This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The custom Google Chat app, configured for HTTP integration, sends an HTTP request to an API Gateway endpoint. Before processing the request, a Lambda authorizer function associated with the API Gateway authenticates the incoming message. Run the script init-script.bash : chmod u+x init-script.bash./init-script.bash
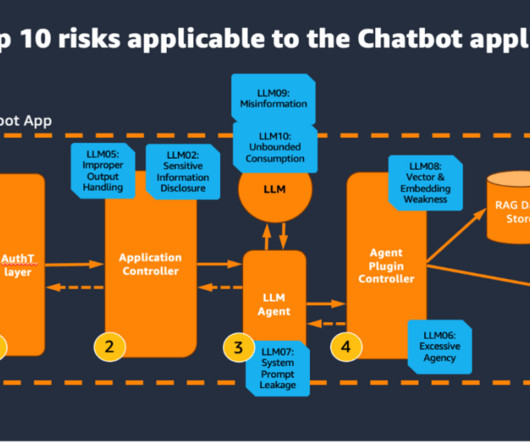
These steps might involve both the use of an LLM and external data sources and APIs. Agent plugin controller This component is responsible for the API integration to external data sources and APIs. The LLM agent is an orchestrator of a set of steps that might be necessary to complete the desired request.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Amazon Bedrock agents use LLMs to break down tasks, interact dynamically with users, run actions through API calls, and augment knowledge using Amazon Bedrock Knowledge Bases. The ReAct approach enables agents to generate reasoning traces and actions while seamlessly integrating with company systems through action groups.
At the forefront of this evolution sits Amazon Bedrock , a fully managed service that makes high-performing foundation models (FMs) from Amazon and other leading AI companies available through an API. System integration – Agents make API calls to integrated company systems to run specific actions.
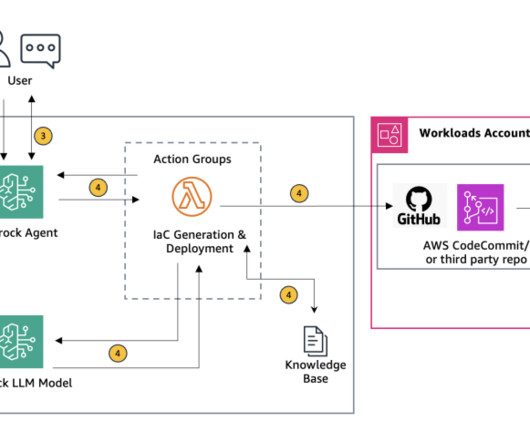
This solution uses Retrieval Augmented Generation (RAG) to ensure the generated scripts adhere to organizational needs and industry standards. In this blog post, we explore how Agents for Amazon Bedrock can be used to generate customized, organization standards-compliant IaC scripts directly from uploaded architecture diagrams.
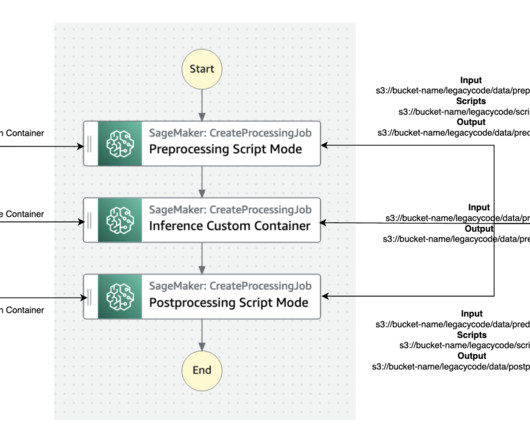
The best practice for migration is to refactor these legacy codes using the Amazon SageMaker API or the SageMaker Python SDK. SageMaker runs the legacy script inside a processing container. Step Functions is a serverless workflow service that can control SageMaker APIs directly through the use of the Amazon States Language.
Enterprise customers have multiple lines of businesses (LOBs) and groups and teams within them. The workflow steps are as follows: The user authenticates with the Amazon Cognito user pool and receives a token to consume the Studio access API. The user calls the API to access Studio and includes the token in the request.
