This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
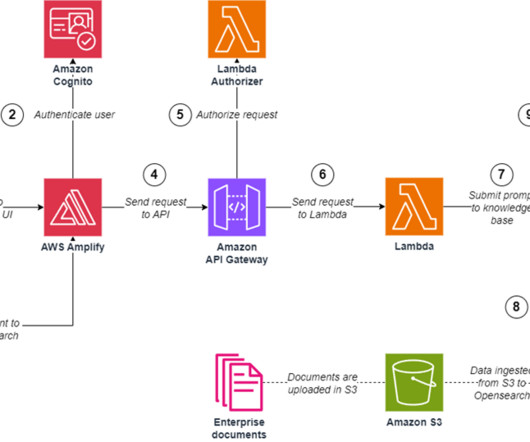
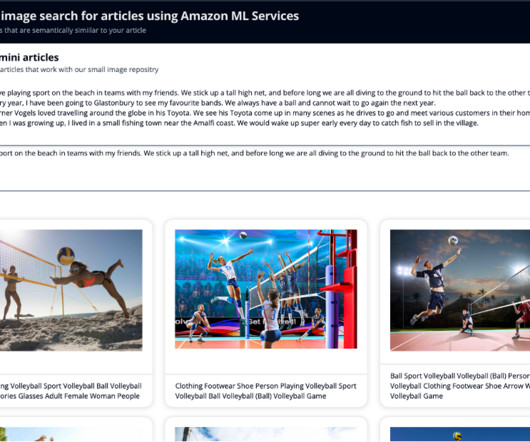
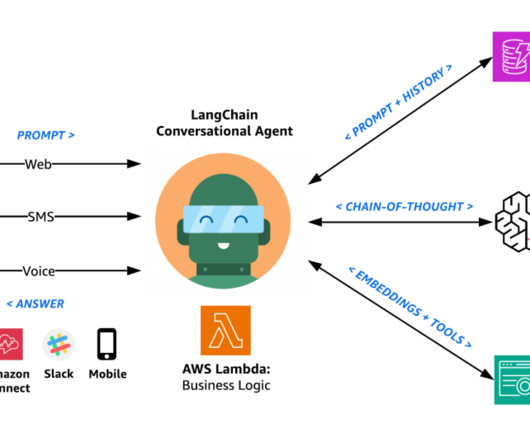
AWS offers powerful generative AI services , including Amazon Bedrock , which allows organizations to create tailored use cases such as AI chat-based assistants that give answers based on knowledge contained in the customers’ documents, and much more. The following figure illustrates the high-level design of the solution.
AWS customers in healthcare, financial services, the public sector, and other industries store billions of documents as images or PDFs in Amazon Simple Storage Service (Amazon S3). In this post, we focus on processing a large collection of documents into raw text files and storing them in Amazon S3.
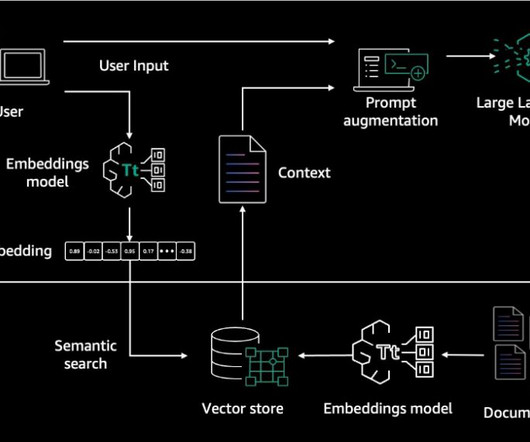
One of the most critical applications for LLMs today is Retrieval Augmented Generation (RAG), which enables AI models to ground responses in enterprise knowledge bases such as PDFs, internal documents, and structured data. Amazon Bedrock APIs make it straightforward to use Amazon Titan Text Embeddings V2 for embedding data.
