This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Bedrock announces the preview launch of Session Management APIs, a new capability that enables developers to simplify state and context management for generative AI applications built with popular open source frameworks such as LangGraph and LlamaIndex. Building generative AI applications requires more than model API calls.
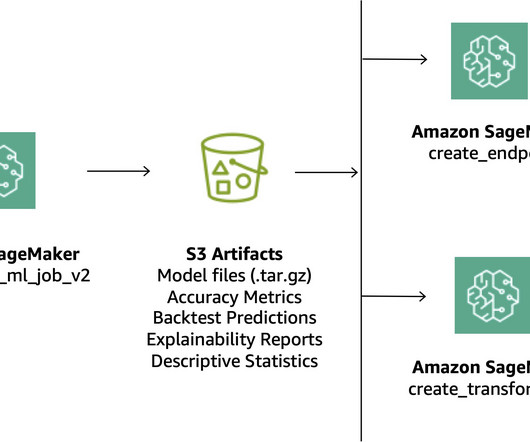
Customers can use the SageMaker Studio UI or APIs to specify the SageMaker Model Registry model to be shared and grant access to specific AWS accounts or to everyone in the organization. With this launch, customers can now seamlessly share and access ML models registered in SageMaker Model Registry between different AWS accounts.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. API Gateway is serverless and hence automatically scales with traffic. API Gateway also provides a WebSocket API. Incoming requests to the gateway go through this point.
In this post, we introduce the core dimensions of responsible AI and explore considerations and strategies on how to address these dimensions for Amazon Bedrock applications. For automatic model evaluation jobs, you can either use built-in datasets across three predefined metrics (accuracy, robustness, toxicity) or bring your own datasets.
In this post, we show how to use FMEval and Amazon SageMaker to programmatically evaluate LLMs. Evaluation algorithm Computes evaluation metrics to model outputs. Different algorithms have different metrics to be specified. This allows you to keep track of your ML experiments.
Current RAG pipelines frequently employ similarity-based metrics such as ROUGE , BLEU , and BERTScore to assess the quality of the generated responses, which is essential for refining and enhancing the models capabilities. More sophisticated metrics are needed to evaluate factual alignment and accuracy.
They have structured data such as sales transactions and revenue metrics stored in databases, alongside unstructured data such as customer reviews and marketing reports collected from various channels. This includes setting up Amazon API Gateway , AWS Lambda functions, and Amazon Athena to enable querying the structured sales data.
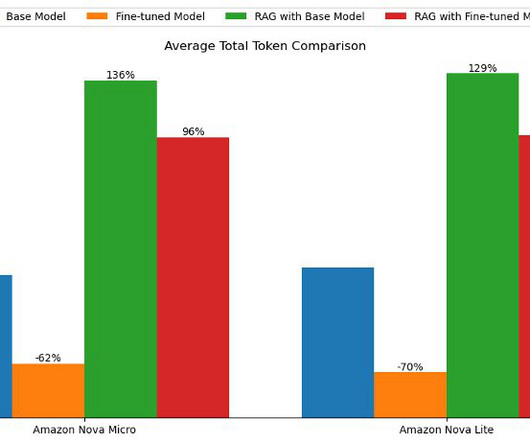
In this post, we demonstrate how to effectively perform model customization and RAG with Amazon Nova models as a baseline. Fine-tune an Amazon Nova model using the Amazon Bedrock API In this section, we provide detailed walkthroughs on fine-tuning and hosting customized Amazon Nova models using Amazon Bedrock.
Furthermore, these notes are usually personal and not stored in a central location, which is a lost opportunity for businesses to learn what does and doesn’t work, as well as how to improve their sales, purchasing, and communication processes. Many commercial generative AI solutions available are expensive and require user-based licenses.
In this post, we explore the new scale to zero feature for SageMaker inference endpoints, demonstrating how to implement and use this capability to optimize costs and manage resources more effectively. Now that we understand when to use the scale to zero feature, let’s dive into how to optimize its performance and implement it effectively.
This approach allows organizations to assess their AI models effectiveness using pre-defined metrics, making sure that the technology aligns with their specific needs and objectives. The introduction of an LLM-as-a-judge framework represents a significant step forward in simplifying and streamlining the model evaluation process.
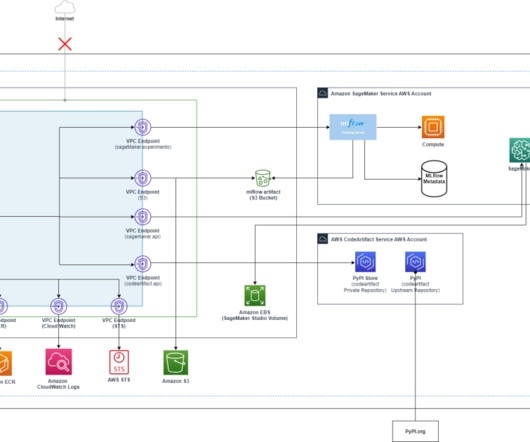
However, keeping track of numerous experiments, their parameters, metrics, and results can be difficult, especially when working on complex projects simultaneously. Note that MLflow tracking starts from the mlflow.start_run() API. The mlflow.autolog() API can automatically log information such as metrics, parameters, and artifacts.
adds new APIs to customize GraphStorm pipelines: you now only need 12 lines of code to implement a custom node classification training loop. For more details about how to run graph multi-task learning with GraphStorm, refer to Multi-task Learning in GraphStorm in our documentation. introduces refactored graph ML pipeline APIs.
