This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In today’s rapidly evolving healthcare landscape, doctors are faced with vast amounts of clinical data from various sources, such as caregiver notes, electronic health records, and imaging reports. In a healthcare setting, this would mean giving the model some data including phrases and terminology pertaining specifically to patient care.
Customers are now pre-training and fine-tuning LLMs ranging from 1 billion to over 175 billion parameters to optimize model performance for applications across industries, from healthcare to finance and marketing. For more information on how to enable SMP with your existing PyTorch FSDP training scripts, refer to Get started with SMP.
AWS HealthOmics and sequence stores AWS HealthOmics is a purpose-built service that helps healthcare and life science organizations and their software partners store, query, and analyze genomic, transcriptomic, and other omics data and then generate insights from that data to improve health and drive deeper biological understanding.
AWS customers in healthcare, financial services, the public sector, and other industries store billions of documents as images or PDFs in Amazon Simple Storage Service (Amazon S3). The first allows you to run a Python script from any server or instance including a Jupyter notebook; this is the quickest way to get started.
The Retrieve and RetrieveAndGenerate APIs allow your applications to directly query the index using a unified and standard syntax without having to learn separate APIs for each different vector database, reducing the need to write custom index queries against your vector store.
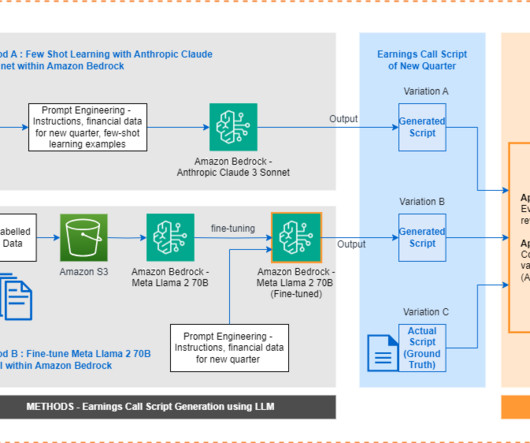
Traditionally, earnings call scripts have followed similar templates, making it a repeatable task to generate them from scratch each time. On the other hand, generative artificial intelligence (AI) models can learn these templates and produce coherent scripts when fed with quarterly financial data.
Amazon API Gateway hosts a REST API with various endpoints to handle user requests that are authenticated using Amazon Cognito. Finally, the response is sent back to the user via a HTTPs request through the Amazon API Gateway REST API integration response. The web application front-end is hosted on AWS Amplify.
In order to run inference through SageMaker API, make sure to pass the Predictor class. pre_trained_model = Model( image_uri=deploy_image_uri, model_data=pre_trained_model_uri, role=aws_role, predictor_cls=Predictor, name=pre_trained_name, env=large_model_env, ) # Deploy the pre-trained model.
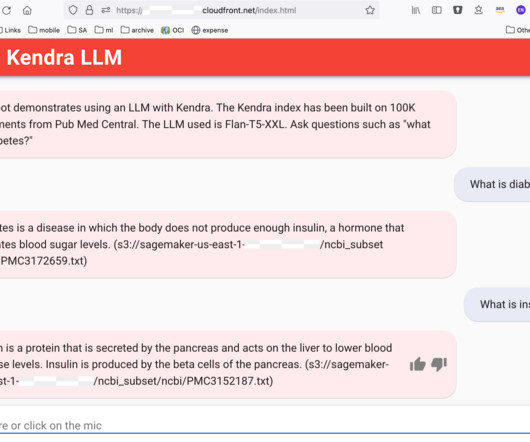
Dataset collection We followed the methodology outlined in the PMC-Llama paper [6] to assemble our dataset, which includes PubMed papers sourced from the Semantic Scholar API and various medical texts cited within the paper, culminating in a comprehensive collection of 88 billion tokens. Create and launch ParallelCluster in the VPC.