Lets say the task at hand is to predict the root cause categories (Customer Education, Feature Request, Software Defect, Documentation Improvement, Security Awareness, and Billing Inquiry) for customer support cases. We suggest consulting LLM prompt engineering documentation such as Anthropic prompt engineering for experiments.
Customers can use the SageMaker Studio UI or APIs to specify the SageMaker Model Registry model to be shared and grant access to specific AWS accounts or to everyone in the organization. We will start by using the SageMaker Studio UI and then by using APIs. These stages are applicable to both use case and model stages.
Amazon Bedrock is a fully managed service that makes a wide range of foundation models (FMs) available though an API without having to manage any infrastructure. Amazon API Gateway and AWS Lambda to create an API with an authentication layer and integrate with Amazon Bedrock. The AWS Well-Architected Framework documentation.
Question and answering (Q&A) using documents is a commonly used application in various use cases like customer support chatbots, legal research assistants, and healthcare advisors. In this collaboration, the AWS GenAIIC team created a RAG-based solution for Deltek to enable Q&A on single and multiple government solicitation documents.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Amazon Bedrock is a fully managed service that makes FMs from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. Solution overview The solution comprises two main steps: Generate synthetic data using the Amazon Bedrock InvokeModel API.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon with a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Such data often lacks the specialized knowledge contained in internal documents available in modern businesses, which is typically needed to get accurate answers in domains such as pharmaceutical research, financial investigation, and customer support. For example, imagine that you are planning next year’s strategy of an investment company.
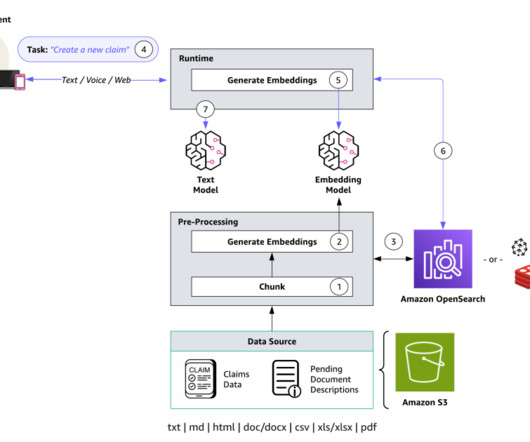
Broadly speaking, a retriever is a module that takes a query as input and outputs relevant documents from one or more knowledge sources relevant to that query. Document ingestion In a RAG architecture, documents are often stored in a vector store. You must use the same embedding model at ingestion time and at search time.
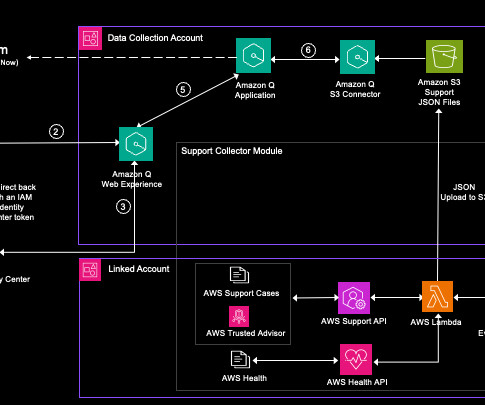
This post shows how to configure an Amazon Q Business custom connector and derive insights by creating a generative AI-powered conversation experience on AWS using Amazon Q Business while using access control lists (ACLs) to restrict access to documents based on user permissions. Who are the data stewards for my proprietary database sources?
At the forefront of this evolution sits Amazon Bedrock , a fully managed service that makes high-performing foundation models (FMs) from Amazon and other leading AI companies available through an API. System integration – Agents make API calls to integrated company systems to run specific actions. Gather evidence for claim 5t16u-7v.
Data classification, extraction, and analysis can be challenging for organizations that deal with volumes of documents. Traditional document processing solutions are manual, expensive, error prone, and difficult to scale. FMs are transforming the way you can solve traditionally complex document processing workloads.
