This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
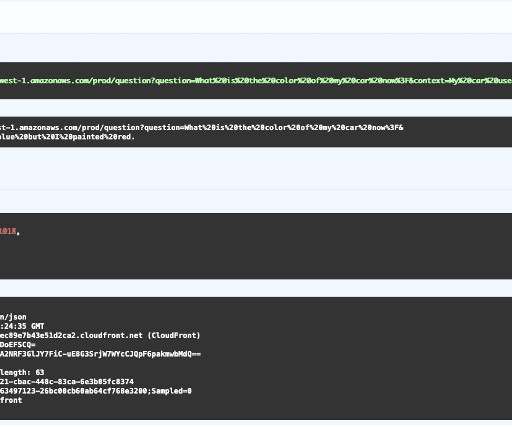
The custom Google Chat app, configured for HTTP integration, sends an HTTP request to an API Gateway endpoint. Before processing the request, a Lambda authorizer function associated with the API Gateway authenticates the incoming message. Run the script init-script.bash : chmod u+x init-script.bash./init-script.bash
Amazon Nova is a new generation of state-of-the-art foundation models (FMs) that deliver frontier intelligence and industry-leading price-performance. How well do these models handle RAG use cases across different industry domains? Amazon Bedrock APIs make it straightforward to use Amazon Titan Text Embeddings V2 for embedding data.
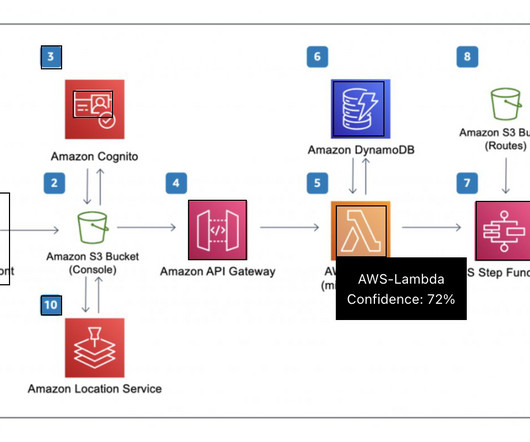
The solution also uses Amazon Cognito user pools and identity pools for managing authentication and authorization of users, Amazon API Gateway REST APIs, AWS Lambda functions, and an Amazon Simple Storage Service (Amazon S3) bucket. To launch the solution in a different Region, change the aws_region parameter accordingly.
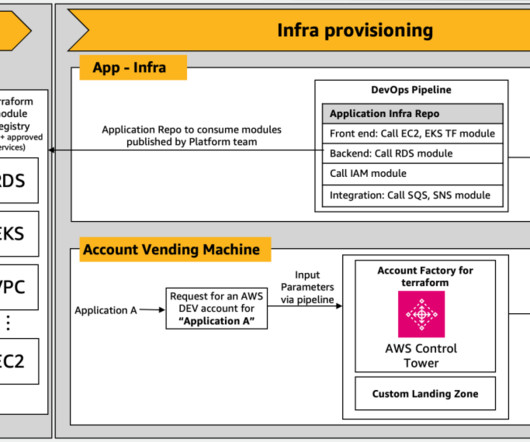
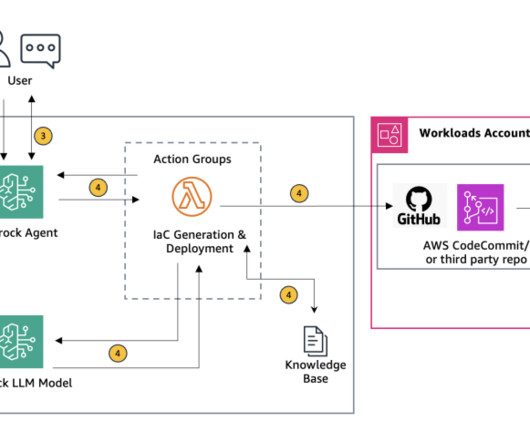
However, despite its benefits, IaC’s learning curve, and the complexity of adhering to your organization’s and industry-specific compliance and security standards, could slow down your cloud adoption journey. In this post, we show you how to generate customized, compliant IaC scripts for AWS Landing Zone using Amazon Bedrock.
