This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Bedrock announces the preview launch of Session Management APIs, a new capability that enables developers to simplify state and context management for generative AI applications built with popular open source frameworks such as LangGraph and LlamaIndex. Building generative AI applications requires more than model API calls.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. API Gateway is serverless and hence automatically scales with traffic. API Gateway also provides a WebSocket API. Incoming requests to the gateway go through this point.
Customers can use the SageMaker Studio UI or APIs to specify the SageMaker Model Registry model to be shared and grant access to specific AWS accounts or to everyone in the organization. We will start by using the SageMaker Studio UI and then by using APIs.
Evaluation algorithm Computes evaluation metrics to model outputs. Different algorithms have different metrics to be specified. It functions as a standalone HTTP server that provides various REST API endpoints for monitoring, recording, and visualizing experiment runs. This allows you to keep track of your ML experiments.
They have structured data such as sales transactions and revenue metrics stored in databases, alongside unstructured data such as customer reviews and marketing reports collected from various channels. This includes setting up Amazon API Gateway , AWS Lambda functions, and Amazon Athena to enable querying the structured sales data.
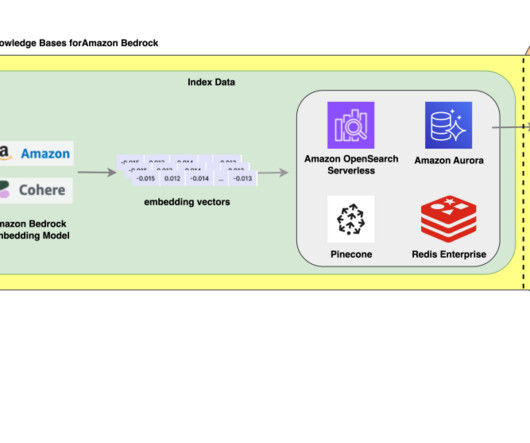
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
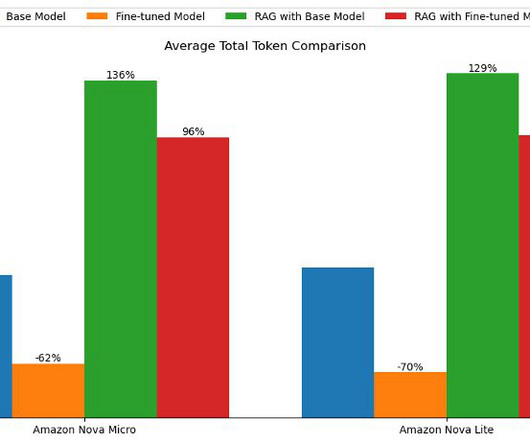
How do Amazon Nova Micro and Amazon Nova Lite perform against GPT-4o mini in these same metrics? Amazon Bedrock APIs make it straightforward to use Amazon Titan Text Embeddings V2 for embedding data. Vector database FloTorch selected Amazon OpenSearch Service as a vector database for its high-performance metrics.
This approach allows organizations to assess their AI models effectiveness using pre-defined metrics, making sure that the technology aligns with their specific needs and objectives. The introduction of an LLM-as-a-judge framework represents a significant step forward in simplifying and streamlining the model evaluation process.
All of this data is centralized and can be used to improve metrics in scenarios such as sales or call centers. For integration between services, we use API Gateway as an event trigger for our Lambda function, and DynamoDB as a highly scalable database to store our customer details.
Use faster auto scaling metrics – Take advantage of more granular auto scaling metrics like ConcurrentRequestsPerCopy to more accurately monitor and react to changes in inference traffic. It’s a dynamic policy that adjusts the number of copies based on a specified metric, such as CPU utilization or request count.
Current RAG pipelines frequently employ similarity-based metrics such as ROUGE , BLEU , and BERTScore to assess the quality of the generated responses, which is essential for refining and enhancing the models capabilities. More sophisticated metrics are needed to evaluate factual alignment and accuracy.
adds new APIs to customize GraphStorm pipelines: you now only need 12 lines of code to implement a custom node classification training loop. Based on customer feedback for the experimental APIs we released in GraphStorm 0.2, introduces refactored graph ML pipeline APIs. Specifically, GraphStorm 0.3 In addition, GraphStorm 0.3
Observability refers to the ability to understand the internal state and behavior of a system by analyzing its outputs, logs, and metrics. Evaluation, on the other hand, involves assessing the quality and relevance of the generated outputs, enabling continual improvement.