In particular, we cover the SMP library’s new simplified user experience that builds on open source PyTorch Fully Sharded Data Parallel (FSDP) APIs, expanded tensor parallel functionality that enables training models with hundreds of billions of parameters, and performance optimizations that reduce model training time and cost by up to 20%.
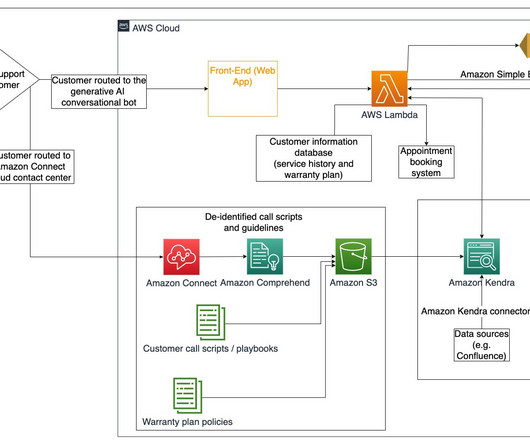
Can you provide documentation of compliance certifications? Ask about: Compatibility with your EHR Secure API integration or SFTP data exchange Real-time appointment syncing and status updates Step 6: Review Call Center Staff Training and Specialization Healthcare calls require knowledgeable and empathetic agents. A: Not necessarily.
Organizations across industries such as retail, banking, finance, healthcare, manufacturing, and lending often have to deal with vast amounts of unstructured text documents coming from various sources, such as news, blogs, product reviews, customer support channels, and social media. Extract and analyze data from documents.
The SageMaker Python SDK provides open-source APIs and containers to train and deploy models on SageMaker, using several different ML and deep learning frameworks. BERT is pre-trained on masking random words in a sentence; in contrast, during Pegasus’s pre-training, sentences are masked from an input document. return tokenized_dataset.
wiki, informational web sites, self-service help pages, internal documentation, etc.) The intended meaning of both query and document can be lost because the search is reduced to matching component keywords and terms. Create test indexes, and load some sample documents. Install Docker. If Docker (i.e.,
Knowledge Bases for Amazon Bedrock automates synchronization of your data with your vector store, including diffing the data when it’s updated, document loading, and chunking, as well as semantic embedding. It then employs a language model to generate a response by considering both the retrieved documents and the original query.
However, complex NLQs, such as time series data processing, multi-level aggregation, and pivot or joint table operations, may yield inconsistent Python script accuracy with a zero-shot prompt. The user can use the Amazon Recognition DetectText API to extract text data from these images. Choose Next. setup.sh.
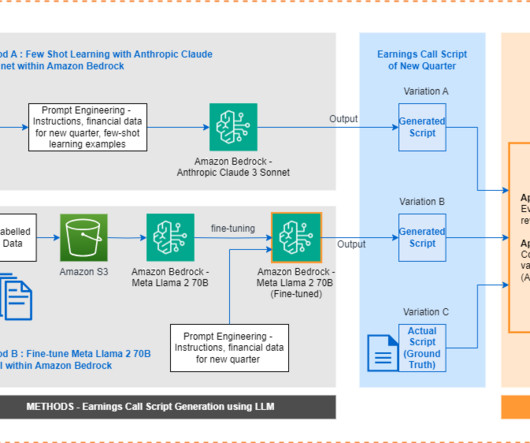
Traditionally, earnings call scripts have followed similar templates, making it a repeatable task to generate them from scratch each time. On the other hand, generative artificial intelligence (AI) models can learn these templates and produce coherent scripts when fed with quarterly financial data.
Accelerate research and analysis – Instead of manually searching through SharePoint documents, users can use Amazon Q to quickly find relevant information, summaries, and insights to support their research and decision-making. The site content space also provides access to add lists, pages, document libraries, and more.
This post takes you through the most common challenges that customers face when searching internal documents, and gives you concrete guidance on how AWS services can be used to create a generative AI conversational bot that makes internal information more useful. The cost associated with training models on recent data is high.