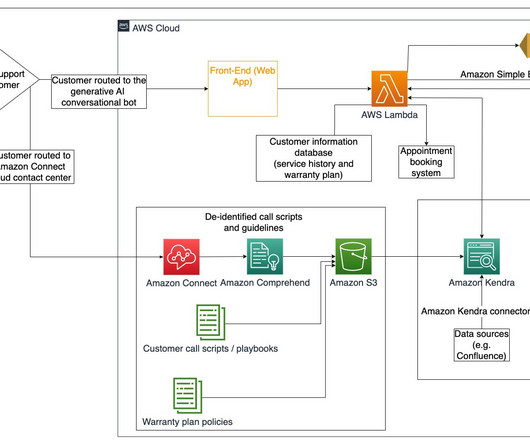
The goal was to refine customer service scripts, provide coaching opportunities for agents, and improve call handling processes. Frontend and API The CQ application offers a robust search interface specially crafted for call quality agents, equipping them with powerful auditing capabilities for call analysis.
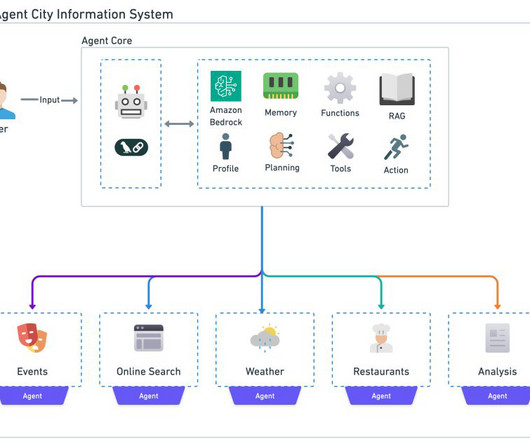
These intelligent, autonomous systems are poised to become the cornerstone of AI adoption across industries, heralding a new era of human-AI collaboration and problem-solving. As these systems evolve, they will transform industries, expand possibilities, and open new doors for artificial intelligence.
Amazon Bedrock agents use LLMs to break down tasks, interact dynamically with users, run actions through API calls, and augment knowledge using Amazon Bedrock Knowledge Bases. In this post, we demonstrate how to use Amazon Bedrock Agents with a web search API to integrate dynamic web content in your generative AI application.
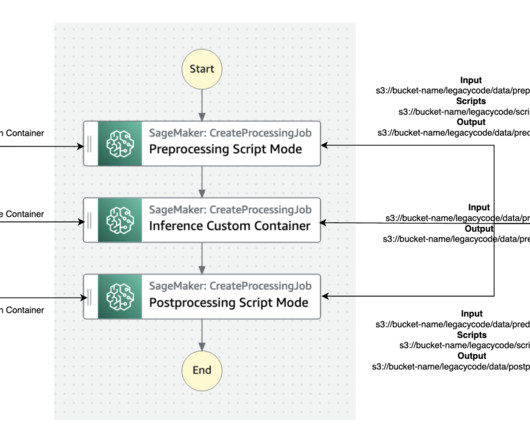
The best practice for migration is to refactor these legacy codes using the Amazon SageMaker API or the SageMaker Python SDK. SageMaker runs the legacy script inside a processing container. Step Functions is a serverless workflow service that can control SageMaker APIs directly through the use of the Amazon States Language.
Customers are now pre-training and fine-tuning LLMs ranging from 1 billion to over 175 billion parameters to optimize model performance for applications across industries, from healthcare to finance and marketing. For more information on how to enable SMP with your existing PyTorch FSDP training scripts, refer to Get started with SMP.
This solution uses Retrieval Augmented Generation (RAG) to ensure the generated scripts adhere to organizational needs and industry standards. In this blog post, we explore how Agents for Amazon Bedrock can be used to generate customized, organization standards-compliant IaC scripts directly from uploaded architecture diagrams.
