This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Bedrock APIs make it straightforward to use Amazon Titan Text Embeddings V2 for embedding data. The implementation used the universal gateway provided by the FloTorch enterprise version to enable consistent API calls using the same function and to track token count and latency metrics uniformly. get("message", {}).get("content")
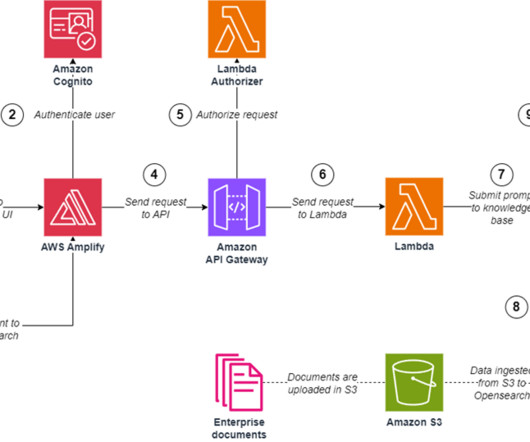
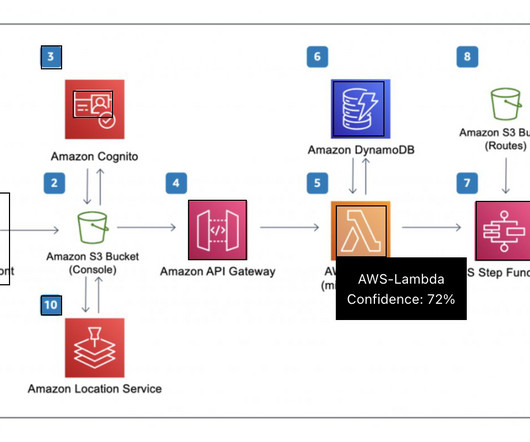
The solution also uses Amazon Cognito user pools and identity pools for managing authentication and authorization of users, Amazon API Gateway REST APIs, AWS Lambda functions, and an Amazon Simple Storage Service (Amazon S3) bucket. To launch the solution in a different Region, change the aws_region parameter accordingly.
Customers can use the SageMaker Studio UI or APIs to specify the SageMaker Model Registry model to be shared and grant access to specific AWS accounts or to everyone in the organization. We will start by using the SageMaker Studio UI and then by using APIs.
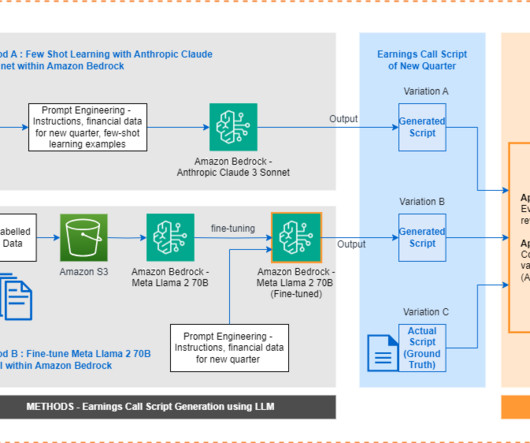
Traditionally, earnings call scripts have followed similar templates, making it a repeatable task to generate them from scratch each time. On the other hand, generative artificial intelligence (AI) models can learn these templates and produce coherent scripts when fed with quarterly financial data.
