This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
With the increasing use of artificial intelligence (AI) and machine learning (ML) for a vast majority of industries (ranging from healthcare to insurance, from manufacturing to marketing), the primary focus shifts to efficiency when building and training models at scale.
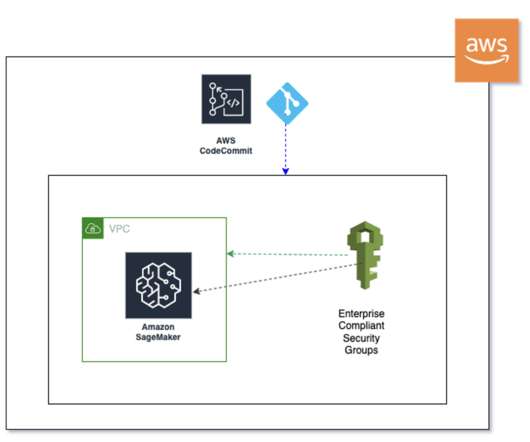
The AWS portfolio of ML services includes a robust set of services that you can use to accelerate the development, training, and deployment of machine learning applications. Collaboration – Data scientists each worked on their own local Jupyter notebooks to create and train ML models.
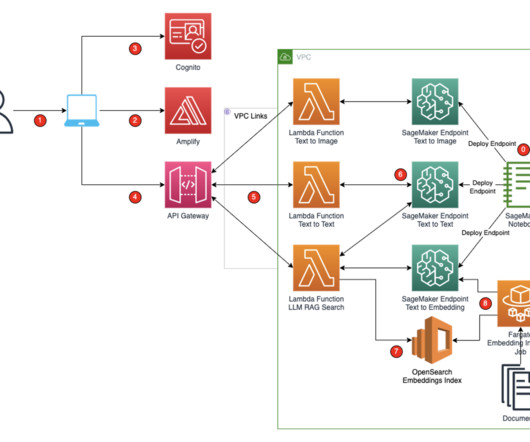
It’s powered by large language models (LLMs) that are pre-trained on vast amounts of data and commonly referred to as foundation models (FMs). These SageMaker endpoints are consumed in the Amplify React application through Amazon API Gateway and AWS Lambda functions.
We also explore best practices for optimizing your batch inference workflows on Amazon Bedrock, helping you maximize the value of your data across different use cases and industries. Solution overview The batch inference feature in Amazon Bedrock provides a scalable solution for processing large volumes of data across various domains.
This post also provides an example end-to-end notebook and GitHub repository that demonstrates SageMaker geospatial capabilities, including ML-based farm field segmentation and pre-trained geospatial models for agriculture. These differences in satellite images and frequencies also lead to differences in API capabilities and features.
Bosch is a multinational corporation with entities operating in multiple sectors, including automotive, industrialsolutions, and consumer goods. We include CNN-QR and DeepAR+, two off-the-shelf models in Amazon Forecast , as well as a custom Transformer model trained using Amazon SageMaker. Modeling approaches. Amazon Forecast.
Because your models are only as good as your training data, expert data scientists and practitioners spend an enormous time understanding the data and generating valuable insights prior to building the models. In our case, our training data (diabetic-readmission.csv) is uploaded. Upload the historical dataset to Amazon S3.
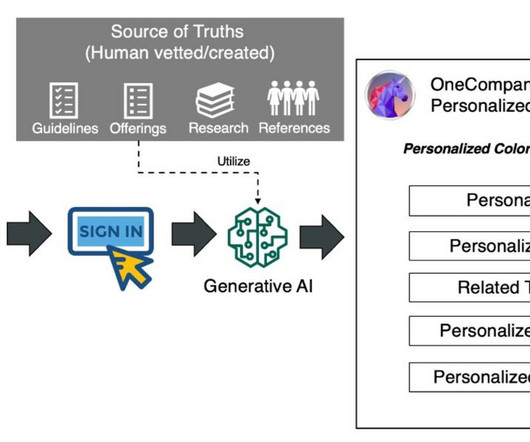
We employed other LLMs available on Amazon Bedrock to synthetically generate fictitious reference materials to avoid potential biases that could arise from Amazon Claude’s pre-training data. Nonetheless, our solution can still be utilized. For this post, we use Anthropic’s Claude models on Amazon Bedrock.
Onboarding Challenges: Getting new reps trained and ramped up to full productivity is time-intensive and expensive. Integration with Existing Systems: APIs facilitate data sharing between CPQ and other core platforms like CRM, ERP, accounting, e-commerce, and more. These intricacies strain resources and cause deals to stall out.
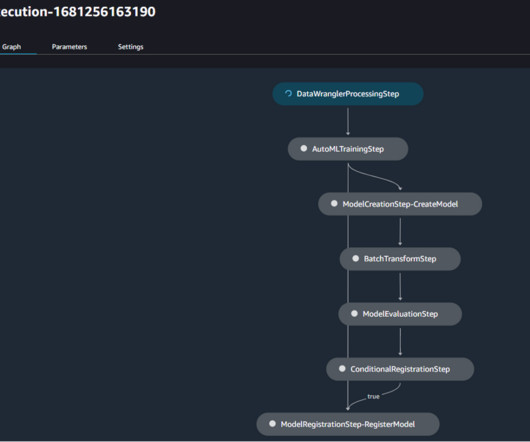
Amazon SageMaker is a fully managed service to prepare data and build, train, and deploy machine learning (ML) models for any use case with fully managed infrastructure, tools, and workflows. The 1P templates generally focus on creating resources for model building and model training.
This feature empowers customers to import and use their customized models alongside existing foundation models (FMs) through a single, unified API. Having a unified developer experience when accessing custom models or base models through Amazon Bedrock’s API. The training data must be formatted in a JSON Lines (.jsonl)
These large language models (LLMs) are trained on a vast amount of data from various domains and languages. It uses Amazon Bedrock through the Boto3 API to use Anthropic’s Claude V3 multi-modal language models, but makes it straightforward to use file formats that are otherwise not supported by Anthropic’s Claude models.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content