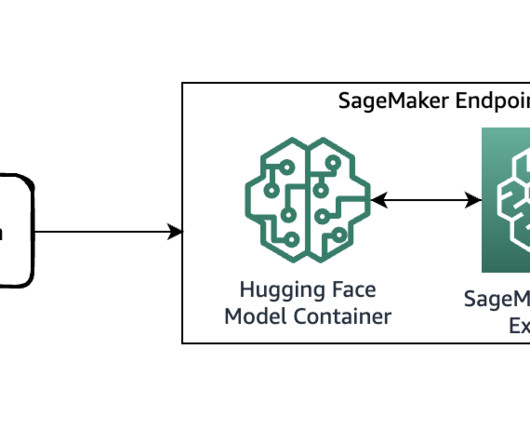
Leidos is a FORTUNE 500 science and technology solutions leader working to address some of the world’s toughest challenges in the defense, intelligence, homeland security, civil, and healthcare markets. Applications and services can call the deployed endpoint directly or through a deployed serverless Amazon API Gateway architecture.
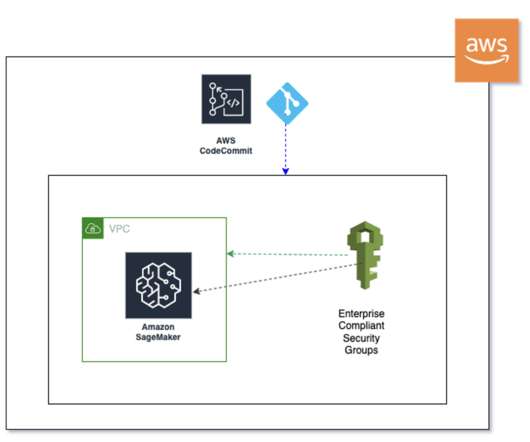
Enterprise customers in tightly controlled industries such as healthcare and finance set up security guardrails to ensure their data is encrypted and traffic doesn’t traverse the internet. Additionally, each API call can have its own configurations. Then it copies the file into the default location for Studio notebooks.
In this post, we present a comprehensive guide on deploying and running inference using the Stable Diffusion inpainting model in two methods: through JumpStart’s user interface (UI) in Amazon SageMaker Studio , and programmatically through JumpStart APIs available in the SageMaker Python SDK.
A new optional parameter TableFormat can be set either interactively using Amazon SageMaker Studio or through code using the API or the SDK. The following code snippet shows you how to create a feature group using the Iceberg format and FeatureGroup.create API of the SageMaker SDK. You can find the sample script in GitHub.
The ML components for data ingestion, preprocessing, and model training were available as disjointed Python scripts and notebooks, which required a lot of manual heavy lifting on the part of engineers. The initial solution also required the support of a technical third party, to release new models swiftly and efficiently.
Autopilot training jobs start their own dedicated SageMaker backend processes, and dedicated SageMaker API calls are required to start new training jobs, monitor training job statuses, and invoke trained Autopilot models. We use a Lambda step because the API call to Autopilot is lightweight. script creates an Autopilot job.
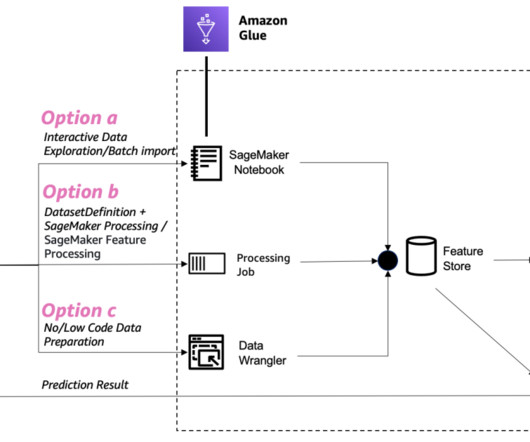
Option B: Use a SageMaker Processing job with Spark In this option, we use a SageMaker Processing job with a Spark script to load the original dataset from Amazon Redshift, perform feature engineering, and ingest the data into SageMaker Feature Store. The environment preparation process may take some time to complete.