The top-level definitions of these abstractions are included as part of the prompt context for query generation, and the full definitions are provided to the SQL execution engine, along with the generated query. Depending on the use case, this can be a static or dynamically generated script. A domain-specific user prompt.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
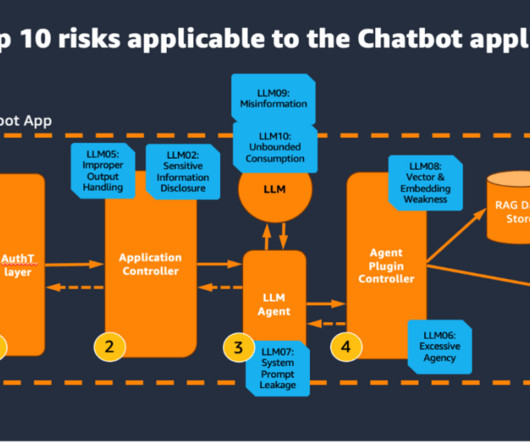
These steps might involve both the use of an LLM and external data sources and APIs. Agent plugin controller This component is responsible for the API integration to external data sources and APIs. The LLM agent is an orchestrator of a set of steps that might be necessary to complete the desired request.
This requirement translates into time and effort investment of trained personnel, who could be support engineers or other technical staff, to review tens of thousands of support cases to arrive at an even distribution of 3,000 per category. Sonnet prediction accuracy through prompt engineering. client = boto3.client("bedrock-runtime",
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon with a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Amazon Bedrock is a fully managed service that makes a wide range of foundation models (FMs) available though an API without having to manage any infrastructure. An Amazon OpenSearch Serverless vector engine to store enterprise data as vectors to perform semantic search. The request is sent by the web application to the API.
Amazon Bedrock agents use LLMs to break down tasks, interact dynamically with users, run actions through API calls, and augment knowledge using Amazon Bedrock Knowledge Bases. In this post, we demonstrate how to use Amazon Bedrock Agents with a web search API to integrate dynamic web content in your generative AI application.
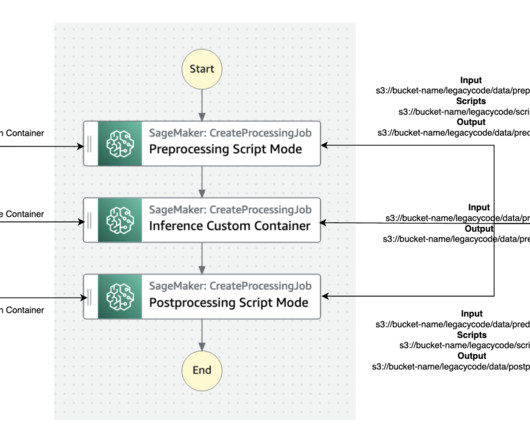
The best practice for migration is to refactor these legacy codes using the Amazon SageMaker API or the SageMaker Python SDK. We demonstrate how two different personas, a data scientist and an MLOps engineer, can collaborate to lift and shift hundreds of legacy models. SageMaker runs the legacy script inside a processing container.
We recommend running similar scripts only on your own data sources after consulting with the team who manages them, or be sure to follow the terms of service for the sources that youre trying to fetch data from. A simple architectural representation of the steps involved is shown in the following figure. secrets_manager_client = boto3.client('secretsmanager')
To address the problems associated with complex searches, this post describes in detail how you can achieve a search engine that is capable of searching for complex images by integrating Amazon Kendra and Amazon Rekognition. A Python script is used to aid in the process of uploading the datasets and generating the manifest file.
In the post Secure Amazon SageMaker Studio presigned URLs Part 2: Private API with JWT authentication , we demonstrated how to build a private API to generate Amazon SageMaker Studio presigned URLs that are only accessible by an authenticated end-user within the corporate network from a single account.
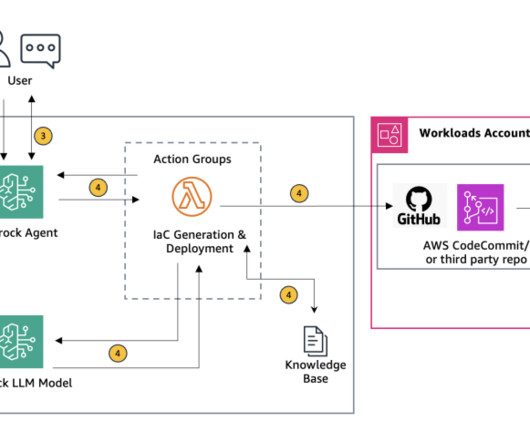
Agents for Amazon Bedrock automates the prompt engineering and orchestration of user-requested tasks. This solution uses Retrieval Augmented Generation (RAG) to ensure the generated scripts adhere to organizational needs and industry standards. A GitHub account with a repository to store the generated Terraform scripts.