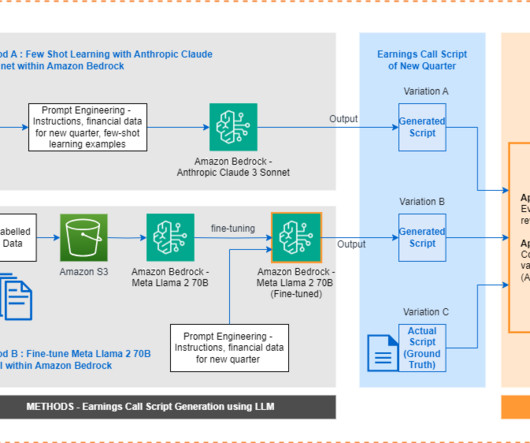
Investors and analysts closely watch key metrics like revenue growth, earnings per share, margins, cash flow, and projections to assess performance against peers and industry trends. Traditionally, earnings call scripts have followed similar templates, making it a repeatable task to generate them from scratch each time.
Amazon Bedrock is a fully managed service that makes FMs from leading AI startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. Solution overview The solution comprises two main steps: Generate synthetic data using the Amazon Bedrock InvokeModel API.
AWS customers in healthcare, financial services, the public sector, and other industries store billions of documents as images or PDFs in Amazon Simple Storage Service (Amazon S3). The first allows you to run a Python script from any server or instance including a Jupyter notebook; this is the quickest way to get started.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API. The scripts for fine-tuning and evaluation are available on the GitHub repository.
Here are some features which we will cover: AWS CloudFormation support Private network policies for Amazon OpenSearch Serverless Multiple S3 buckets as data sources Service Quotas support Hybrid search, metadata filters, custom prompts for the RetreiveAndGenerate API, and maximum number of retrievals.
We’re proud to announce that we’ve “officially” launched our Agent Scripting for call centers. Also, we’d love to get in touch if you write a blog or enjoy writing about customer service, call center technology, or awesome new companies in our industry. And you know what that means? Press release time !
This two-part series shares the insights gained by AWS GenAIIC from direct experience building RAG solutions across a wide range of industries. The retrieve_and_generate API does both the retrieval and a call to an FM (Amazon Titan or Anthropic’s Claude family of models on Amazon Bedrock ), for a fully managed solution.
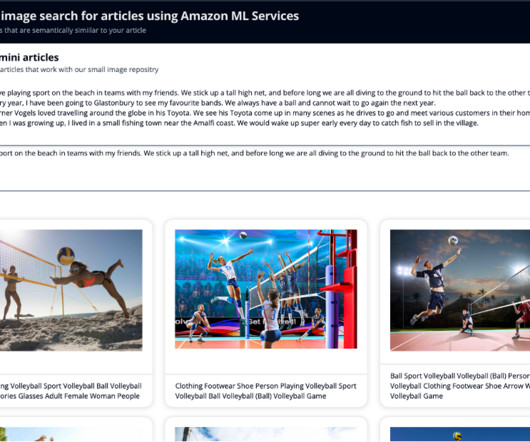
Amazon Rekognition makes it easy to add image analysis capability to your applications without any machine learning (ML) expertise and comes with various APIs to fulfil use cases such as object detection, content moderation, face detection and analysis, and text and celebrity recognition, which we use in this example.
The function then searches the OpenSearch Service image index for images matching the celebrity name and the k-nearest neighbors for the vector using cosine similarity using Exact k-NN with scoring script. Go to the CloudFormation console, choose the stack that you deployed through the deploy script mentioned previously, and delete the stack.
We recommend running similar scripts only on your own data sources after consulting with the team who manages them, or be sure to follow the terms of service for the sources that youre trying to fetch data from. A simple architectural representation of the steps involved is shown in the following figure. secrets_manager_client = boto3.client('secretsmanager')
The Retrieve and RetrieveAndGenerate APIs allow your applications to directly query the index using a unified and standard syntax without having to learn separate APIs for each different vector database, reducing the need to write custom index queries against your vector store.
