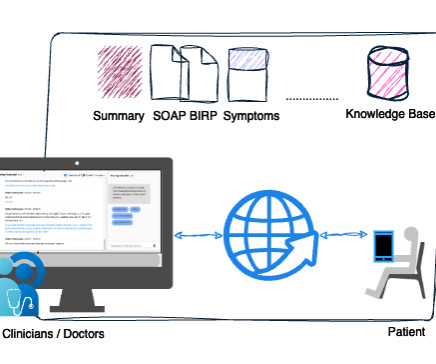
Today, physicians spend about 49% of their workday documenting clinical visits, which impacts physician productivity and patient care. The LMA for healthcare helps healthcare professionals to provide personalized recommendations, enhancing the quality of care.
As attendees circulate through the GAIZ, subject matter experts and Generative AI Innovation Center strategists will be on-hand to share insights, answer questions, present customer stories from an extensive catalog of reference demos, and provide personalized guidance for moving generative AI applications into production.
Reduced time and effort in testing and deploying AI workflows with SDK APIs and serverless infrastructure. We can also quickly integrate flows with our applications using the SDK APIs for serverless flow execution — without wasting time in deployment and infrastructure management.
The goal of intelligent document processing (IDP) is to help your organization make faster and more accurate decisions by applying AI to process your paperwork. Insurance customers can automate this process using AWS AI services to automate the document processing pipeline for claims processing. Part 2: Data enrichment and insights.
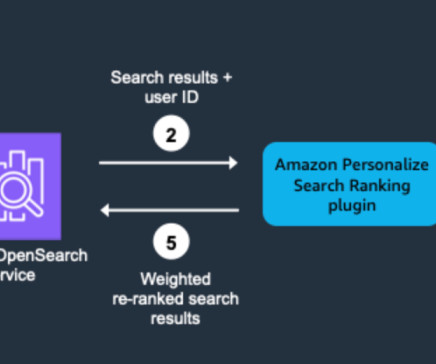
If a distinctive keyword appears more frequently in a document, BM-25 assigns a higher relevance score to that document. Amazon Personalize allows you to add sophisticated personalization capabilities to your applications by using the same machine learning (ML) technology used on Amazon.com for over 20 years.
Organizations across industries such as healthcare, finance and lending, legal, retail, and manufacturing often have to deal with a lot of documents in their day-to-day business processes. There is limited automation available today to process and extract information from these documents.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Customers can use the SageMaker Studio UI or APIs to specify the SageMaker Model Registry model to be shared and grant access to specific AWS accounts or to everyone in the organization. We will start by using the SageMaker Studio UI and then by using APIs. These stages are applicable to both use case and model stages.
In Part 1 of this series, we discussed intelligent document processing (IDP), and how IDP can accelerate claims processing use cases in the insurance industry. We discussed how we can use AWS AI services to accurately categorize claims documents along with supporting documents. Part 1: Classification and extraction of documents.
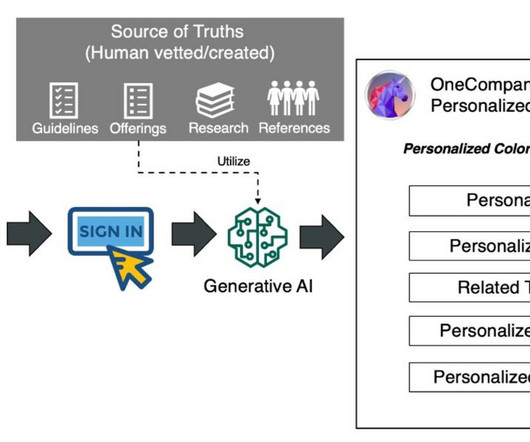
Personalization has become a cornerstone of delivering tangible benefits to businesses and their customers. We present our solution through a fictional consulting company, OneCompany Consulting, using automatically generated personalized website content for accelerating business client onboarding for their consultancy service.
Many CX, marketing and operations leaders are asking how they can use customer journey orchestration to deliver better, more personalized experiences that will improve CX and business outcomes, like retention, customer lifetime value and revenue. Journey orchestration goes beyond traditional personalization techniques.
Current challenges faced by enterprises Modern enterprises face numerous challenges, including: Managing vast amounts of unstructured data: Enterprises deal with immense volumes of data generated from various sources such as emails, documents, and customer interactions.
Beyond Amazon Bedrock models, the service offers the flexible ApplyGuardrails API that enables you to assess text using your pre-configured guardrails without invoking FMs, allowing you to implement safety controls across generative AI applicationswhether running on Amazon Bedrock or on other systemsat both input and output levels.
In this three-part series, we present a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machine learning (ML) services for a mortgage underwriting use case. Fraudsters range from blundering novices to near-perfect masters when creating fraudulent loan application documents.
The Amazon Bedrock single API access, regardless of the models you choose, gives you the flexibility to use different FMs and upgrade to the latest model versions with minimal code changes. Amazon Titan FMs provide customers with a breadth of high-performing image, multimodal, and text model choices, through a fully managed API.
Documentation is frequently the first interaction that a customer has with your product and brand. When someone is having trouble, 91% of them prefer to read documentation rather than ask someone for an answer. Many users prefer documentation because it helps them solve the issue on their own quickly. Create an owner.
With this launch, you can programmatically run notebooks as jobs using APIs provided by Amazon SageMaker Pipelines , the ML workflow orchestration feature of Amazon SageMaker. Furthermore, you can create a multi-step ML workflow with multiple dependent notebooks using these APIs.
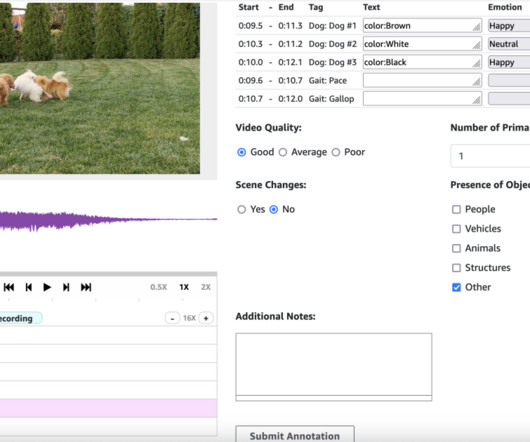
When creating a scene of a person performing a sequence of actions, factors like the timing of movements, visual consistency, and smoothness of transitions contribute to the quality. Programmatic setup Alternatively, you can create your labeling job programmatically using the CreateLabelingJob API. documentation. The Wavesurfer.js
Students can take personalized quizzes and get immediate feedback on their performance. It is typically helpful when working with lengthy documents such as entire books. on Amazon Bedrock would be equivalent to roughly 150,000 words or over 500 pages of documents. The JSON file is returned to API Gateway.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content