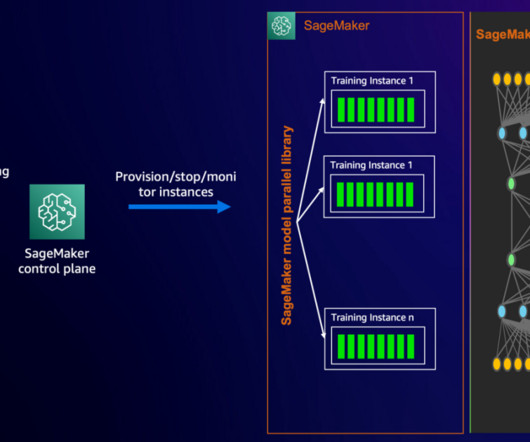
In particular, we cover the SMP library’s new simplified user experience that builds on open source PyTorch Fully Sharded Data Parallel (FSDP) APIs, expanded tensor parallel functionality that enables training models with hundreds of billions of parameters, and performance optimizations that reduce model training time and cost by up to 20%.
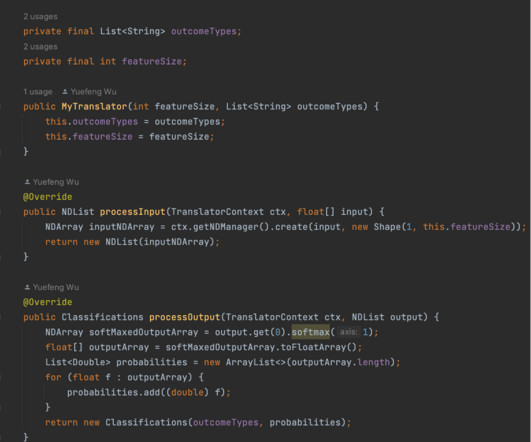
The SageMaker Python SDK provides open-source APIs and containers to train and deploy models on SageMaker, using several different ML and deep learning frameworks. Build your training script for the Hugging Face SageMaker estimator. script to use with Script Mode and pass hyperparameters for training. to(device).
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API. The scripts for fine-tuning and evaluation are available on the GitHub repository.
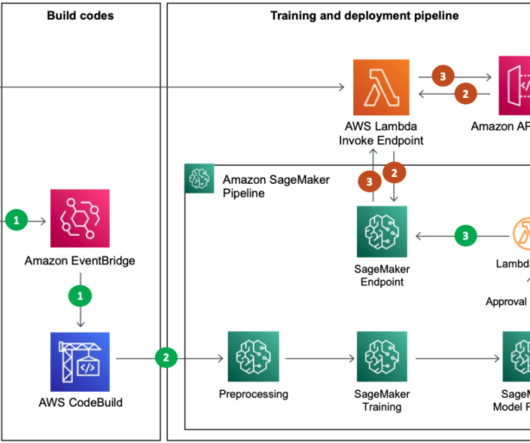
The main AWS services used are SageMaker, Amazon EMR , AWS CodeBuild , Amazon Simple Storage Service (Amazon S3), Amazon EventBridge , AWS Lambda , and Amazon API Gateway. Real-time recommendation inference The inference phase consists of the following steps: The client application makes an inference request to the API gateway.
Inference API – The server exposes an API that allows client applications to send input data and receive predictions from the deployed models. Integration with backend engines – Model servers have integrations with backend frameworks like DeepSpeed and FasterTransformer to partition large models and run highly optimized inference.
using open source or commercial-off-the-shelf search engines, then you’re probably familiar with the inherent accuracy challenges involved in getting relevant search results. You need your search engine to be smarter so it can rank documents based on matching the meaning or semantics of the content to the intention of the user’s query.