AWS Prototyping successfully delivered a scalable prototype, which solved CBRE’s business problem with a high accuracy rate (over 95%) and supported reuse of embeddings for similar NLQs, and an API gateway for integration into CBRE’s dashboards. The following diagram illustrates the web interface and API management layer.
By bridging the gap between raw genetic data and actionable knowledge, genomic language models hold immense promise for various industries and research areas, including whole-genome analysis , delivered care , pharmaceuticals , and agriculture. Lastly the model is tested against a set of known genome sequences using some inference API calls.
Continuous integration and continuous delivery (CI/CD) pipeline – Using the customer’s GitHub repository enabled code versioning and automated scripts to launch pipeline deployment whenever new versions of the code are committed. Wipro has used the input filter and join functionality of SageMaker batch transformation API.
This innovative technology makes producing custom images in large volume for any industry more accessible and efficient. An asynchronous API and Amazon OpenSearch Service connector make it easy to integrate the model into your neural search applications. For Python scripts, you can use the AWS SDK for Python (Boto3).
In recent years, large language models (LLMs) have gained attention for their effectiveness, leading various industries to adapt general LLMs to their data for improved results, making efficient training and hardware availability crucial. Now you can launch a training job to submit a model training script as a slurm job.
Gramener’s GeoBox solution empowers users to effortlessly tap into and analyze public geospatial data through its powerful API, enabling seamless integration into existing workflows. With the SearchRasterDataCollection API, SageMaker provides a purpose-built functionality to facilitate the retrieval of satellite imagery.
The code to invoke the pipeline script is available in the Studio notebooks, and we can change the hyperparameters and input/output when invoking the pipeline. This is quite different from our earlier method where we had all the parameters hard coded within the scripts and all the processes were inextricably linked.
You can fine-tune and deploy JumpStart models using the UI in Amazon SageMaker Studio or using the SageMaker Python SDK extension for JumpStart APIs. This post focuses on how we can implement MLOps with JumpStart models using JumpStart APIs, Amazon SageMaker Pipelines , and Amazon SageMaker Projects. sm_client = boto3.client("sagemaker")
We explore two ways of obtaining the same result: via JumpStart’s graphical interface on Amazon SageMaker Studio , and programmatically through JumpStart APIs. If you want to jump straight into the JumpStart API code we go through in this post, you can refer to the following sample Jupyter notebook: Introduction to JumpStart – Text to Image.
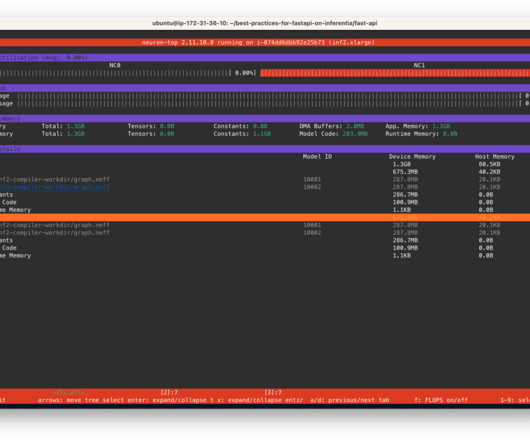
If the model changes on the server side, the client has to know and change its API call to the new endpoint accordingly. Clone the Github repository The GitHub repo provides all the scripts necessary to deploy models using FastAPI on NeuronCores on AWS Inferentia instances. code as the entry point. compiled-model-bs-{batch_size}.pt')
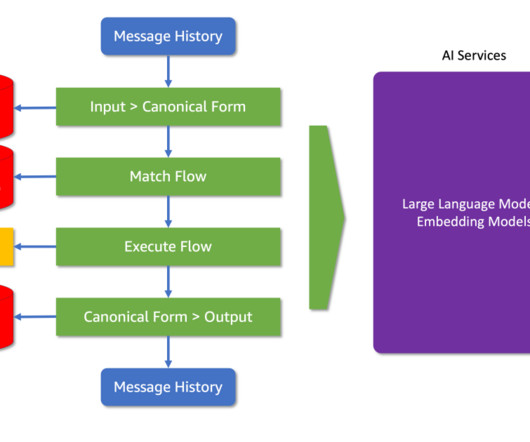
Lets delve into a basic Colang script to see how it works: define user express greeting "hello" "hi" "what's up?" define flow greeting user express greeting bot express greeting bot ask how are you In this script, we see the three fundamental types of blocks in Colang: User Message Blocks (define user ): These define possible user inputs.
