This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This solution showcases how to bridge the gap between Google Workspace and AWS services, offering a practical approach to enhancing employee efficiency through conversational AI. The custom Google Chat app, configured for HTTP integration, sends an HTTP request to an API Gateway endpoint.
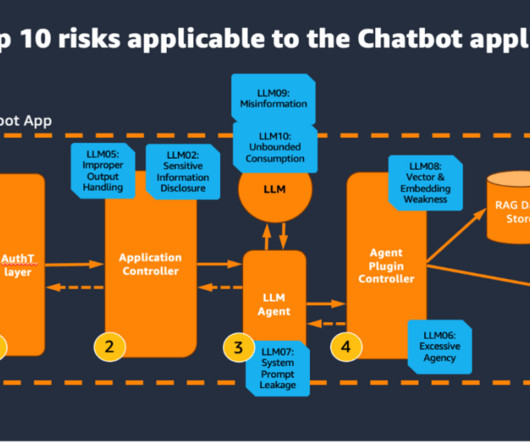
In this post, we show you an example of a generative AI assistant application and demonstrate how to assess its security posture using the OWASP Top 10 for Large Language Model Applications , as well as how to apply mitigations for common threats. These steps might involve both the use of an LLM and external data sources and APIs.
Customers can use the SageMaker Studio UI or APIs to specify the SageMaker Model Registry model to be shared and grant access to specific AWS accounts or to everyone in the organization. We will demonstrate how to set up a central model registry based on the architecture we described in the previous sections.
Additionally, if temporary tables or views are used for the data domain, a SQL script is required that, when executed, creates the desired temporary data structures needs to be defined. Depending on the use case, this can be a static or dynamically generated script. A domain-specific user prompt.
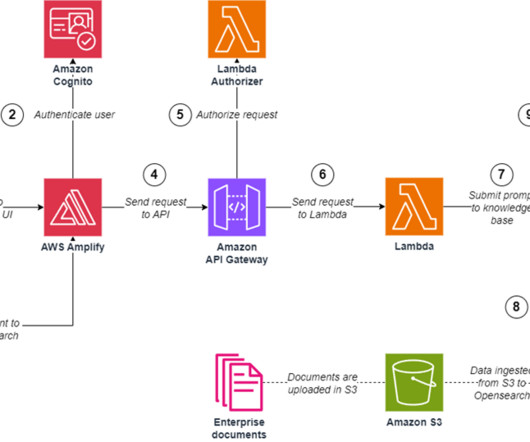
The solution also uses Amazon Cognito user pools and identity pools for managing authentication and authorization of users, Amazon API Gateway REST APIs, AWS Lambda functions, and an Amazon Simple Storage Service (Amazon S3) bucket. The summary is stored inside an S3 bucket, which can be emptied using the extension’s Clean Up feature.
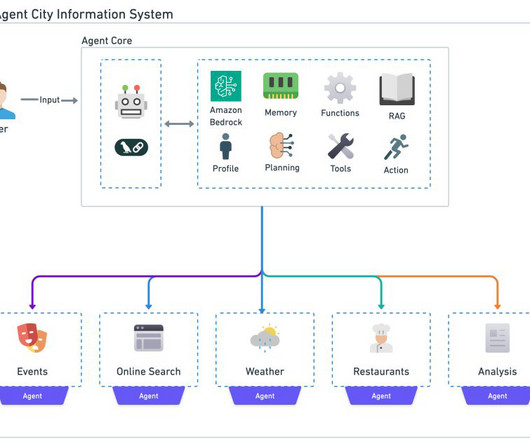
By using the power of LLMs and combining them with specialized tools and APIs, agents can tackle complex, multistep tasks that were previously beyond the reach of traditional AI systems. Whenever local database information is unavailable, it triggers an online search using the Tavily API. Its used by the weather_agent() function.