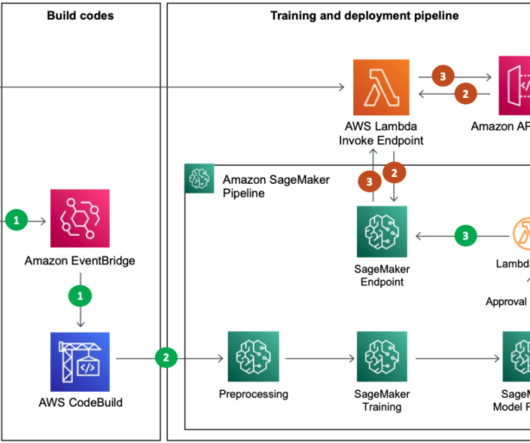
The main AWS services used are SageMaker, Amazon EMR , AWS CodeBuild , Amazon Simple Storage Service (Amazon S3), Amazon EventBridge , AWS Lambda , and Amazon API Gateway. Real-time recommendation inference The inference phase consists of the following steps: The client application makes an inference request to the API gateway.
Refer to Getting started with the API to set up your environment to make Amazon Bedrock requests through the AWS API. Test the code using the native inference API for Anthropics Claude The following code uses the native inference API to send a text message to Anthropics Claude. client = boto3.client("bedrock-runtime",
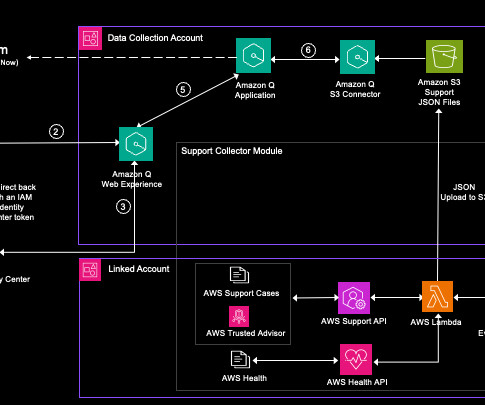
In this post, we’re using the APIs for AWS Support , AWS Trusted Advisor , and AWS Health to programmatically access the support datasets and use the Amazon Q Business native Amazon Simple Storage Service (Amazon S3) connector to index support data and provide a prebuilt chatbot web experience. Synchronize the data source to index the data.
AWS Prototyping successfully delivered a scalable prototype, which solved CBRE’s business problem with a high accuracy rate (over 95%) and supported reuse of embeddings for similar NLQs, and an API gateway for integration into CBRE’s dashboards. The following diagram illustrates the web interface and API management layer.
Amazon Bedrock is a fully managed service that makes FMs from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. Solution overview The solution comprises two main steps: Generate synthetic data using the Amazon Bedrock InvokeModel API.
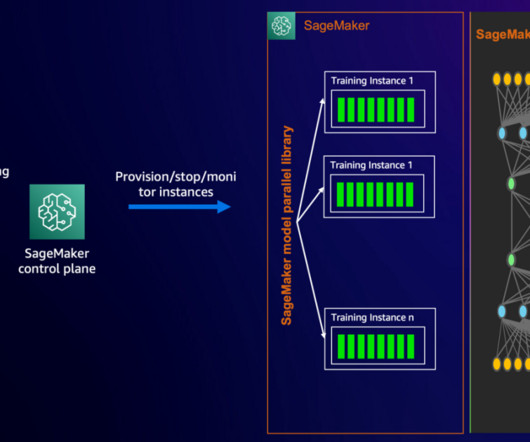
The SMP library uses NVIDIA Megatron to implement expert parallelism and support training MoE models, and runs on top of PyTorch Fully Sharded Data Parallel (FSDP) APIs. For example, if you set the degree to 2, SMP will assign half of the eight experts to each data parallel group. In this example, we use SageMaker training jobs.
A document’s ACL contains information such as the user’s email address and the local groups or federated groups (if Microsoft SharePoint is integrated with an identity provider (IdP) such as Azure Active Directory/Entra ID) that have access to the document.
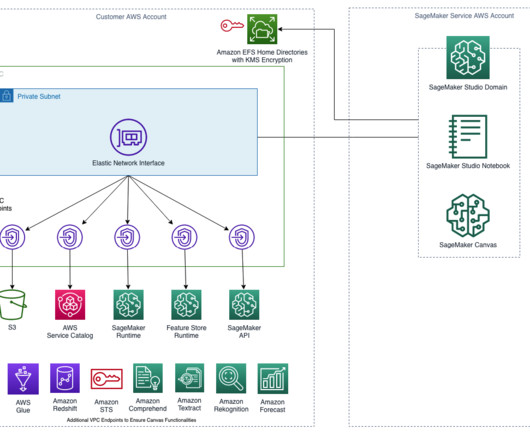
The solution will use Terraform to create: A VPC with subnets, security groups, as well as VPC endpoints to support VPC only mode for the SageMaker Domain. TCP traffic within the security group. This is required to communicate with the SageMaker API. A SageMaker Domain in VPC only mode with a user profile.
