This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
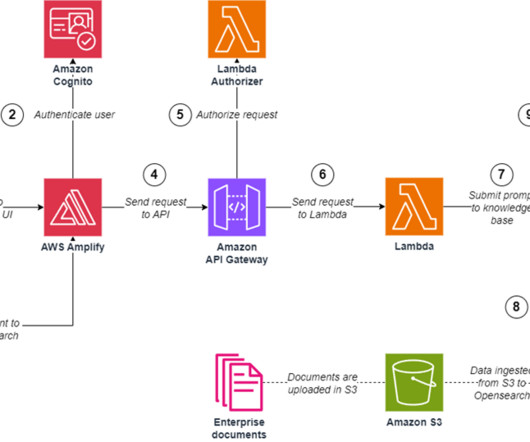
The custom Google Chat app, configured for HTTP integration, sends an HTTP request to an API Gateway endpoint. Before processing the request, a Lambda authorizer function associated with the API Gateway authenticates the incoming message. A Business or Enterprise Google Workspace account with access to Google Chat.
These models offer enterprises a range of capabilities, balancing accuracy, speed, and cost-efficiency. Using its enterprise software, FloTorch conducted an extensive comparison between Amazon Nova models and OpenAIs GPT-4o models with the Comprehensive Retrieval Augmented Generation (CRAG) benchmark dataset.
The solution also uses Amazon Cognito user pools and identity pools for managing authentication and authorization of users, Amazon API Gateway REST APIs, AWS Lambda functions, and an Amazon Simple Storage Service (Amazon S3) bucket. To launch the solution in a different Region, change the aws_region parameter accordingly.
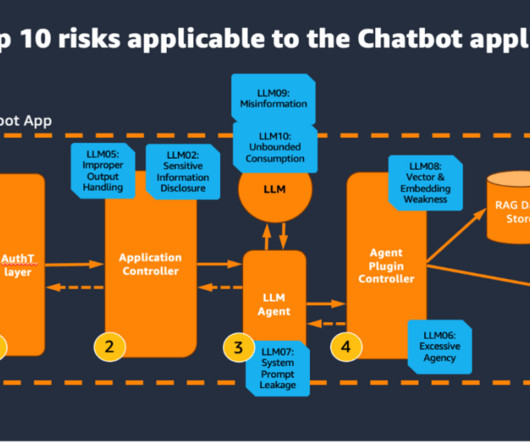
These steps might involve both the use of an LLM and external data sources and APIs. Agent plugin controller This component is responsible for the API integration to external data sources and APIs. The LLM agent is an orchestrator of a set of steps that might be necessary to complete the desired request.
The goal was to refine customer service scripts, provide coaching opportunities for agents, and improve call handling processes. Frontend and API The CQ application offers a robust search interface specially crafted for call quality agents, equipping them with powerful auditing capabilities for call analysis.
Customers can use the SageMaker Studio UI or APIs to specify the SageMaker Model Registry model to be shared and grant access to specific AWS accounts or to everyone in the organization. We will start by using the SageMaker Studio UI and then by using APIs. To get started, set-up a name for your experiment.
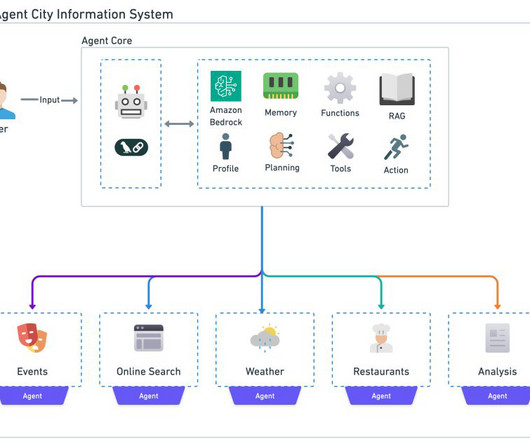
By using the power of LLMs and combining them with specialized tools and APIs, agents can tackle complex, multistep tasks that were previously beyond the reach of traditional AI systems. Whenever local database information is unavailable, it triggers an online search using the Tavily API. Its used by the weather_agent() function.
