This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Bedrock announces the preview launch of Session Management APIs, a new capability that enables developers to simplify state and context management for generative AI applications built with popular open source frameworks such as LangGraph and LlamaIndex. Building generative AI applications requires more than model API calls.
This post presents a solution where you can upload a recording of your meeting (a feature available in most modern digital communication services such as Amazon Chime ) to a centralized video insights and summarization engine. All of this data is centralized and can be used to improve metrics in scenarios such as sales or call centers.
A reverse image search engine enables users to upload an image to find related information instead of using text-based queries. The Amazon Bedrock single API access, regardless of the models you choose, gives you the flexibility to use different FMs and upgrade to the latest model versions with minimal code changes.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
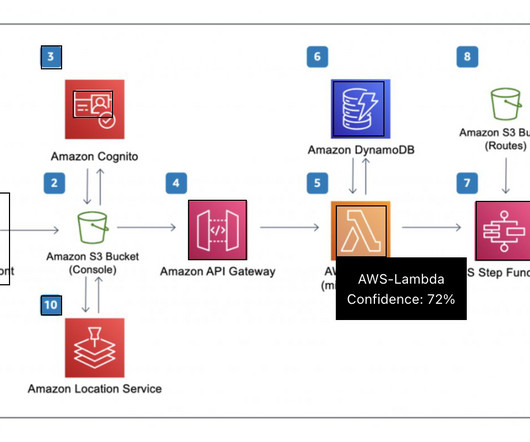
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. API Gateway is serverless and hence automatically scales with traffic. API Gateway also provides a WebSocket API. Incoming requests to the gateway go through this point.
By documenting the specific model versions, fine-tuning parameters, and prompt engineering techniques employed, teams can better understand the factors contributing to their AI systems performance. Evaluation algorithm Computes evaluation metrics to model outputs. Different algorithms have different metrics to be specified.
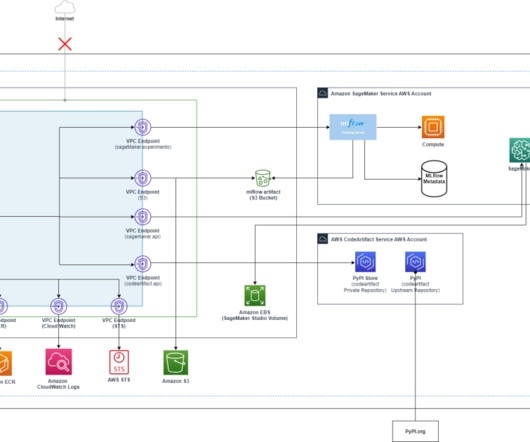
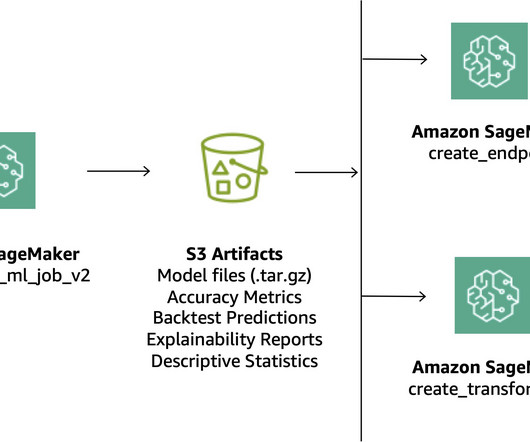
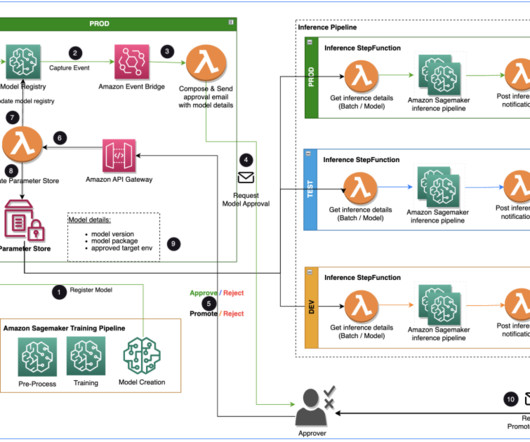
Customers can use the SageMaker Studio UI or APIs to specify the SageMaker Model Registry model to be shared and grant access to specific AWS accounts or to everyone in the organization. With this launch, customers can now seamlessly share and access ML models registered in SageMaker Model Registry between different AWS accounts.
This approach allows organizations to assess their AI models effectiveness using pre-defined metrics, making sure that the technology aligns with their specific needs and objectives. Curated judge models : Amazon Bedrock provides pre-selected, high-quality evaluation models with optimized prompt engineering for accurate assessments.