In this post, we introduce the core dimensions of responsible AI and explore considerations and strategies on how to address these dimensions for Amazon Bedrock applications. For early detection, implement custom testing scripts that run toxicity evaluations on new data and model outputs continuously.
How to Choose the Right Call Center for Your Healthcare Practice As the healthcare industry evolves to meet the demands of modern patients, outsourcing customer communication to a healthcare call center has become a practical and strategic move. Q4: How quickly can a call center be onboarded? A signed BAA is standard.
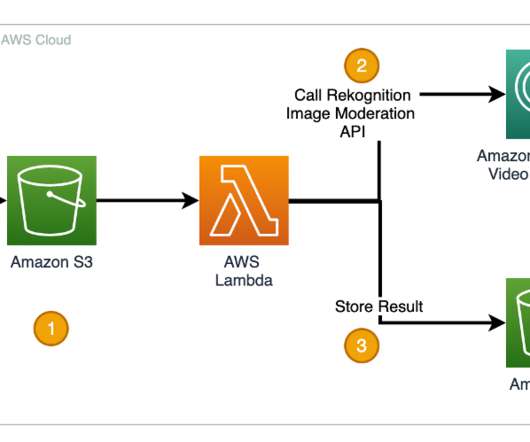
Amazon Rekognition has two sets of APIs that help you moderate images or videos to keep digital communities safe and engaged. Some customers have asked if they could use this approach to moderate videos by sampling image frames and sending them to the Amazon Rekognition image moderation API.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon with a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Amazon Bedrock agents use LLMs to break down tasks, interact dynamically with users, run actions through API calls, and augment knowledge using Amazon Bedrock Knowledge Bases. In this post, we demonstrate how to use Amazon Bedrock Agents with a web search API to integrate dynamic web content in your generative AI application.
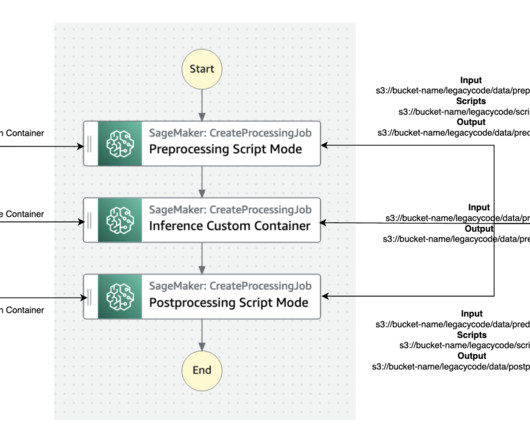
The best practice for migration is to refactor these legacy codes using the Amazon SageMaker API or the SageMaker Python SDK. We demonstrate how two different personas, a data scientist and an MLOps engineer, can collaborate to lift and shift hundreds of legacy models. SageMaker runs the legacy script inside a processing container.
In the post Secure Amazon SageMaker Studio presigned URLs Part 2: Private API with JWT authentication , we demonstrated how to build a private API to generate Amazon SageMaker Studio presigned URLs that are only accessible by an authenticated end-user within the corporate network from a single account.
In this post, we provide an operational overview of the solution, and then describe how to set it up with the following services: Amazon Bedrock and a knowledge base to generate responses from user questions based on enterprise data sources. The request is sent by the web application to the API. An API created with Amazon API Gateway.
This post shows how to configure an Amazon Q Business custom connector and derive insights by creating a generative AI-powered conversation experience on AWS using Amazon Q Business while using access control lists (ACLs) to restrict access to documents based on user permissions. secrets_manager_client = boto3.client('secretsmanager')
Amazon Bedrock is a fully managed service that makes FMs from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. In this post, we explore how to use Amazon Bedrock to generate synthetic training data to fine-tune an LLM.
The first allows you to run a Python script from any server or instance including a Jupyter notebook; this is the quickest way to get started. In the following sections, we first describe the script solution, followed by the AWS CDK construct solution. The following diagram illustrates the sequence of events within the script.