Amazon Rekognition makes it easy to add image analysis capability to your applications without any machine learning (ML) expertise and comes with various APIs to fulfil use cases such as object detection, content moderation, face detection and analysis, and text and celebrity recognition, which we use in this example.
Vonage API Account. To complete this tutorial, you will need a Vonage API account. Once you have an account, you can find your API Key and API Secret at the top of the Vonage API Dashboard. Web Component polyfill --> <script src="[link]. <!-- This tutorial also uses a virtual phone number.
Amazon Kendra uses deep learning and reading comprehension to deliver precise answers, and returns a list of ranked documents that match the search query for you to choose from. We first ingest a set of documents, along with their metadata, into an Amazon Kendra index. Solution overview.
OCR has been widely used in various scenarios, such as document electronization and identity authentication. Because OCR can greatly reduce the manual effort to register key information and serve as an entry step for understanding large volumes of documents, an accurate OCR system plays a crucial role in the era of digital transformation.
In this post, we’re using the APIs for AWS Support , AWS Trusted Advisor , and AWS Health to programmatically access the support datasets and use the Amazon Q Business native Amazon Simple Storage Service (Amazon S3) connector to index support data and provide a prebuilt chatbot web experience. Synchronize the data source to index the data.
Embeddings are created for documents and user questions. The document embeddings are split into chunks and stored as indexes in a vector database. The text generation workflow then takes a question’s embedding vector and uses it to retrieve the most similar document chunks based on vector similarity.
Lastly the model is tested against a set of known genome sequences using some inference API calls. Training on SageMaker We use PyTorch and Amazon SageMaker script mode to train this model. Script mode’s compatibility with PyTorch was crucial, allowing us to use our existing scripts with minimal modifications.
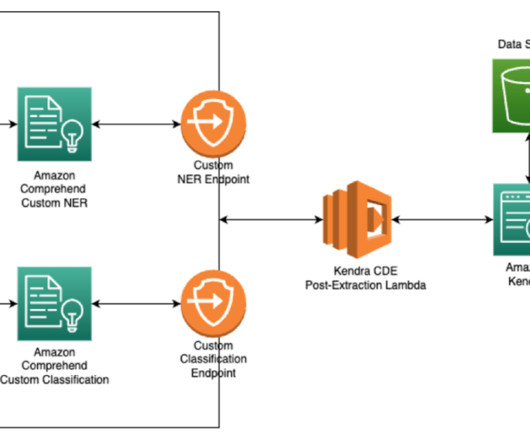
Enterprises may want to add custom metadata like document types (W-2 forms or paystubs), various entity types such as names, organization, and address, in addition to the standard metadata like file type, date created, or size to extend the intelligent search while ingesting the documents.
Here are some features which we will cover: AWS CloudFormation support Private network policies for Amazon OpenSearch Serverless Multiple S3 buckets as data sources Service Quotas support Hybrid search, metadata filters, custom prompts for the RetreiveAndGenerate API, and maximum number of retrievals.
Amazon Bedrock is a fully managed service that makes leading FMs from AI companies available through an API along with developer tooling to help build and scale generative AI applications. Instead of only fulfilling predefined intents through a static decision tree, agents are autonomous within the context of their suite of available tools.
Using architecture diagrams as an example, the solution needs to search through reference links and technical documents for architecture diagrams and identify the services present. Therefore, users without ML expertise can enjoy the benefits of a custom labels model through an API call, because a significant amount of overhead is reduced.
Today, we’re excited to announce the new synchronous API for targeted sentiment in Amazon Comprehend, which provides a granular understanding of the sentiments associated with specific entities in input documents. The Targeted Sentiment API provides the sentiment towards each entity.
Imagine the possibilities: Quick and efficient brainstorming sessions, real-time ideation, and even drafting documents or code snippets—all powered by the latest advancements in AI. The Slack application sends the event to Amazon API Gateway , which is used in the event subscription.