This requirement translates into time and effort investment of trained personnel, who could be support engineers or other technical staff, to review tens of thousands of support cases to arrive at an even distribution of 3,000 per category. If the use case doesnt yield discrete outputs, task-specific metrics are more appropriate.
Automated safety guards Integrated Amazon CloudWatch alarms monitor metrics on an inference component. AlarmName This CloudWatch alarm is configured to monitor metrics on an InferenceComponent. For more information about the SageMaker AI API, refer to the SageMaker AI API Reference.
During these live events, F1 IT engineers must triage critical issues across its services, such as network degradation to one of its APIs. This impacts downstream services that consume data from the API, including products such as F1 TV, which offer live and on-demand coverage of every race as well as real-time telemetry.
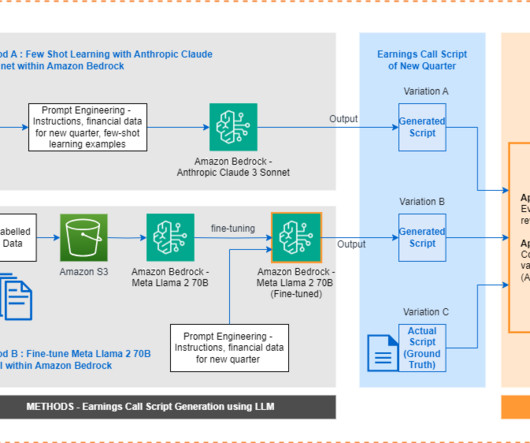
Investors and analysts closely watch key metrics like revenue growth, earnings per share, margins, cash flow, and projections to assess performance against peers and industry trends. Draft a comprehensive earnings call script that covers the key financial metrics, business highlights, and future outlook for the given quarter.
Current RAG pipelines frequently employ similarity-based metrics such as ROUGE , BLEU , and BERTScore to assess the quality of the generated responses, which is essential for refining and enhancing the models capabilities. More sophisticated metrics are needed to evaluate factual alignment and accuracy.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Use faster auto scaling metrics – Take advantage of more granular auto scaling metrics like ConcurrentRequestsPerCopy to more accurately monitor and react to changes in inference traffic. It’s a dynamic policy that adjusts the number of copies based on a specified metric, such as CPU utilization or request count.
To effectively optimize AI applications for responsiveness, we need to understand the key metrics that define latency and how they impact user experience. These metrics differ between streaming and nonstreaming modes and understanding them is crucial for building responsive AI applications.
However, keeping track of numerous experiments, their parameters, metrics, and results can be difficult, especially when working on complex projects simultaneously. SageMaker is a comprehensive, fully managed ML service designed to provide data scientists and ML engineers with the tools they need to handle the entire ML workflow.
Observability refers to the ability to understand the internal state and behavior of a system by analyzing its outputs, logs, and metrics. Evaluation, on the other hand, involves assessing the quality and relevance of the generated outputs, enabling continual improvement.
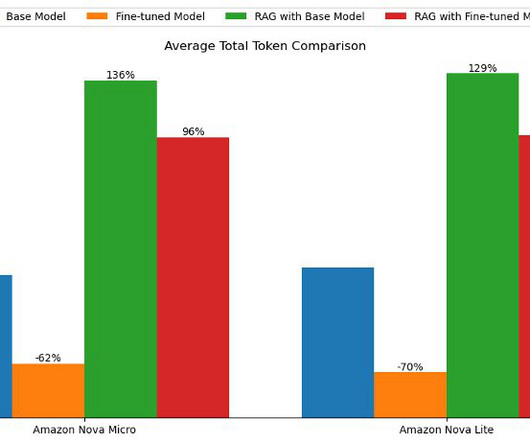
How do Amazon Nova Micro and Amazon Nova Lite perform against GPT-4o mini in these same metrics? Amazon Bedrock APIs make it straightforward to use Amazon Titan Text Embeddings V2 for embedding data. Vector database FloTorch selected Amazon OpenSearch Service as a vector database for its high-performance metrics.
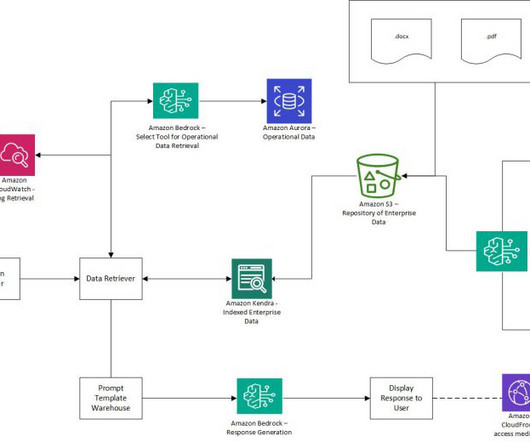
Verisk has embraced this technology and has developed their own Instant Insight Engine, or AI companion, that provides an enhanced self-service capability to their FAST platform. First, they used the Amazon Kendra Retrieve API to get multiple relevant passages and excerpts based on keyword search.