Depending on the design of your feature groups and their scale, you can experience training query performance improvements of 10x to 100x by using this new capability. SageMaker Feature Store automatically builds an AWS Glue Data Catalog during feature group creation. Creating feature groups using Iceberg table format.
We recommend running similar scripts only on your own data sources after consulting with the team who manages them, or be sure to follow the terms of service for the sources that youre trying to fetch data from. Grouped as Workplace, HR, and Regulatory, each policy contains a rough two-page summary of crucial organizational items of interest.
Amazon Rekognition makes it easy to add image analysis capability to your applications without any machine learning (ML) expertise and comes with various APIs to fulfil use cases such as object detection, content moderation, face detection and analysis, and text and celebrity recognition, which we use in this example.
Each stage in the ML workflow is broken into discrete steps, with its own script that takes input and output parameters. Ingesting features into the feature store contains the following steps: Define a feature group and create the feature group in the feature store. See the following code: @ray.remote(num_cpus=0.5)
In such cases, data scientists have to provide these parameters to their ML model training and deployment code manually, by noting down subnets, security groups, and KMS keys. Additionally, each API call can have its own configurations. See Supported APIs and parameters for a complete list of supported API calls and parameters.
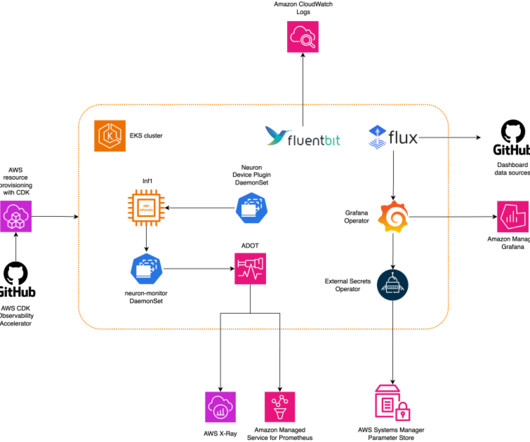
Model weights are available via scripts in the GitHub repository , and the MSAs are hosted by the Registry of Open Data on AWS (RODA). We use aws-do-eks , an open-source project that provides a large collection of easy-to-use and configurable scripts and tools to enable you to provision EKS clusters and run your inference.
When a version of the model in the Amazon SageMaker Model Registry is approved, the endpoint is exposed as an API with Amazon API Gateway using a custom Salesforce JSON Web Token (JWT) authorizer. frameworks to restrict client access to your APIs. For API Name , leave as default (it’s automatically populated).
In this post, we address these limitations by implementing the access control outside of the MLflow server and offloading authentication and authorization tasks to Amazon API Gateway , where we implement fine-grained access control mechanisms at the resource level using Identity and Access Management (IAM). Adds an IAM authorizer.
The Slack application sends the event to Amazon API Gateway , which is used in the event subscription. API Gateway forwards the event to an AWS Lambda function. Create a new group and add the app BedrockSlackIntegration. The following diagram illustrates the solution architecture. Choose Save Changes.
This solution deploys an Amazon EKS cluster with a node group that includes Inf1 instances. The AMI type of the node group is AL2_x86_64_GPU , which uses the Amazon EKS optimized accelerated Amazon Linux AMI. Solution overview The following diagram illustrates the solution architecture. or later NPM version 10.0.0
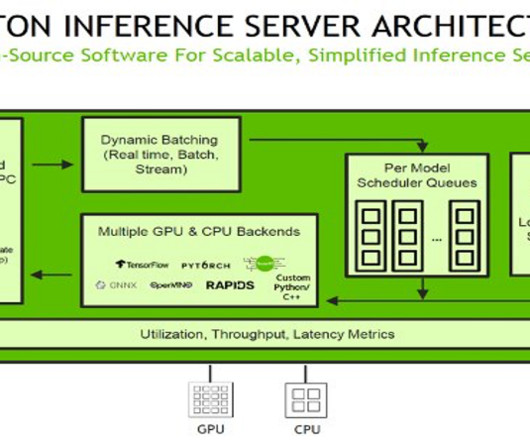
Triton with PyTorch backend The PyTorch backend is designed to run TorchScript models using the PyTorch C++ API. Alternatively, you can use ensemble models or business logic scripting. For instructions on how to secure your account with an IAM administrator user, see Creating your first IAM admin user and user group.