Organizations across industries such as retail, banking, finance, healthcare, manufacturing, and lending often have to deal with vast amounts of unstructured text documents coming from various sources, such as news, blogs, product reviews, customer support channels, and social media. Healthcare and life sciences. Fraud detection.
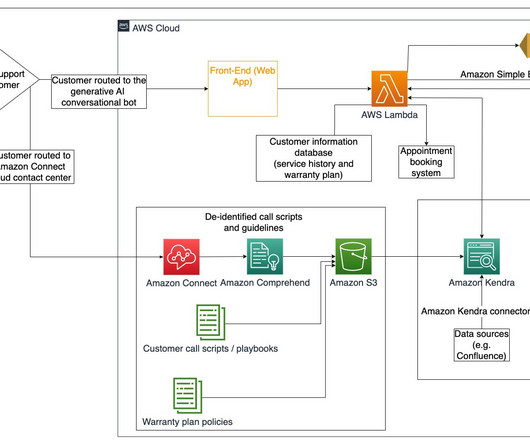
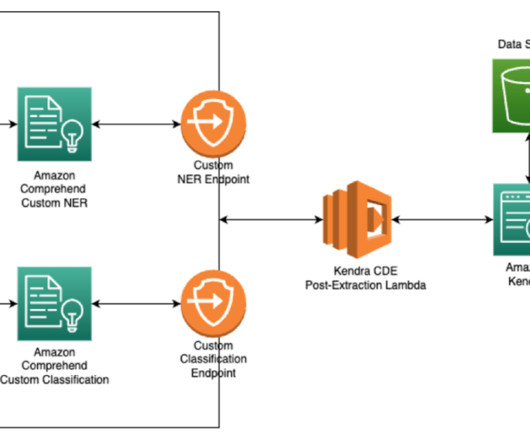
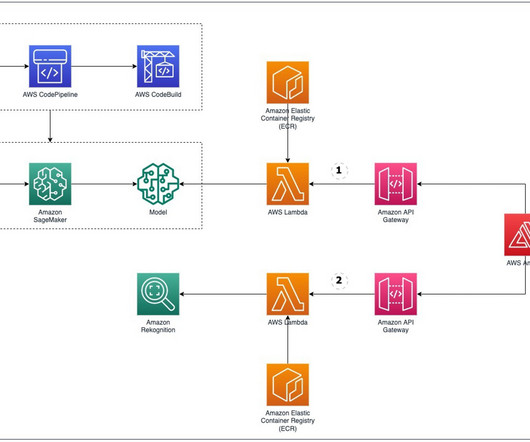
The solution discussed in this post can easily be applied to other businesses/use-cases as well, such as healthcare, manufacturing, and research. Amazon Comprehend custom classification API is used to organize your documents into categories (classes) that you define. The following diagram outlines the proposed solution architecture.
With the increasing use of artificial intelligence (AI) and machine learning (ML) for a vast majority of industries (ranging from healthcare to insurance, from manufacturing to marketing), the primary focus shifts to efficiency when building and training models at scale. The steps are as follows: Open AWS Cloud9 on the console.
Question and answering (Q&A) using documents is a commonly used application in various use cases like customer support chatbots, legal research assistants, and healthcare advisors. years now and has worked with customers across healthcare, sports, manufacturing and software across multiple geographic regions.
We walk through an end-to-end example, from loading the Faster R-CNN object detection model weights, to saving them to an Amazon Simple Storage Service (Amazon S3) bucket, and to writing an entrypoint file and understanding the key parameters in the PyTorchModel API. Step 4: Building ML model inference scripts. Step 1: Setup.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon via a single API. This is because such tasks require organization-specific data and workflows that typically need custom programming.
