This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
From gaming and entertainment to education and corporate events, live streams have become a powerful medium for real-time engagement and content consumption. Interactions with Amazon Bedrock are handled by a Lambda function, which implements the application logic underlying an API made available using API Gateway.
The goal was to refine customer service scripts, provide coaching opportunities for agents, and improve call handling processes. Frontend and API The CQ application offers a robust search interface specially crafted for call quality agents, equipping them with powerful auditing capabilities for call analysis.
Customers can use the SageMaker Studio UI or APIs to specify the SageMaker Model Registry model to be shared and grant access to specific AWS accounts or to everyone in the organization. We will start by using the SageMaker Studio UI and then by using APIs.
Many AWS media and entertainment customers license IMDb data through AWS Data Exchange to improve content discovery and increase customer engagement and retention. In this post, we illustrate how to handle OOC by utilizing the power of the IMDb dataset (the premier source of global entertainment metadata) and knowledge graphs.
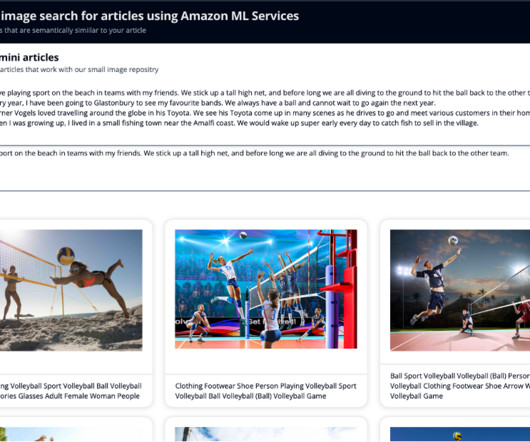
Amazon Rekognition makes it easy to add image analysis capability to your applications without any machine learning (ML) expertise and comes with various APIs to fulfil use cases such as object detection, content moderation, face detection and analysis, and text and celebrity recognition, which we use in this example.
The function then searches the OpenSearch Service image index for images matching the celebrity name and the k-nearest neighbors for the vector using cosine similarity using Exact k-NN with scoring script. Go to the CloudFormation console, choose the stack that you deployed through the deploy script mentioned previously, and delete the stack.
The advanced AI model understands complex instructions with multiple objects and returns studio-quality images suitable for advertising , ecommerce, and entertainment. An asynchronous API and Amazon OpenSearch Service connector make it easy to integrate the model into your neural search applications. exclusive) to 10.0
The Retrieve and RetrieveAndGenerate APIs allow your applications to directly query the index using a unified and standard syntax without having to learn separate APIs for each different vector database, reducing the need to write custom index queries against your vector store.
Gartner predicts that “by 2026, more than 80% of enterprises will have used generative AI APIs or models, or deployed generative AI-enabled applications in production environments, up from less than 5% in 2023.” FOX Corporation (FOX) produces and distributes news, sports, and entertainment content. “We
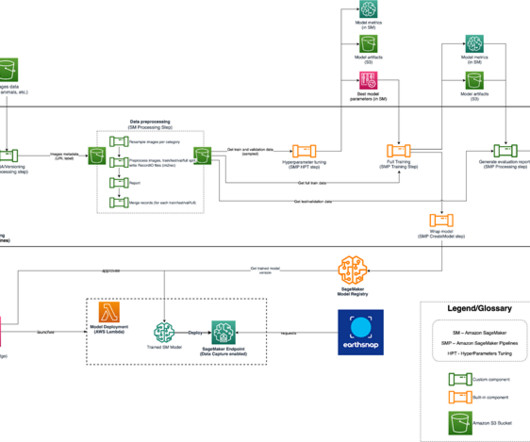
Games24x7 is one of India’s most valuable multi-game platforms and entertains over 100 million gamers across various skill games. The code to invoke the pipeline script is available in the Studio notebooks, and we can change the hyperparameters and input/output when invoking the pipeline.
In this post, we provide an overview of how to deploy and run inference with the Stable Diffusion upscaler model in two ways: via JumpStart’s user interface (UI) in Amazon SageMaker Studio , and programmatically through JumpStart APIs available in the SageMaker Python SDK.
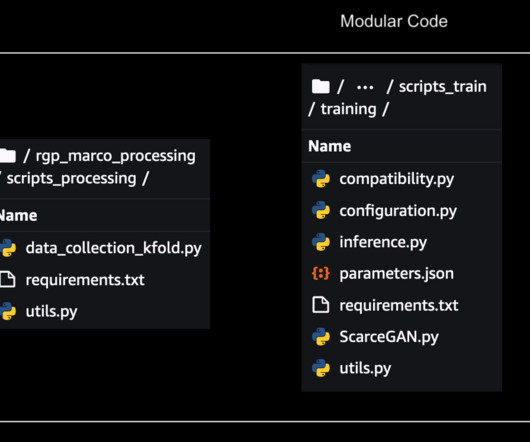
The ML components for data ingestion, preprocessing, and model training were available as disjointed Python scripts and notebooks, which required a lot of manual heavy lifting on the part of engineers. The initial solution also required the support of a technical third party, to release new models swiftly and efficiently.