However, keeping track of numerous experiments, their parameters, metrics, and results can be difficult, especially when working on complex projects simultaneously. Note that MLflow tracking starts from the mlflow.start_run() API. The mlflow.autolog() API can automatically log information such as metrics, parameters, and artifacts.
Fine-tune an Amazon Nova model using the Amazon Bedrock API In this section, we provide detailed walkthroughs on fine-tuning and hosting customized Amazon Nova models using Amazon Bedrock. We first provided a detailed walkthrough on how to fine-tune, host, and conduct inference with customized Amazon Nova through the Amazon Bedrock API.
Automated safety guards Integrated Amazon CloudWatch alarms monitor metrics on an inference component. AlarmName This CloudWatch alarm is configured to monitor metrics on an InferenceComponent. For more information about the SageMaker AI API, refer to the SageMaker AI API Reference.
Amazon Lookout for Metrics is a fully managed service that uses machine learning (ML) to detect anomalies in virtually any time-series business or operational metrics—such as revenue performance, purchase transactions, and customer acquisition and retention rates—with no ML experience required.
In this post, we describe the enhancements to the forecasting capabilities of SageMaker Canvas and guide you on using its user interface (UI) and AutoML APIs for time-series forecasting. While the SageMaker Canvas UI offers a code-free visual interface, the APIs empower developers to interact with these features programmatically.
To effectively optimize AI applications for responsiveness, we need to understand the key metrics that define latency and how they impact user experience. These metrics differ between streaming and nonstreaming modes and understanding them is crucial for building responsive AI applications.
In February 2022, Amazon Web Services added support for NVIDIA GPU metrics in Amazon CloudWatch , making it possible to push metrics from the Amazon CloudWatch Agent to Amazon CloudWatch and monitor your code for optimal GPU utilization. Then we explore two architectures. already installed. eks-create.sh 19 private:192.168.128.0/19
For instance, Pixtral Large is highly effective at spotting irregularities or insightful trends within training loss curves or performance metrics, enhancing the accuracy of data-driven decision-making. By choosing View API , you can also access the model using code examples in the AWS Command Line Interface (AWS CLI) and AWS SDKs.
Amazon Bedrock agents use LLMs to break down tasks, interact dynamically with users, run actions through API calls, and augment knowledge using Amazon Bedrock Knowledge Bases. In this post, we demonstrate how to use Amazon Bedrock Agents with a web search API to integrate dynamic web content in your generative AI application.
During these live events, F1 IT engineers must triage critical issues across its services, such as network degradation to one of its APIs. This impacts downstream services that consume data from the API, including products such as F1 TV, which offer live and on-demand coverage of every race as well as real-time telemetry.
The solution uses the FMs tool use capabilities, accessed through the Amazon Bedrock Converse API. This enables the FMs to not just process text, but to actively engage with various external tools and APIs to perform complex document analysis tasks. For more details on how tool use works, refer to The complete tool use workflow.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Performance metrics and benchmarks Pixtral 12B is trained to understand both natural images and documents, achieving 52.5% You can find detailed usage instructions, including sample API calls and code snippets for integration. To begin using Pixtral 12B, choose Deploy.
Although automated metrics are fast and cost-effective, they can only evaluate the correctness of an AI response, without capturing other evaluation dimensions or providing explanations of why an answer is problematic. Human evaluation, although thorough, is time-consuming and expensive at scale.
Where discrete outcomes with labeled data exist, standard ML methods such as precision, recall, or other classic ML metrics can be used. These metrics provide high precision but are limited to specific use cases due to limited ground truth data. If the use case doesnt yield discrete outputs, task-specific metrics are more appropriate.
Gain insights into training strategies, productivity metrics, and real-world use cases to empower your developers to harness the full potential of this game-changing technology. Discover how to create and manage evaluation jobs, use automatic and human reviews, and analyze critical metrics like accuracy, robustness, and toxicity.