At the forefront of this evolution sits Amazon Bedrock , a fully managed service that makes high-performing foundation models (FMs) from Amazon and other leading AI companies available through an API. System integration – Agents make API calls to integrated company systems to run specific actions.
The SageMaker Python SDK provides open-source APIs and containers to train and deploy models on SageMaker, using several different ML and deep learning frameworks. In this post, we walk you through an example of how to build and deploy a custom Hugging Face text summarizer on SageMaker. return tokenized_dataset. If we use an ml.g4dn.16xlarge
You can also either use the SageMaker Canvas UI, which provides a visual interface for building and deploying models without needing to write any code or have any ML expertise, or use its automated machine learning (AutoML) APIs for programmatic interactions. Python script – Use a Python script to merge the datasets.
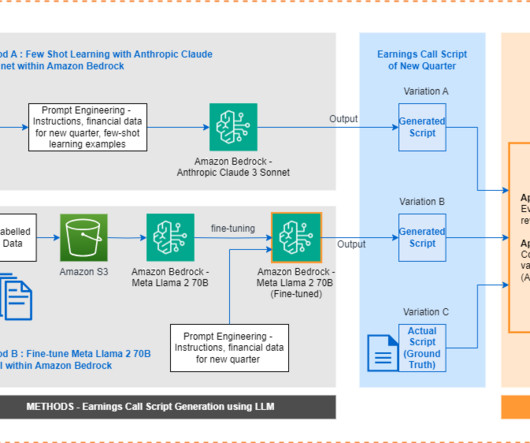
Traditionally, earnings call scripts have followed similar templates, making it a repeatable task to generate them from scratch each time. On the other hand, generative artificial intelligence (AI) models can learn these templates and produce coherent scripts when fed with quarterly financial data.
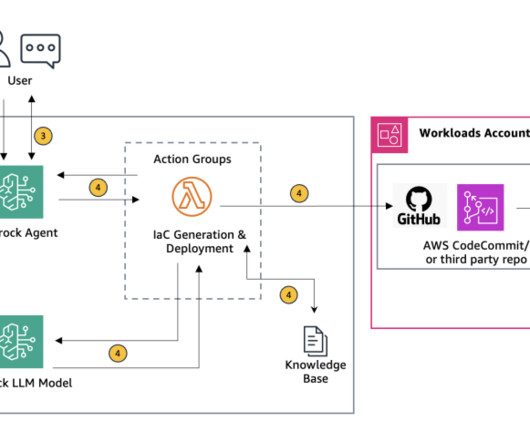
This solution shows how Amazon Bedrock agents can be configured to accept cloud architecture diagrams, automatically analyze them, and generate Terraform or AWS CloudFormation templates. This solution uses Retrieval Augmented Generation (RAG) to ensure the generated scripts adhere to organizational needs and industry standards.
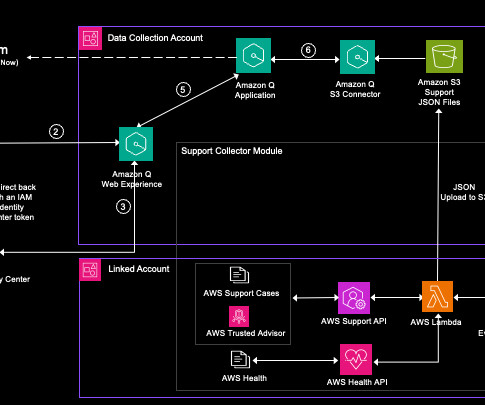
This post shows how to use AWS generative artificial intelligence (AI) services , like Amazon Q Business , with AWS Support cases, AWS Trusted Advisor , and AWS Health data to derive actionable insights based on common patterns, issues, and resolutions while using the AWS recommendations and best practices enabled by support data.