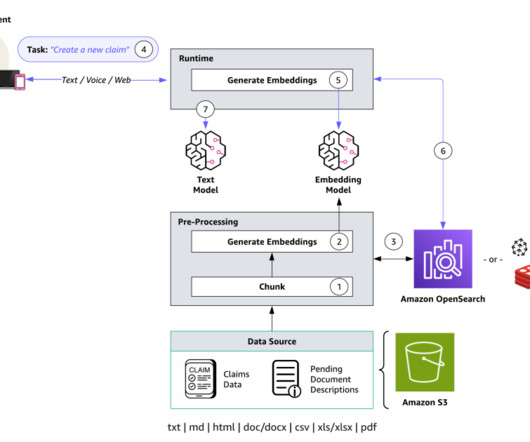
With the rise of generative artificial intelligence (AI), an increasing number of organizations use digital assistants to have their end-users ask domain-specific questions, using Retrieval Augmented Generation (RAG) over their enterprise data sources. The request is sent by the web application to the API.
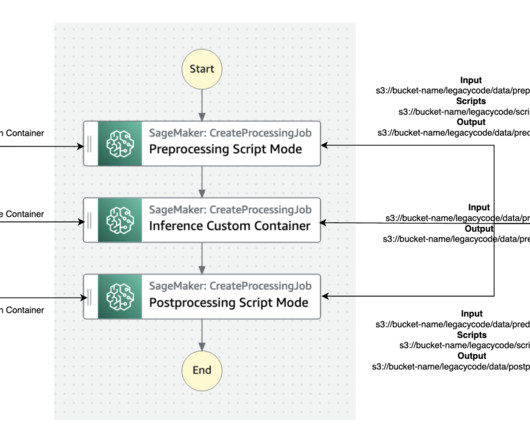
The best practice for migration is to refactor these legacy codes using the Amazon SageMaker API or the SageMaker Python SDK. SageMaker runs the legacy script inside a processing container. Step Functions is a serverless workflow service that can control SageMaker APIs directly through the use of the Amazon States Language.
Refer to Getting started with the API to set up your environment to make Amazon Bedrock requests through the AWS API. Test the code using the native inference API for Anthropics Claude The following code uses the native inference API to send a text message to Anthropics Claude. client = boto3.client("bedrock-runtime",
To build a generative AI -based conversational application integrated with relevant data sources, an enterprise needs to invest time, money, and people. Alation is a data intelligence company serving more than 600 global enterprises, including 40% of the Fortune 100. This blog post is co-written with Gene Arnold from Alation.
Generative AI agents are a versatile and powerful tool for large enterprises. At the forefront of this evolution sits Amazon Bedrock , a fully managed service that makes high-performing foundation models (FMs) from Amazon and other leading AI companies available through an API.
Enterprise customers have multiple lines of businesses (LOBs) and groups and teams within them. These enterprise customers that are starting to adopt AWS, expanding their footprint on AWS, or plannng to enhance an established AWS environment need to ensure they have a strong foundation for their cloud environment.
As successful proof-of-concepts transition into production, organizations are increasingly in need of enterprise scalable solutions. This post explores the new enterprise-grade features for Knowledge Bases on Amazon Bedrock and how they align with the AWS Well-Architected Framework.
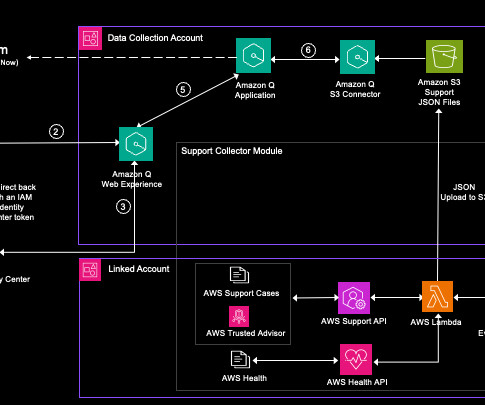
Amazon Q Business is a fully managed, secure, generative-AI powered enterprise chat assistant that enables natural language interactions with your organization’s data. The AWS Support, AWS Trusted Advisor, and AWS Health APIs are available for customers with Enterprise Support, Enterprise On-Ramp, or Business support plans.