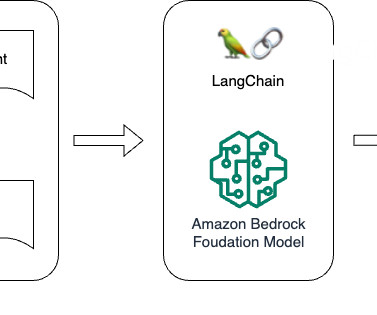
The solution also uses Amazon Bedrock , a fully managed service that makes foundation models (FMs) from Amazon and third-party model providers accessible through the AWS Management Console and APIs. First, we discuss those two prompt engineering techniques, then we show their implementation using LangChain and Amazon Bedrock.
Amazon Bedrock is a fully managed service that makes FMs from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. Solution overview The solution comprises two main steps: Generate synthetic data using the Amazon Bedrock InvokeModel API.
Wipro further accelerated their ML model journey by implementing Wipro’s code accelerators and snippets to expedite feature engineering, model training, model deployment, and pipeline creation. Wipro has used the input filter and join functionality of SageMaker batch transformation API.
An asynchronous API and Amazon OpenSearch Service connector make it easy to integrate the model into your neural search applications. Before you can write scripts that use the Amazon Bedrock API, you need to install the appropriate version of the AWS SDK in your environment. The vectors power speedy, accurate search experiences.
This often means the method of using a third-party LLM API won’t do for security, control, and scale reasons. It provides an approachable, robust Python API for the full infrastructure stack of ML/AI, from data and compute to workflows and observability. The following figure illustrates this workflow.
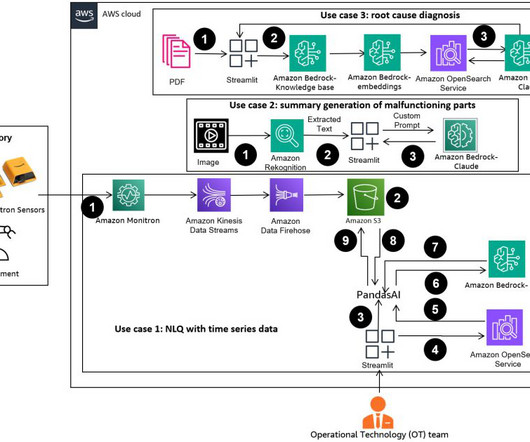
Workers gain productivity through AI-generated insights, engineers can proactively detect anomalies, supply chain managers optimize inventories, and plant leadership makes informed, data-driven decisions. The user can use the Amazon Recognition DetectText API to extract text data from these images. setup.sh. (a
Amazon SageMaker Feature Store is a purpose-built feature management solution that helps data scientists and ML engineers securely store, discover, and share curated data used in training and prediction workflows. In this example, we ingest records using the FeatureGroup.ingest() API, which ingests records from a Pandas DataFrame.
The Slack application sends the event to Amazon API Gateway , which is used in the event subscription. API Gateway forwards the event to an AWS Lambda function. About the Authors Rushabh Lokhande is a Senior Data & ML Engineer with AWS Professional Services Analytics Practice.
AWS Prototyping successfully delivered a scalable prototype, which solved CBRE’s business problem with a high accuracy rate (over 95%) and supported reuse of embeddings for similar NLQs, and an API gateway for integration into CBRE’s dashboards. The following diagram illustrates the web interface and API management layer.
Machine learning (ML) experts, data scientists, engineers and enthusiasts have encountered this problem the world over. In some ways similar to what Keras did for TensorFlow, or even arguably Hugging Face, PyTorch Lightning provides a high-level API with abstractions for much of the lower-level functionality of PyTorch itself.