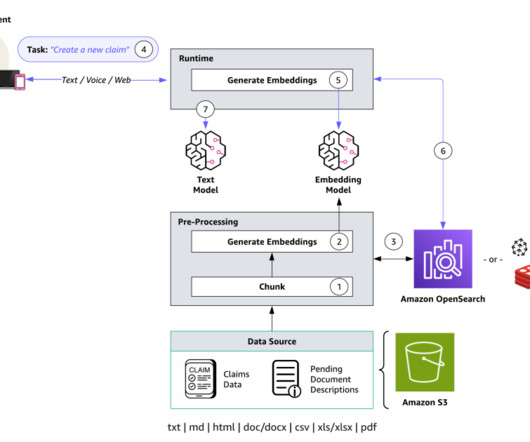
In this first post, we focus on the basics of RAG architecture and how to optimize text-only RAG. The second post outlines how to work with multiple data formats such as structured data (tables, databases) and images. In part 2 of this post, we will discuss how to extend this capability to images and structured data.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API. The scripts for fine-tuning and evaluation are available on the GitHub repository.
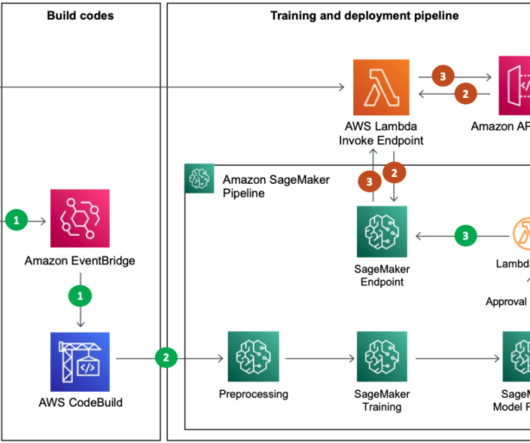
The main AWS services used are SageMaker, Amazon EMR , AWS CodeBuild , Amazon Simple Storage Service (Amazon S3), Amazon EventBridge , AWS Lambda , and Amazon API Gateway. Real-time recommendation inference The inference phase consists of the following steps: The client application makes an inference request to the API gateway.
In particular, we cover the SMP library’s new simplified user experience that builds on open source PyTorch Fully Sharded Data Parallel (FSDP) APIs, expanded tensor parallel functionality that enables training models with hundreds of billions of parameters, and performance optimizations that reduce model training time and cost by up to 20%.
We dive deep into this process on how to use XML tags to structure the prompt and guide Amazon Bedrock in generating a balanced label dataset with high accuracy. In the following sections, we explain how to take an incremental and measured approach to improve Anthropics Claude 3.5 Sonnet prediction accuracy through prompt engineering.
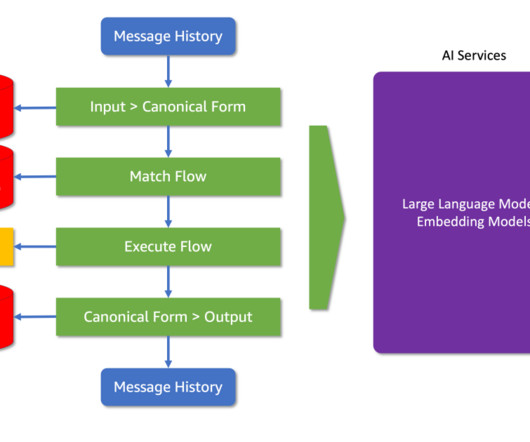
Lets delve into a basic Colang script to see how it works: define user express greeting "hello" "hi" "what's up?" define bot ask how are you "How are you doing?" model API exposed by SageMaker JumpStart properly. define bot express greeting "Hey there!" The Llama 3.1
In this blog post, we show how we optimized torch.compile performance on AWS Graviton3-based EC2 instances, how to use the optimizations to improve inference performance, and the resulting speedups. We benchmarked 45 models using the scripts from the TorchBench repo. Starting with PyTorch 2.3.1, Starting with PyTorch 2.3.1,
In this post, we demonstrate how to use Amazon Rekognition , Amazon SageMaker JumpStart , and Amazon OpenSearch Service to solve this business problem. These models have been packaged to be securely and easily deployable via Amazon SageMaker APIs. MatchConfidence – A match confidence score that can be used to control API behavior.