And testingRTC offers multiple ways to export these metrics, from direct collection from webhooks, to downloading results in CSV format using the REST API. Flip the script With testingRTC, you only need to write scripts once, you can then run them multiple times and scale them up or down as you see fit. Happy days!
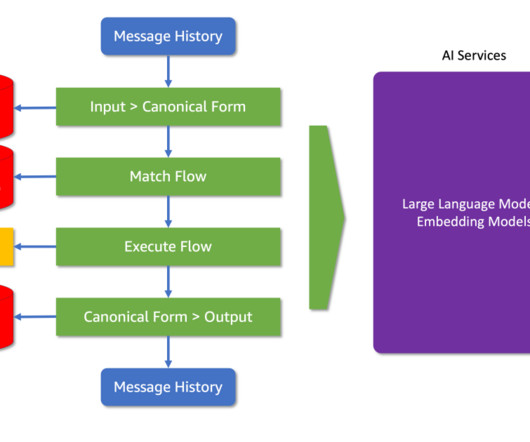
Lets delve into a basic Colang script to see how it works: define user express greeting "hello" "hi" "what's up?" define flow greeting user express greeting bot express greeting bot ask how are you In this script, we see the three fundamental types of blocks in Colang: User Message Blocks (define user ): These define possible user inputs.
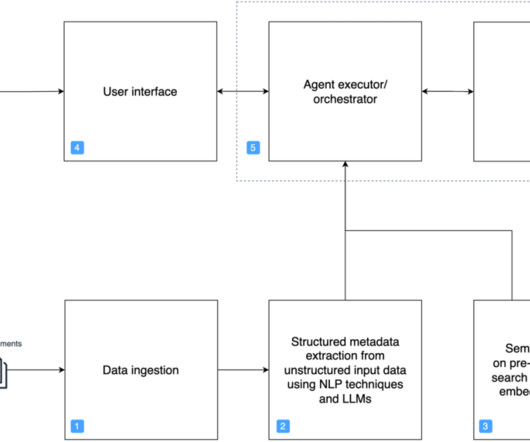
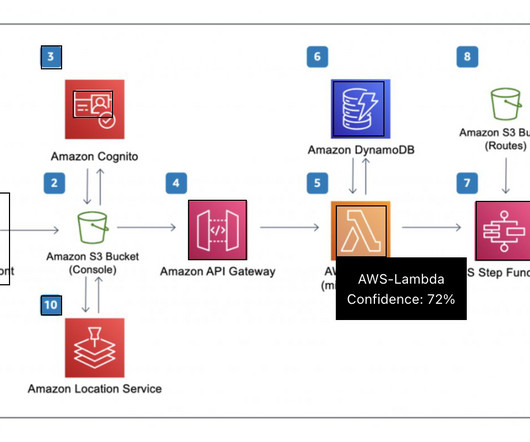
AWS Prototyping successfully delivered a scalable prototype, which solved CBRE’s business problem with a high accuracy rate (over 95%) and supported reuse of embeddings for similar NLQs, and an API gateway for integration into CBRE’s dashboards. The following diagram illustrates the web interface and API management layer.
As a JumpStart model hub customer, you get improved performance without having to maintain the model script outside of the SageMaker SDK. The inference script is prepacked with the model artifact. It develops insights by recognizing the entities, key phrases, language, sentiments, and other common elements in a document.
In some ways similar to what Keras did for TensorFlow, or even arguably Hugging Face, PyTorch Lightning provides a high-level API with abstractions for much of the lower-level functionality of PyTorch itself. For PyTorch Lightning, generally speaking, there should be little-to-no code changes to simply run these APIs on SageMaker Training.
A small number of similar documents (typically three) is added as context along with the user question to the “prompt” provided to another LLM and then that LLM generates an answer to the user question using information provided as context in the prompt. Chunking of knowledge base documents. Implementing the question answering task.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content