A new optional parameter TableFormat can be set either interactively using Amazon SageMaker Studio or through code using the API or the SDK. The following code snippet shows you how to create a feature group using the Iceberg format and FeatureGroup.create API of the SageMaker SDK. You can find the sample script in GitHub.
However, traditional dubbing methods are costly ( about $20 per minute with human review effort ) and time consuming, making them a common challenge for companies in the Media & Entertainment (M&E) industry. We use the custom terminology dictionary to compile frequently used terms within video transcription scripts.
In this post, we provide an overview of how to fine-tune the Stable Diffusion model in two ways: programmatically through JumpStart APIs available in the SageMaker Python SDK , and JumpStart’s user interface (UI) in Amazon SageMaker Studio. Fine-tuning large models like Stable Diffusion usually requires you to provide training scripts.
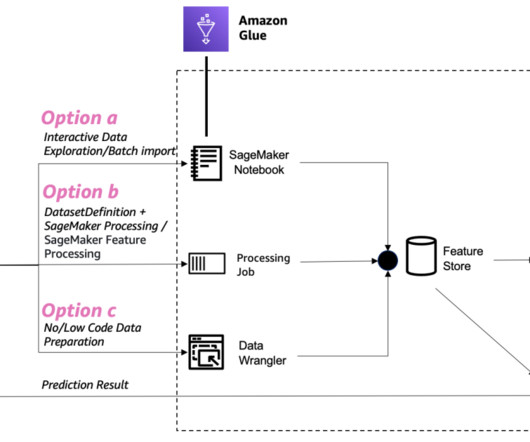
Option B: Use a SageMaker Processing job with Spark In this option, we use a SageMaker Processing job with a Spark script to load the original dataset from Amazon Redshift, perform feature engineering, and ingest the data into SageMaker Feature Store. The environment preparation process may take some time to complete.
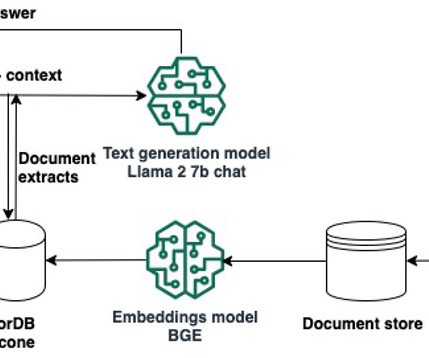
Retrieval Augmented Generation (RAG) allows you to provide a large language model (LLM) with access to data from external knowledge sources such as repositories, databases, and APIs without the need to fine-tune it. To retrieve your Pinecone keys, open the Pinecone console and choose API Keys. embeddings. Python 3.10
This notebook demonstrates how to use the JumpStart API for text classification. To run inference on this model, we first need to download the inference container ( deploy_image_uri ), inference script ( deploy_source_uri ), and pre-trained model ( base_model_uri ). Text classification.
In addition, they use the developer-provided instruction to create an orchestration plan and then carry out the plan by invoking company APIs and accessing knowledge bases using Retrieval Augmented Generation (RAG) to provide an answer to the user’s request. In Part 1, we focus on creating accurate and reliable agents.
When the message is received by the SQS queue, it triggers the AWS Lambda function to make an API call to the Amp catalog service. Lambda enabled the team to create lightweight functions to run API calls and perform data transformations. He works with Media and Entertainment customers and has interests in machine learning technologies.
In this scenario, the generative AI application, designed by the consumer, must interact with the fine-tuner backend via APIs to deliver this functionality to the end-users. Some models may be trained on diverse text datasets like internet data, coding scripts, instructions, or human feedback. 15K available FM reference Step 1.
The chatbot had built-in scripts which enabled it to answer questions about a specific subject. In 1988, Jabberwacky was built by the developer Rollo Carpenter to simulate human conversation for entertainment purposes. Or you can connect to another platform via our API. JivoChat Partners: Dahi.ai Chatme Plantt.
Consider inserting AWS Web Application Firewall (AWS WAF) in front to protect web applications and APIs from malicious bots , SQL injection attacks, cross-site scripting (XSS), and account takeovers with Fraud Control. He recharges through reading, traveling, food and wine, discovering new music, and advising early-stage startups.
Their use cases span various domains, from media entertainment to medical diagnostics and quality assurance in manufacturing. The TGI framework underpins the model inference layer, providing RESTful APIs for robust integration and effortless accessibility.
He has worked with customers across diverse industries, including software, finance, pharmaceutical, healthcare, IoT, and entertainment and media. Ivan Cui is a Data Science Lead with AWS Professional Services, where he helps customers build and deploy solutions using ML and generative AI on AWS.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























Let's personalize your content