To address the problems associated with complex searches, this post describes in detail how you can achieve a search engine that is capable of searching for complex images by integrating Amazon Kendra and Amazon Rekognition. Users may have to manually filter out unsuitable image results when dealing with complex searches.
Fine-tune an Amazon Nova model using the Amazon Bedrock API In this section, we provide detailed walkthroughs on fine-tuning and hosting customized Amazon Nova models using Amazon Bedrock. We first provided a detailed walkthrough on how to fine-tune, host, and conduct inference with customized Amazon Nova through the Amazon Bedrock API.
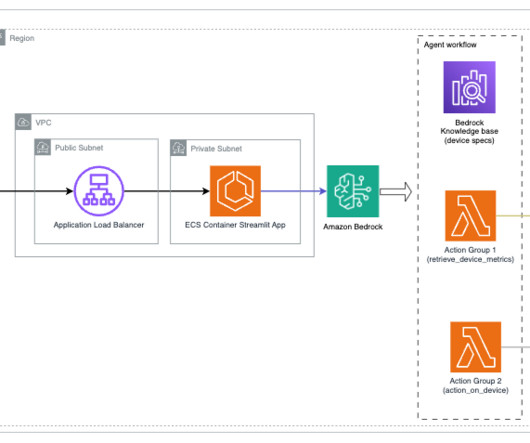
Amazon Bedrock agents use LLMs to break down tasks, interact dynamically with users, run actions through API calls, and augment knowledge using Amazon Bedrock Knowledge Bases. In this post, we demonstrate how to use Amazon Bedrock Agents with a web search API to integrate dynamic web content in your generative AI application.
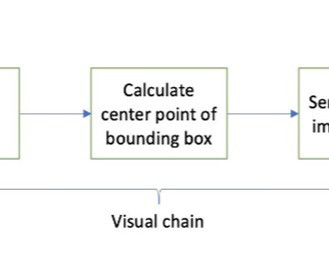
Prompt engineering has become an essential skill for anyone working with large language models (LLMs) to generate high-quality and relevant texts. Although text prompt engineering has been widely discussed, visual prompt engineering is an emerging field that requires attention.
It enables you to privately customize the FM of your choice with your data using techniques such as fine-tuning, prompt engineering, and retrieval augmented generation (RAG) and build agents that run tasks using your enterprise systems and data sources while adhering to security and privacy requirements.
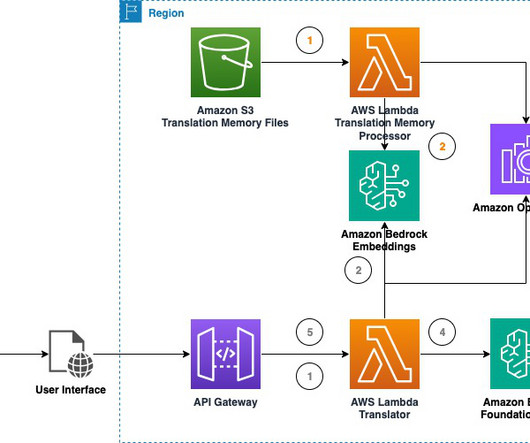
The solution proposed in this post relies on LLMs context learning capabilities and prompt engineering. The translation playground could be adapted into a scalable serverless solution as represented by the following diagram using AWS Lambda , Amazon Simple Storage Service (Amazon S3), and Amazon API Gateway.
Amazon Lookout for Metrics is a fully managed service that uses machine learning (ML) to detect anomalies in virtually any time-series business or operational metrics—such as revenue performance, purchase transactions, and customer acquisition and retention rates—with no ML experience required.
In this post, we describe the enhancements to the forecasting capabilities of SageMaker Canvas and guide you on using its user interface (UI) and AutoML APIs for time-series forecasting. While the SageMaker Canvas UI offers a code-free visual interface, the APIs empower developers to interact with these features programmatically.
Although automated metrics are fast and cost-effective, they can only evaluate the correctness of an AI response, without capturing other evaluation dimensions or providing explanations of why an answer is problematic. Human evaluation, although thorough, is time-consuming and expensive at scale.
For instance, Pixtral Large is highly effective at spotting irregularities or insightful trends within training loss curves or performance metrics, enhancing the accuracy of data-driven decision-making. By choosing View API , you can also access the model using code examples in the AWS Command Line Interface (AWS CLI) and AWS SDKs.