The function then searches the OpenSearch Service image index for images matching the celebrity name and the k-nearest neighbors for the vector using cosine similarity using Exact k-NN with scoring script. Go to the CloudFormation console, choose the stack that you deployed through the deploy script mentioned previously, and delete the stack.
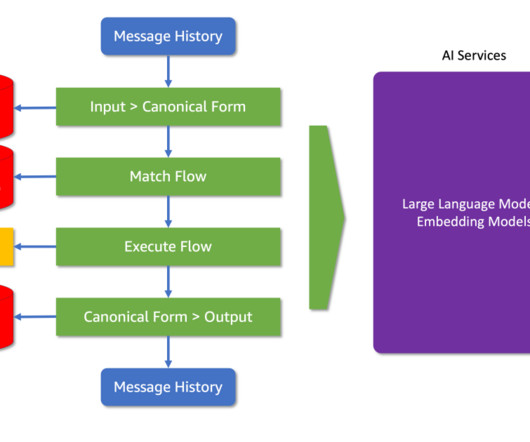
Lets delve into a basic Colang script to see how it works: define user express greeting "hello" "hi" "what's up?" define flow greeting user express greeting bot express greeting bot ask how are you In this script, we see the three fundamental types of blocks in Colang: User Message Blocks (define user ): These define possible user inputs.
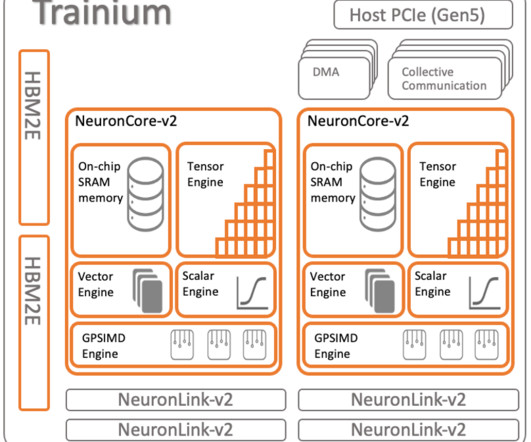
Trainium support for custom operators Trainium (and AWS Inferentia2) supports CustomOps in software through the Neuron SDK and accelerates them in hardware using the GPSIMD engine (General Purpose Single Instruction Multiple Data engine). The scalar and vector engines are highly parallelized and optimized for floating-point operations.
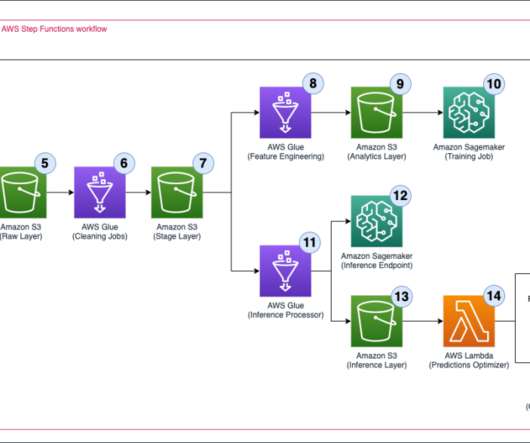
This is a guest post by Viktor Enrico Jeney, Senior Machine Learning Engineer at Adspert. The repricing ML model is a Scikit-Learn Random Forest implementation in SageMaker Script Mode, which is trained using data available in the S3 bucket (the analytics layer). This may be different to the partitioning used on the stage layer.
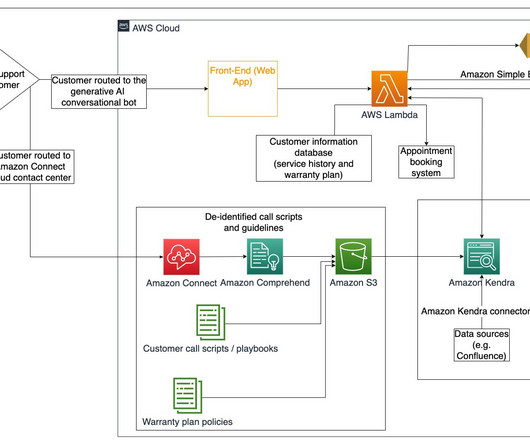
Amazon API Gateway hosts a REST API with various endpoints to handle user requests that are authenticated using Amazon Cognito. Finally, the response is sent back to the user via a HTTPs request through the Amazon API Gateway REST API integration response. The web application front-end is hosted on AWS Amplify.