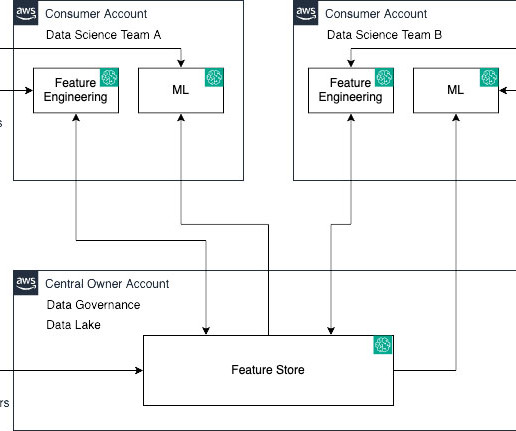
SageMaker Feature Store now makes it effortless to share, discover, and access feature groups across AWS accounts. With this launch, account owners can grant access to select feature groups by other accounts using AWS Resource Access Manager (AWS RAM). For a deep dive, refer to Cross account feature group discoverability and access.
Continuous integration and continuous delivery (CI/CD) pipeline – Using the customer’s GitHub repository enabled code versioning and automated scripts to launch pipeline deployment whenever new versions of the code are committed. Wipro has used the input filter and join functionality of SageMaker batch transformation API.
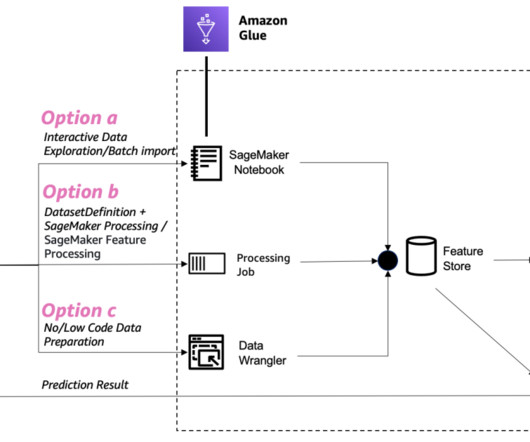
Option B: Use a SageMaker Processing job with Spark In this option, we use a SageMaker Processing job with a Spark script to load the original dataset from Amazon Redshift, perform feature engineering, and ingest the data into SageMaker Feature Store. You decide which feature groups to use for your models.
Applications and services can call the deployed endpoint directly or through a deployed serverless Amazon API Gateway architecture. To learn more about real-time endpoint architectural best practices, refer to Creating a machine learning-powered REST API with Amazon API Gateway mapping templates and Amazon SageMaker.
Amazon API Gateway with AWS Lambda integration that converts the input text to the target language using the Amazon Translate SDK. The following steps set up API Gateway, Lambda, and Amazon Translate resources using the AWS CDK. Take note of the API key and the API endpoint created during the deployment. Prerequisites.
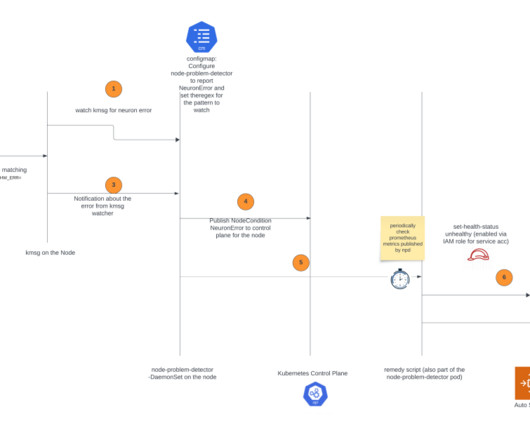
This solution is applicable if you’re using managed nodes or self-managed node groups (which use Amazon EC2 Auto Scaling groups ) on Amazon EKS. First, it will mark the affected instance in the relevant Auto Scaling group as unhealthy, which will invoke the Auto Scaling group to stop the instance and launch a replacement.