Lastly the model is tested against a set of known genome sequences using some inference API calls. In the sample Jupyter notebook we show how to download FASTA files from GenBank, convert them into FASTQ files, and then load them into a HealthOmics sequence store. Then we deploy that model as a SageMaker real-time inference endpoint.
The function then searches the OpenSearch Service image index for images matching the celebrity name and the k-nearest neighbors for the vector using cosine similarity using Exact k-NN with scoring script. Go to the CloudFormation console, choose the stack that you deployed through the deploy script mentioned previously, and delete the stack.
Similar to the process of PyTorch integration with C++ code, Neuron CustomOps requires a C++ implementation of an operator via a NeuronCore-ported subset of the Torch C++ API. Finally, the custom library is built by calling the load API. For more information, refer to Custom Operators API Reference Guide [Experimental].
In this post, we demonstrate how to build a RAG workflow using Knowledge Bases for Amazon Bedrock for a drug discovery use case. You can also use the StartIngestionJob API to trigger the sync via the AWS SDK. We use the Knowledge Bases for Amazon Bedrock retrieve_and_generate and retrieve APIs with Amazon Bedrock LangChain integration.
In this post, we explore how to remove barriers to adoption, significantly amplifying the effectiveness of your CX strategies. Furthermore, TechSee’s technology can be integrated anywhere through APIs or SDKs. However, the true potential of investing in CX innovation often remains untapped due to barriers that hinder adoption.
In this post, we explore how to remove barriers to adoption, significantly amplifying the effectiveness of your CX strategies. Furthermore, TechSee’s technology can be integrated anywhere through APIs or SDKs. However, the true potential of investing in CX innovation often remains untapped due to barriers that hinder adoption.
An asynchronous API and Amazon OpenSearch Service connector make it easy to integrate the model into your neural search applications. In this post, we walk through how to use the Titan Image Generator and Titan Multimodal Embeddings models via the AWS Python SDK. For Python scripts, you can use the AWS SDK for Python (Boto3).
However, complex NLQs, such as time series data processing, multi-level aggregation, and pivot or joint table operations, may yield inconsistent Python script accuracy with a zero-shot prompt. The user can use the Amazon Recognition DetectText API to extract text data from these images. setup.sh. (a a challenge-level question).
You can fine-tune and deploy JumpStart models using the UI in Amazon SageMaker Studio or using the SageMaker Python SDK extension for JumpStart APIs. This post focuses on how we can implement MLOps with JumpStart models using JumpStart APIs, Amazon SageMaker Pipelines , and Amazon SageMaker Projects. sm_client = boto3.client("sagemaker")
In a previous post , we showed you how to build and publish a Web Component. Now it’s time to see how to use a top feature of Web Components: Custom components and widgets build on the Web Component standards will work across modern browsers, and they can be used with any JavaScript library or framework that works with HTML.
In this post, we show you how to unlock new levels of efficiency and creativity by bringing the power of generative AI directly into your Slack workspace using Amazon Bedrock. We show how to create a Slack application, configure the necessary permissions, and deploy the required resources using AWS CloudFormation.
In this post, we show you how to get started with Amazon Kendra Intelligent Ranking for self-managed OpenSearch, and we provide a few examples that demonstrate the power and value of this feature. Create and start OpenSearch using the Quickstart script. script: wget [link] chmod +x search_processing_kendra_quickstart.sh.
Inference API – The server exposes an API that allows client applications to send input data and receive predictions from the deployed models. Different request handlers will provide support for the Inference API , Management API , or other APIs available from various plugins.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content