Example components of the standardized tooling include a data ingestion API, security scanning tools, the CI/CD pipeline built and maintained by another team within athenahealth, and a common serving platform built and maintained by the MLOps team. Tyler Kalbach is a Principal Member of Technical Staff at athenahealth.
Another example might be a healthcare provider who uses PLM inference endpoints for clinical document classification, named entity recognition from medical reports, medical chatbots, and patient risk stratification. Then the payload is passed to the SageMaker endpoint invoke API via the BotoClient to simulate real user requests.
In addition, they use the developer-provided instruction to create an orchestration plan and then carry out the plan by invoking company APIs and accessing knowledge bases using Retrieval Augmented Generation (RAG) to provide an answer to the user’s request. In Part 1, we focus on creating accurate and reliable agents.
Finally, we show how you can integrate this car pose detection solution into your existing web application using services like Amazon API Gateway and AWS Amplify. For each option, we host an AWS Lambda function behind an API Gateway that is exposed to our mock application. iterdir(): if p_file.suffix == ".pth":
In the current scenario, you need to dedicate resources to accomplish such tasks using human review and complex scripts. Amazon Bedrock is a fully managed service that makes FMs from leading AI startups and Amazon available through an API, so you can find the model that best suits your requirements.
With Amazon Bedrock , you will be able to choose Amazon Titan , Amazon’s own LLM, or partner LLMs such as those from AI21 Labs and Anthropic with APIs securely without the need for your data to leave the AWS ecosystem. For the best results, a GenAI app needs to engineer the prompt based on the user request and the specific LLM being used.
However, organizations operating in regulated industries like banking, insurance, and healthcare operate in environments that have strict data privacy and networking controls in place. To achieve this, we set up a configuration file, develop the training script, and run the training code. and model.py gamma: float = 0.7,
Time series forecasting is useful in multiple fields, including retail, finance, logistics, and healthcare. JumpStart features aren’t available in SageMaker notebook instances, and you can’t access them through SageMaker APIs or the AWS Command Line Interface (AWS CLI). Launch the solution.
This is especially effective in regulated markets like healthcare or financial services, where the end customers know the regulations really well, but lack the IT expertise to ensure that new technologies will properly support them. The sky is the limit here, and that’s what makes the innovation focus so promising.
On top of that, artificial intelligence provides agents with real-time assistance during calls for faster resolutions, automates note-taking, eliminates routine post-call work, and spots compliance and script deviations. This creates a more personalized and consistent customer service experience.
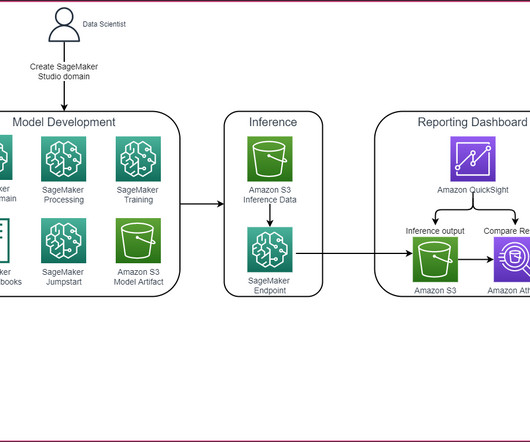
Throughout this blog post, we will be talking about AutoML to indicate SageMaker Autopilot APIs, as well as Amazon SageMaker Canvas AutoML capabilities. The following diagram depicts the basic AutoMLV2 APIs, all of which are relevant to this post. The diagram shows the workflow for building and deploying models using the AutoMLV2 API.