Observability refers to the ability to understand the internal state and behavior of a system by analyzing its outputs, logs, and metrics. Evaluation, on the other hand, involves assessing the quality and relevance of the generated outputs, enabling continual improvement.
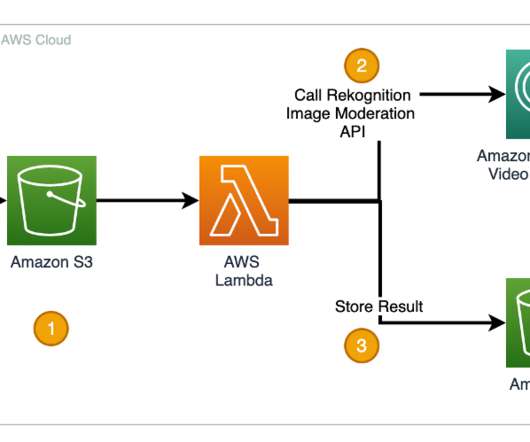
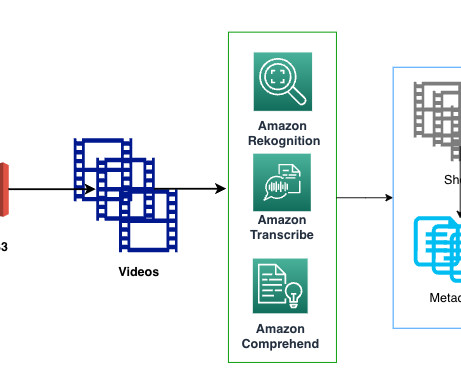
Amazon Rekognition has two sets of APIs that help you moderate images or videos to keep digital communities safe and engaged. Some customers have asked if they could use this approach to moderate videos by sampling image frames and sending them to the Amazon Rekognition image moderation API.
Finally, we explore how to set up rolling updates in different scenarios. Automated safety guards Integrated Amazon CloudWatch alarms monitor metrics on an inference component. AlarmName This CloudWatch alarm is configured to monitor metrics on an InferenceComponent.
The Amazon Bedrock single API access, regardless of the models you choose, gives you the flexibility to use different FMs and upgrade to the latest model versions with minimal code changes. Amazon Titan FMs provide customers with a breadth of high-performing image, multimodal, and text model choices, through a fully managed API.
The solution uses the FMs tool use capabilities, accessed through the Amazon Bedrock Converse API. This enables the FMs to not just process text, but to actively engage with various external tools and APIs to perform complex document analysis tasks. For more details on how tool use works, refer to The complete tool use workflow.
In this post, we describe the enhancements to the forecasting capabilities of SageMaker Canvas and guide you on using its user interface (UI) and AutoML APIs for time-series forecasting. While the SageMaker Canvas UI offers a code-free visual interface, the APIs empower developers to interact with these features programmatically.
During these live events, F1 IT engineers must triage critical issues across its services, such as network degradation to one of its APIs. This impacts downstream services that consume data from the API, including products such as F1 TV, which offer live and on-demand coverage of every race as well as real-time telemetry.
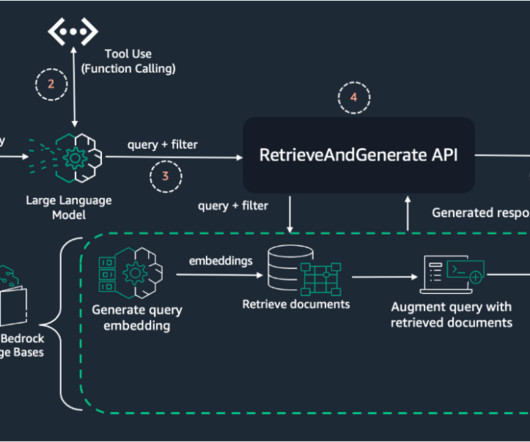
Amazon Bedrock agents use LLMs to break down tasks, interact dynamically with users, run actions through API calls, and augment knowledge using Amazon Bedrock Knowledge Bases. In this post, we demonstrate how to use Amazon Bedrock Agents with a web search API to integrate dynamic web content in your generative AI application.
Organizations building and deploying AI applications, particularly those using large language models (LLMs) with Retrieval Augmented Generation (RAG) systems, face a significant challenge: how to evaluate AI outputs effectively throughout the application lifecycle. Human evaluation, although thorough, is time-consuming and expensive at scale.
Amazon Lookout for Metrics is a fully managed service that uses machine learning (ML) to detect anomalies in virtually any time-series business or operational metrics—such as revenue performance, purchase transactions, and customer acquisition and retention rates—with no ML experience required.