Enterprise customers in tightly controlled industries such as healthcare and finance set up security guardrails to ensure their data is encrypted and traffic doesn’t traverse the internet. Additionally, each API call can have its own configurations. Then it copies the file into the default location for Studio notebooks.
Amazon API Gateway with AWS Lambda integration that converts the input text to the target language using the Amazon Translate SDK. The following steps set up API Gateway, Lambda, and Amazon Translate resources using the AWS CDK. Take note of the API key and the API endpoint created during the deployment. Prerequisites.
Amazon API Gateway hosts a REST API with various endpoints to handle user requests that are authenticated using Amazon Cognito. Finally, the response is sent back to the user via a HTTPs request through the Amazon API Gateway REST API integration response. The web application front-end is hosted on AWS Amplify.
FastAPI is a modern, high-performance web framework for building APIs with Python. It stands out when it comes to developing serverless applications with RESTful microservices and use cases requiring ML inference at scale across multiple industries. To build this image locally, we need Docker. We discuss how to create the.tar.gz
This can be used to enhance image quality in various industries such as ecommerce and real estate, as well as for artists and photographers. Running large models like Stable Diffusion requires custom inference scripts. JumpStart simplifies this process by providing ready-to-use scripts that have been robustly tested.
This often means the method of using a third-party LLM API won’t do for security, control, and scale reasons. It provides an approachable, robust Python API for the full infrastructure stack of ML/AI, from data and compute to workflows and observability. The following figure illustrates this workflow.
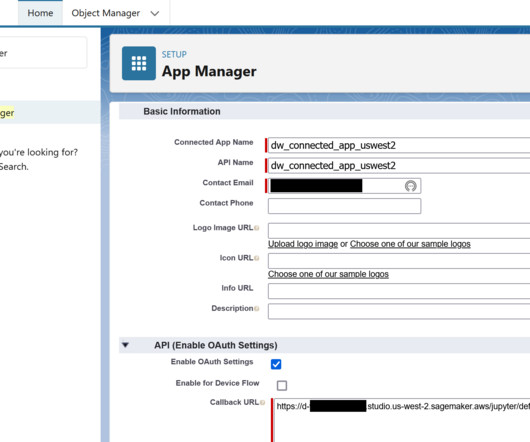
When a version of the model in the Amazon SageMaker Model Registry is approved, the endpoint is exposed as an API with Amazon API Gateway using a custom Salesforce JSON Web Token (JWT) authorizer. frameworks to restrict client access to your APIs. For API Name , leave as default (it’s automatically populated).
Model weights are available via scripts in the GitHub repository , and the MSAs are hosted by the Registry of Open Data on AWS (RODA). We use aws-do-eks , an open-source project that provides a large collection of easy-to-use and configurable scripts and tools to enable you to provision EKS clusters and run your inference.
Identifying keywords such as use cases and industry verticals in these sources also allows the information to be captured and for more relevant search results to be displayed to the user. A Python script is used to aid in the process of uploading the datasets and generating the manifest file.
A new optional parameter TableFormat can be set either interactively using Amazon SageMaker Studio or through code using the API or the SDK. The following code snippet shows you how to create a feature group using the Iceberg format and FeatureGroup.create API of the SageMaker SDK. You can find the sample script in GitHub.
We explore two ways of obtaining the same result: via JumpStart’s graphical interface on Amazon SageMaker Studio , and programmatically through JumpStart APIs. The following sections provide a step-by-step demo to perform semantic segmentation with JumpStart, both via the Studio UI and via JumpStart APIs. Solution overview.
Creates an API Gateway that adds an additional layer of security between the web app user interface and Lambda. Wait until the script provisions all the required resources and finishes running. Copy the API Gateway URL that the AWS CDK script prints out and save it. (We The S3 path to the movie node file.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content