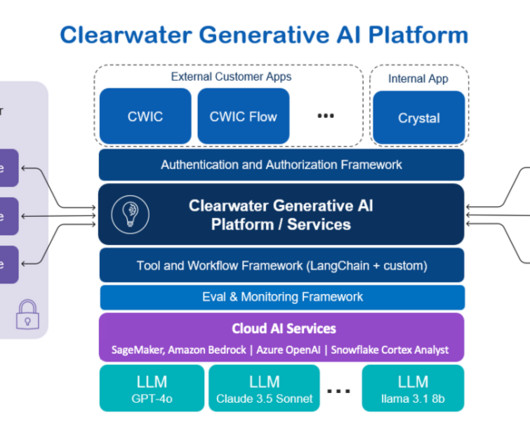
Crystal shares CWICs core functionalities but benefits from broader data sources and API access. Previously, it required a data scientist to write over 100 lines of code within an Amazon SageMaker Notebook to identify and retrieve the proper image, set the right training script, and import the right hyperparameters.
For instructions on assigning permissions to the role, refer to Amazon SageMaker API Permissions: Actions, Permissions, and Resources Reference. The Step Functions state machine, S3 bucket, Amazon API Gateway resources, and Lambda function codes are stored in the GitHub repo. The following figure illustrates our Step Function workflow.
And when you think about the range of features the latter offers at $49 per user per month — all 3 dialers, bulk SMS campaigns and workflows, live call monitoring , advanced analytics and reporting, API and webhooks, live call monitoring, and so much more, it is simply astounding. How are JustCall’s Sales Dialer and Mojo Dialer different?
API Strategies: Use API integration to connect disparate systems, ensuring smooth data flow. Example: A healthcare provider reduced average handle time (AHT) by 20% using real-time insights, ensuring patients received timely and accurate information. A lack of integration limits real-time insights.
The chatbot had built-in scripts which enabled it to answer questions about a specific subject. Healthcare Clinics and hospitals are using chatbots for many things. Or you can connect to another platform via our API. Website Navigation Chatbots are also used as a guide to help users know how to navigate through a website.
Customers can use the SageMaker Studio UI or APIs to specify the SageMaker Model Registry model to be shared and grant access to specific AWS accounts or to everyone in the organization. We will start by using the SageMaker Studio UI and then by using APIs.
In this post, we provide an overview of how to fine-tune the Stable Diffusion model in two ways: programmatically through JumpStart APIs available in the SageMaker Python SDK , and JumpStart’s user interface (UI) in Amazon SageMaker Studio. Fine-tuning large models like Stable Diffusion usually requires you to provide training scripts.
The intent is to offer an accelerated path to adoption of predictive techniques within CDSSs for many healthcare organizations. Technical background A large asset for any acute healthcare organization is its clinical notes. You also use a custom inference script to do the predictions within the container.
In this post, we provide an overview of how to deploy and run inference with the Stable Diffusion upscaler model in two ways: via JumpStart’s user interface (UI) in Amazon SageMaker Studio , and programmatically through JumpStart APIs available in the SageMaker Python SDK.
Economic impact – UHIs can result in billions of dollars in additional energy costs, infrastructure damage, and healthcare expenditures. Gramener’s GeoBox solution empowers users to effortlessly tap into and analyze public geospatial data through its powerful API, enabling seamless integration into existing workflows.
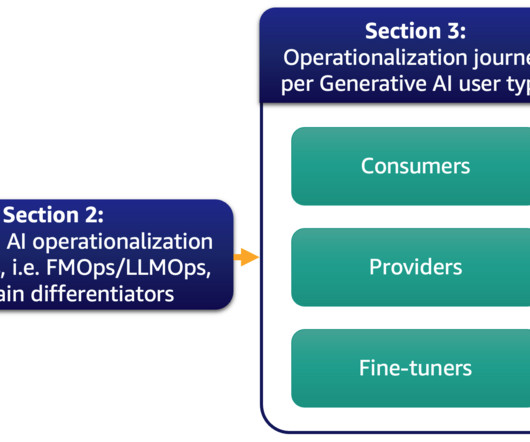
In this scenario, the generative AI application, designed by the consumer, must interact with the fine-tuner backend via APIs to deliver this functionality to the end-users. Some models may be trained on diverse text datasets like internet data, coding scripts, instructions, or human feedback. 15K available FM reference Step 1.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content