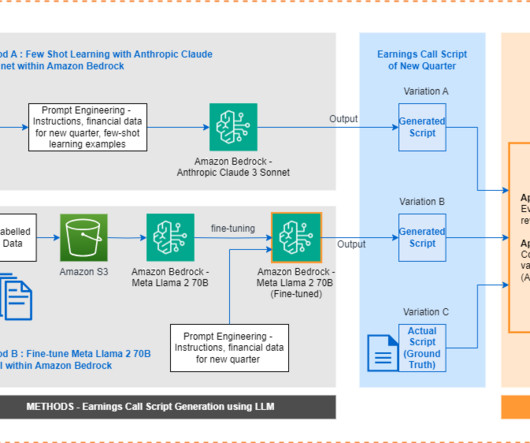
Traditionally, earnings call scripts have followed similar templates, making it a repeatable task to generate them from scratch each time. On the other hand, generative artificial intelligence (AI) models can learn these templates and produce coherent scripts when fed with quarterly financial data.
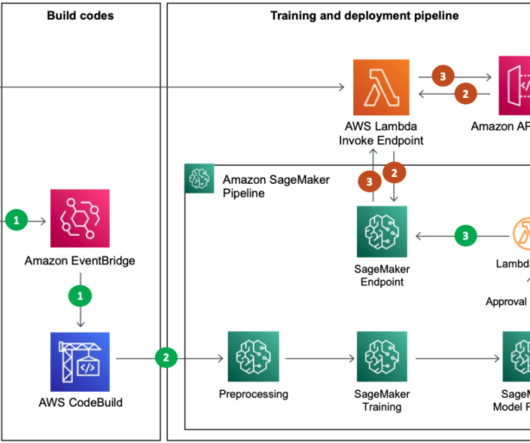
The first allows you to run a Python script from any server or instance including a Jupyter notebook; this is the quickest way to get started. In the following sections, we first describe the script solution, followed by the AWS CDK construct solution. The following diagram illustrates the sequence of events within the script.
The main AWS services used are SageMaker, Amazon EMR , AWS CodeBuild , Amazon Simple Storage Service (Amazon S3), Amazon EventBridge , AWS Lambda , and Amazon API Gateway. Real-time recommendation inference The inference phase consists of the following steps: The client application makes an inference request to the API gateway.
CBRE’s data environment, with 39 billion data points from over 300 sources, combined with a suite of enterprise-grade technology can deploy a range of AI solutions to enable individual productivity all the way to broadscale transformation. The following diagram illustrates the web interface and API management layer.
Generative AI (GenAI) and large language models (LLMs), such as those available soon via Amazon Bedrock and Amazon Titan are transforming the way developers and enterprises are able to solve traditionally complex challenges related to natural language processing and understanding.
Business SMS allows any company on our Advanced and Enterprise Plans to send and receive SMS messages through the VirtualPBX Softphone on their desktop and mobile devices. Using The VirtualPBX API to Assist. You can also manage your hooks outside of the VirtualPBX web interface by taking advantage of our API.
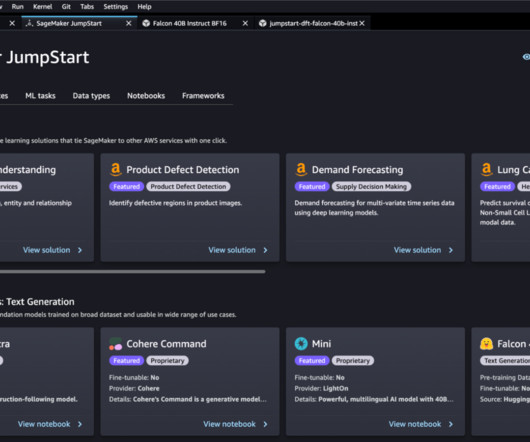
We explore two ways of obtaining the same result: via JumpStart’s graphical interface on Amazon SageMaker Studio , and programmatically through JumpStart APIs. If you want to jump straight into the JumpStart API code we go through in this post, you can refer to the following sample Jupyter notebook: Introduction to JumpStart – Text to Image.