The SMP library uses NVIDIA Megatron to implement expert parallelism and support training MoE models, and runs on top of PyTorch Fully Sharded Data Parallel (FSDP) APIs. With SageMaker training jobs, you can launch and manage clusters of high-performance instances with simple API calls. In this example, we use SageMaker training jobs.
Our data scientists train the model in Python using tools like PyTorch and save the model as PyTorch scripts. Ideally, we instead want to load the model PyTorch scripts, extract the features from model input, and run model inference entirely in Java. They use the DJL PyTorch engine to initialize the model predictor.
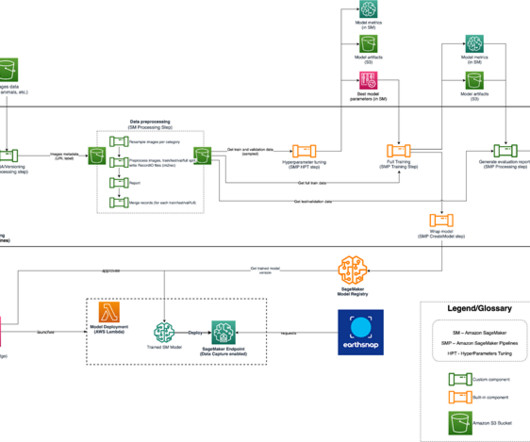
This post explains how Provectus and Earth.com were able to enhance the AI-powered image recognition capabilities of EarthSnap, reduce engineering heavy lifting, and minimize administrative costs by implementing end-to-end ML pipelines, delivered as part of a managed MLOps platform and managed AI services.
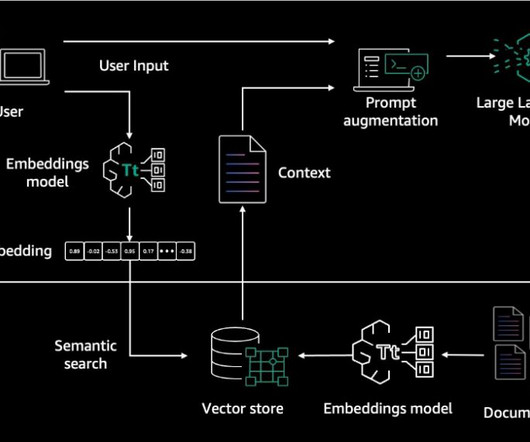
The integration of retrieval and generation also requires additional engineering effort and computational resources. For text generation, Amazon Bedrock provides the RetrieveAndGenerate API to create embeddings of user queries, and retrieves relevant chunks from the vector database to generate accurate responses.
Any additional mappings need to be set in the user store using the user store APIs. Overview of solution This post presents the steps to create a certificate and private key, configure Azure AD (either using the Azure AD console or a PowerShell script), and configure Amazon Q Business. Using the provided PowerShell script.
Gramener’s GeoBox solution empowers users to effortlessly tap into and analyze public geospatial data through its powerful API, enabling seamless integration into existing workflows. With the SearchRasterDataCollection API, SageMaker provides a purpose-built functionality to facilitate the retrieval of satellite imagery.
The retrieve_and_generate API does both the retrieval and a call to an FM (Amazon Titan or Anthropic’s Claude family of models on Amazon Bedrock ), for a fully managed solution. The retriever isn’t at fault, the problem is with FM generation (evaluated by a human or LLM): Try prompt engineering to mitigate hallucinations.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content