In February 2022, Amazon Web Services added support for NVIDIA GPU metrics in Amazon CloudWatch , making it possible to push metrics from the Amazon CloudWatch Agent to Amazon CloudWatch and monitor your code for optimal GPU utilization. Then we explore two architectures. already installed. eks-create.sh 19 private:192.168.128.0/19
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
As businesses increasingly use large language models (LLMs) for these critical tasks and processes, they face a fundamental challenge: how to maintain the quick, responsive performance users expect while delivering the high-quality outputs these sophisticated models promise. These metrics are shown in the following diagram.
For instance, Pixtral Large is highly effective at spotting irregularities or insightful trends within training loss curves or performance metrics, enhancing the accuracy of data-driven decision-making. By choosing View API , you can also access the model using code examples in the AWS Command Line Interface (AWS CLI) and AWS SDKs.
We dive deep into this process on how to use XML tags to structure the prompt and guide Amazon Bedrock in generating a balanced label dataset with high accuracy. Where discrete outcomes with labeled data exist, standard ML methods such as precision, recall, or other classic ML metrics can be used. client = boto3.client("bedrock-runtime",
In this talk, you’ll understand how to recognize the latest signals in changing data patterns, and adapt data strategies that flex to changes in consumer behavior and innovations in technology like AI. In this session, learn best practices for effectively adopting generative AI in your organization.
In this post, we walk through how to discover, deploy, and use the Pixtral 12B model for a variety of real-world vision use cases. Performance metrics and benchmarks Pixtral 12B is trained to understand both natural images and documents, achieving 52.5% To begin using Pixtral 12B, choose Deploy.
This post shows how to configure an Amazon Q Business custom connector and derive insights by creating a generative AI-powered conversation experience on AWS using Amazon Q Business while using access control lists (ACLs) to restrict access to documents based on user permissions. secrets_manager_client = boto3.client('secretsmanager')
In this first post, we focus on the basics of RAG architecture and how to optimize text-only RAG. The second post outlines how to work with multiple data formats such as structured data (tables, databases) and images. In part 2 of this post, we will discuss how to extend this capability to images and structured data.
In this post, we discuss the key elements needed to evaluate the performance aspect of a content moderation service in terms of various accuracy metrics, and a provide an example using Amazon Rekognition Content Moderation API’s. Understanding such distribution can help you define your actual metric goals. What to evaluate.
In this post, we walk through how to discover, deploy, and use Mistral-Small-24B-Instruct-2501. At the time of writing this post, you can use the InvokeModel API to invoke the model. It doesnt support Converse APIs or other Amazon Bedrock tooling. In this section, we go over how to discover the models in SageMaker Studio.
We then retrieve answers using standard RAG and a two-stage RAG, which involves a reranking API. Retrieve answers using the knowledge base retrieve API Evaluate the response using the RAGAS Retrieve answers again by running a two-stage RAG, using the knowledge base retrieve API and then applying reranking on the context.
In this post, we demonstrate how to use enhanced video search capabilities by enabling semantic retrieval of videos based on text queries. Amazon Transcribe The transcription for the entire video is generated using the StartTranscriptionJob API. The metadata generated for each video by the APIs is processed and stored with timestamps.
This post shows you how to use an integrated solution with Amazon Lookout for Metrics to break these barriers by quickly and easily detecting anomalies in the key performance indicators (KPIs) of your interest. Lookout for Metrics automatically detects and diagnoses anomalies (outliers from the norm) in business and operational data.
They enable applications requiring very low latency or local data processing using familiar APIs and tool sets. This guide demonstrates how to deploy an open source FM from Hugging Face on Amazon Elastic Compute Cloud (Amazon EC2) instances across three locations: a commercial AWS Region and two AWS Local Zones.
Have you ever stumbled upon a breathtaking travel photo and instantly wondered where it was and how to get there? Each one of these millions of travelers need to plan where they’ll stay, what they’ll see, and how they’ll get from place to place. It will then return the place name with the highest similarity score.
Additionally, the complexity increases due to the presence of synonyms for columns and internal metrics available. I am creating a new metric and need the sales data. Firstly, LLMs dont have access to enterprise databases, and the models need to be customized to understand the specific database of an enterprise.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Workforce Management 2025 Guide to the Omnichannel Contact Center: How to Drive Success with the Right Software, Strategy, and Solutions Share Calling, email, texting, instant messaging, social mediathe communication channels available to us today can seem almost endless. What Are the Benefits of Having an Omnichannel Contact Center?
A seamless search journey not only enhances the overall user experience, but also directly impacts key business metrics such as conversion rates, average order value, and customer loyalty. Send the text, images, and metadata to Amazon Bedrock using its API to generate embeddings using the Amazon Titan Multimodal Embeddings G1 model.
In this post, we show how to use Amazon Comprehend Custom to train and host an ML model to classify if the input email is an phishing attempt or not. For details on how to build a classification pipeline with Amazon Comprehend, see Build a classification pipeline with Amazon Comprehend custom classification.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content