Generative AI is quickly transforming how enterprises do business. Gartner predicts that “by 2026, more than 80% of enterprises will have used generative AI APIs or models, or deployed generative AI-enabled applications in production environments, up from less than 5% in 2023.”
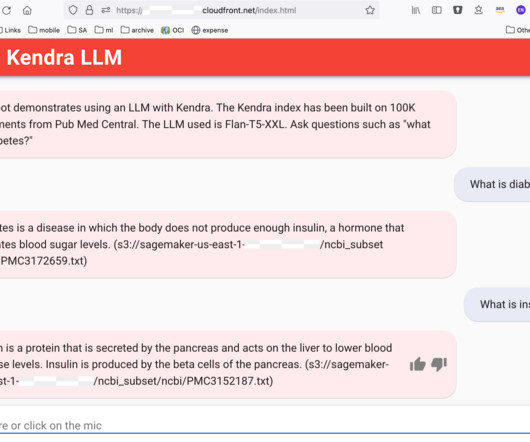
Dataset collection We followed the methodology outlined in the PMC-Llama paper [6] to assemble our dataset, which includes PubMed papers sourced from the Semantic Scholar API and various medical texts cited within the paper, culminating in a comprehensive collection of 88 billion tokens. Create and launch ParallelCluster in the VPC.
The Slack application sends the event to Amazon API Gateway , which is used in the event subscription. API Gateway forwards the event to an AWS Lambda function. In the following sections, we guide you through the process of setting up a Slack integration for Amazon Bedrock. The following diagram illustrates the solution architecture.
Snowflake Arctic is a family of enterprise-grade large language models (LLMs) built by Snowflake to cater to the needs of enterprise users, exhibiting exceptional capabilities (as shown in the following benchmarks ) in SQL querying, coding, and accurately following instructions. To learn more, refer to API documentation.
Enterprises that operate globally are experiencing challenges sourcing customer support professionals with multi-lingual experience. This process can be cost-prohibitive and difficult to scale, leading many enterprises to only support English for chats. Take note of the API key and the API endpoint created during the deployment.
Enterprise search is a critical component of organizational efficiency through document digitization and knowledge management. Enterprise search covers storing documents such as digital files, indexing the documents for search, and providing relevant results based on user queries. script to preprocess and index the provided demo data.
Amazon Q can help you get fast, relevant answers to pressing questions, solve problems, generate content, and take actions using the data and expertise found in your company’s information repositories and enterprise systems. Amazon Q uses the chat_sync API to carry out the conversation. You can also find the script on the GitHub repo.
Its AI/ML solutions drive enhanced operational efficiency, productivity, and customer experience for many of their enterprise clients. Model training: Using the SageMaker SDK, this step runs training code with the respective model image and trains datasets from pre-processing scripts while generating the trained model artifacts.
An asynchronous API and Amazon OpenSearch Service connector make it easy to integrate the model into your neural search applications. Before you can write scripts that use the Amazon Bedrock API, you need to install the appropriate version of the AWS SDK in your environment. The vectors power speedy, accurate search experiences.
You can fine-tune and deploy JumpStart models using the UI in Amazon SageMaker Studio or using the SageMaker Python SDK extension for JumpStart APIs. This post focuses on how we can implement MLOps with JumpStart models using JumpStart APIs, Amazon SageMaker Pipelines , and Amazon SageMaker Projects. sm_client = boto3.client("sagemaker")
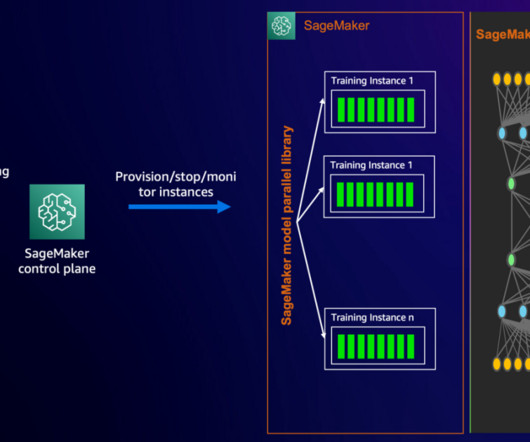
The SMP library uses NVIDIA Megatron to implement expert parallelism and support training MoE models, and runs on top of PyTorch Fully Sharded Data Parallel (FSDP) APIs. With SageMaker training jobs, you can launch and manage clusters of high-performance instances with simple API calls. In this example, we use SageMaker training jobs.