Our latest product innovation, Transaction Risk API , was officially launched a couple of weeks ago at Merchant Risk Council (MRC) 2019. Introducing our Transaction Risk API. The Transaction Risk API was built by data scientists for data scientists and designed for easy integration into models. The new era or “Fraud 3.0”
The ML components for data ingestion, preprocessing, and model training were available as disjointed Python scripts and notebooks, which required a lot of manual heavy lifting on the part of engineers. The initial solution also required the support of a technical third party, to release new models swiftly and efficiently.
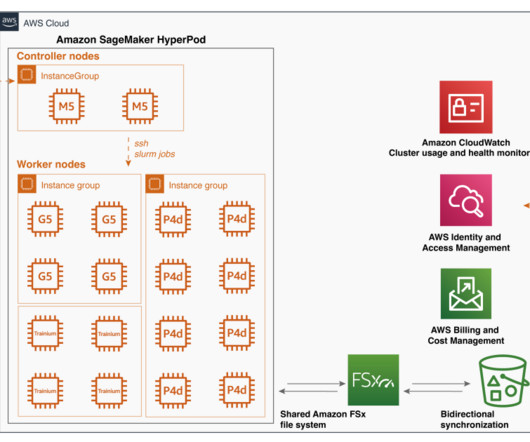
This represents a group of one or more instances of a specific instance type, designed to carry a logical role (like data processing or neural network optimization. You can have two or more groups, and specify a custom name for each instance group, the instance type, and the number of instances for each instance group.
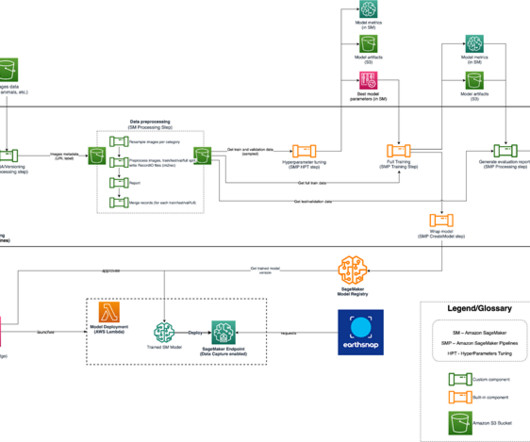
For this we use AWS Step Functions , a serverless workflow service that provides us with API integrations to quickly orchestrate and visualize the steps in our workflow. Finally, the labels are stored in a feature group in SageMaker Feature Store. Use the scripts created in step one as part of the processing and training steps.
This solution uses an Amazon Cognito user pool as an OAuth-compatible identity provider (IdP), which is required in order to exchange a token with AWS IAM Identity Center and later on interact with the Amazon Q Business APIs. Amazon Q uses the chat_sync API to carry out the conversation. You can also find the script on the GitHub repo.
Users can also interact with data with ODBC, JDBC, or the Amazon Redshift Data API. If you’d like to use the traditional SageMaker Studio experience with Amazon Redshift, refer to Using the Amazon Redshift Data API to interact from an Amazon SageMaker Jupyter notebook. The CloudFormation script created a database called sagemaker.
This text-to-video API generates high-quality, realistic videos quickly from text and images. Customizable environment – SageMaker HyperPod offers the flexibility to customize your cluster environment using lifecycle scripts. Video generation has become the latest frontier in AI research, following the success of text-to-image models.
SageMaker makes it easy to deploy models into production directly through API calls to the service. It’s a low-level API available for Java, C++, Go, JavaScript, Node.js, PHP, Ruby, and Python. It’s a low-level API available for Java, C++, Go, JavaScript, Node.js, PHP, Ruby, and Python.
Note that the model container also includes any custom inference code or scripts that you have passed for inference. Make sure to check what container you’re using and if there are any framework-specific optimizations you can add within the script or as environment variables to inject in the container.
The data scientist then needs to review and manually approve the latest version of the model in the Amazon SageMaker Studio UI or via an API call using the AWS Command Line Interface (AWS CLI) or AWS SDK for Python (Boto3) before the new version of model can be utilized for inference.
The intuition behind this design is that partitioning training states across the entire data-parallel group may not be required to train a model with tens of billions of parameters. To get started, follow Modify a PyTorch Training Script to adapt SMPs’ APIs in your training script. return loss. Prepare the dataset.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content