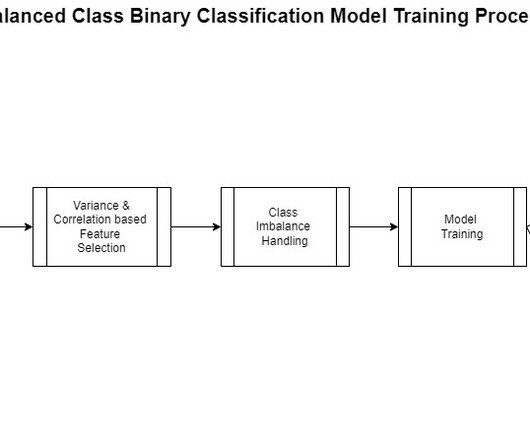
One aspect of this data preparation is feature engineering. Feature engineering refers to the process where relevant variables are identified, selected, and manipulated to transform the raw data into more useful and usable forms for use with the ML algorithm used to train a model and perform inference against it.
In February 2022, Amazon Web Services added support for NVIDIA GPU metrics in Amazon CloudWatch , making it possible to push metrics from the Amazon CloudWatch Agent to Amazon CloudWatch and monitor your code for optimal GPU utilization. Then we explore two architectures. already installed. eks-create.sh 19 private:192.168.128.0/19
Amazon Q Business only provides metric information that you can use to monitor your data source sync jobs. With the connector ready, move over to the SageMaker Studio notebook and perform data synchronization operations by invoking Amazon Q Business APIs. secrets_manager_client = boto3.client('secretsmanager')
Conversational artificial intelligence (AI) assistants are engineered to provide precise, real-time responses through intelligent routing of queries to the most suitable AI functions. With AWS generative AI services like Amazon Bedrock , developers can create systems that expertly manage and respond to user requests. What is an AI assistant?
Leave the session inspired to bring Amazon Q Apps to supercharge your teams’ productivity engines. Gain insights into training strategies, productivity metrics, and real-world use cases to empower your developers to harness the full potential of this game-changing technology.
Specialist Data Engineering at Merck, and Prabakaran Mathaiyan, Sr. ML Engineer at Tiger Analytics. The solution uses AWS Lambda , Amazon API Gateway , Amazon EventBridge , and SageMaker to automate the workflow with human approval intervention in the middle. API Gateway invokes a Lambda function to initiate model updates.
It’s a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like Anthropic, Cohere, Meta, Mistral AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
In software engineering, there is a direct correlation between team performance and building robust, stable applications. The data community aims to adopt the rigorous engineering principles commonly used in software development into their own practices, which includes systematic approaches to design, development, testing, and maintenance.
This process enhances task-specific model performance, allowing the model to handle custom use cases with task-specific performance metrics that meet or surpass more powerful models like Anthropic Claude 3 Sonnet or Anthropic Claude 3 Opus. Under Output data , for S3 location , enter the S3 path for the bucket storing fine-tuning metrics.
Performance metrics and benchmarks According to Mistral, the instruction-tuned version of the model achieves over 81% accuracy on Massive Multitask Language Understanding (MMLU) with 150 tokens per second latency, making it currently the most efficient model in its category. It doesnt support Converse APIs or other Amazon Bedrock tooling.
AWS Prototyping successfully delivered a scalable prototype, which solved CBRE’s business problem with a high accuracy rate (over 95%) and supported reuse of embeddings for similar NLQs, and an API gateway for integration into CBRE’s dashboards. The following diagram illustrates the web interface and API management layer.
This is guest post by Andy Whittle, Principal Platform Engineer – Application & Reliability Frameworks at The Very Group. The overriding goal for The Very Group’s engineering team was to prevent any PII data from reaching documents within Elasticsearch. Overview of solution. Some decisions had to be made to enable the solution.
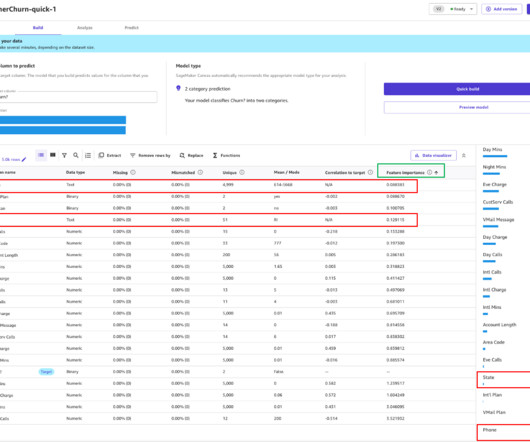
It also enables you to evaluate the models using advanced metrics as if you were a data scientist. In this post, we show how a business analyst can evaluate and understand a classification churn model created with SageMaker Canvas using the Advanced metrics tab. The F1 score provides a balanced evaluation of the model’s performance.
In 2021, Applus+ IDIADA , a global partner to the automotive industry with over 30 years of experience supporting customers in product development activities through design, engineering, testing, and homologation services, established the Digital Solutions department. The batch size is set to 64.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content