Enterprise customers in tightly controlled industries such as healthcare and finance set up security guardrails to ensure their data is encrypted and traffic doesn’t traverse the internet. Additionally, each API call can have its own configurations. Then it copies the file into the default location for Studio notebooks.
Amazon API Gateway hosts a REST API with various endpoints to handle user requests that are authenticated using Amazon Cognito. Finally, the response is sent back to the user via a HTTPs request through the Amazon API Gateway REST API integration response. The web application front-end is hosted on AWS Amplify.
We explore two ways of obtaining the same result: via JumpStart’s graphical interface on Amazon SageMaker Studio , and programmatically through JumpStart APIs. The following sections provide a step-by-step demo to perform inference, both via the Studio UI and via JumpStart APIs. JumpStart overview. Text generation, GPT-2, and Bloom.
Integrating proprietary enterprise data from internal knowledge bases enables chatbots to contextualize their responses to each user’s individual needs and interests. We currently support four vector engine types: the vector engine for Amazon OpenSearch Serverless, Amazon Aurora, Pinecone, and Redis Enterprise Cloud. Choose Next.
Solution overview The following figure illustrates the proposed target MLOps architecture for enterprise batch inference for organizations who use GitLab CI/CD and Terraform infrastructure as code (IaC) in conjunction with AWS tools and services. The data scientist can review and approve the new version of the model independently.
We explore two ways of obtaining the same result: via JumpStart’s graphical interface on Amazon SageMaker Studio , and programmatically through JumpStart APIs. The following sections provide a step-by-step demo to perform semantic segmentation with JumpStart, both via the Studio UI and via JumpStart APIs. Semantic segmentation.
Furthermore, TechSee’s technology can be integrated anywhere through APIs or SDKs. To ensure that new technologies are embraced and utilized to their fullest, they must be integrated smoothly into the existing agent dashboards and scripts, requiring minimal shifts from established routines.
Furthermore, TechSee’s technology can be integrated anywhere through APIs or SDKs. To ensure that new technologies are embraced and utilized to their fullest, they must be integrated smoothly into the existing agent dashboards and scripts, requiring minimal shifts from established routines.
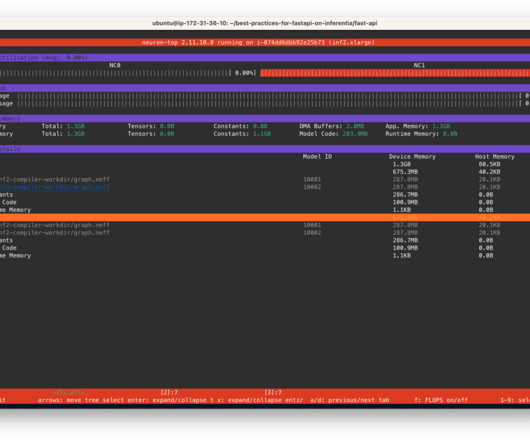
If the model changes on the server side, the client has to know and change its API call to the new endpoint accordingly. Clone the Github repository The GitHub repo provides all the scripts necessary to deploy models using FastAPI on NeuronCores on AWS Inferentia instances. code as the entry point. compiled-model-bs-{batch_size}.pt')
Amazon Q Business is a fully managed, generative artificial intelligence (AI)-powered assistant that helps enterprises unlock the value of their data and knowledge. Any additional mappings need to be set in the user store using the user store APIs. You can use the following PowerShell script to create a self-signed certificate.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content