The Amazon Bedrock single API access, regardless of the models you choose, gives you the flexibility to use different FMs and upgrade to the latest model versions with minimal code changes. Amazon Titan FMs provide customers with a breadth of high-performing image, multimodal, and text model choices, through a fully managed API.
Performance metrics and benchmarks According to Mistral, the instruction-tuned version of the model achieves over 81% accuracy on Massive Multitask Language Understanding (MMLU) with 150 tokens per second latency, making it currently the most efficient model in its category. It doesnt support Converse APIs or other Amazon Bedrock tooling.
The user’s request is sent to AWS API Gateway , which triggers a Lambda function to interact with Amazon Bedrock using Anthropic’s Claude Instant V1 FM to process the user’s request and generate a natural language response of the place location. It will then return the place name with the highest similarity score.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
It’s a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like Anthropic, Cohere, Meta, Mistral AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
We then retrieve answers using standard RAG and a two-stage RAG, which involves a reranking API. Retrieve answers using the knowledge base retrieve API Evaluate the response using the RAGAS Retrieve answers again by running a two-stage RAG, using the knowledge base retrieve API and then applying reranking on the context.
The implementation uses Slacks event subscription API to process incoming messages and Slacks Web API to send responses. The incoming event from Slack is sent to an endpoint in API Gateway, and Slack expects a response in less than 3 seconds, otherwise the request fails.
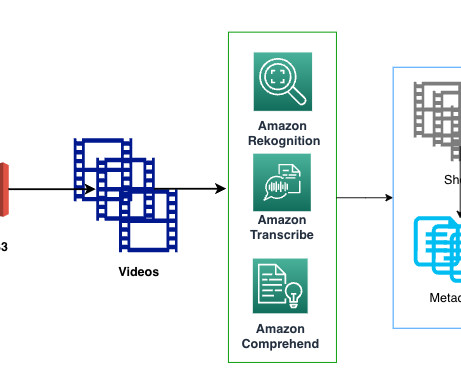
Amazon Transcribe The transcription for the entire video is generated using the StartTranscriptionJob API. The solution runs Amazon Rekognition APIs for label detection , text detection, celebrity detection , and face detection on videos. The metadata generated for each video by the APIs is processed and stored with timestamps.
This requires carefully combining applications and metrics to provide complete awareness, accuracy, and control. The zAdviser uses Amazon Bedrock to provide summarization, analysis, and recommendations for improvement based on the DORA metrics data. It’s also vital to avoid focusing on irrelevant metrics or excessively tracking data.
A seamless search journey not only enhances the overall user experience, but also directly impacts key business metrics such as conversion rates, average order value, and customer loyalty. Send the text, images, and metadata to Amazon Bedrock using its API to generate embeddings using the Amazon Titan Multimodal Embeddings G1 model.
Frontend and API The CQ application offers a robust search interface specially crafted for call quality agents, equipping them with powerful auditing capabilities for call analysis. Additionally, the application offers backend dashboards tailored to MLOps functionalities, ensuring smooth monitoring and optimization of machine learning models.
AWS Prototyping successfully delivered a scalable prototype, which solved CBRE’s business problem with a high accuracy rate (over 95%) and supported reuse of embeddings for similar NLQs, and an API gateway for integration into CBRE’s dashboards. The following diagram illustrates the web interface and API management layer.
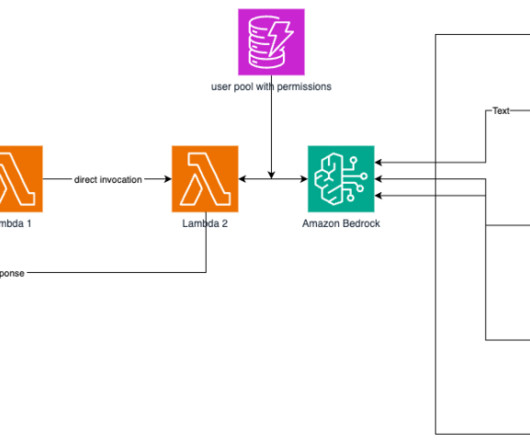
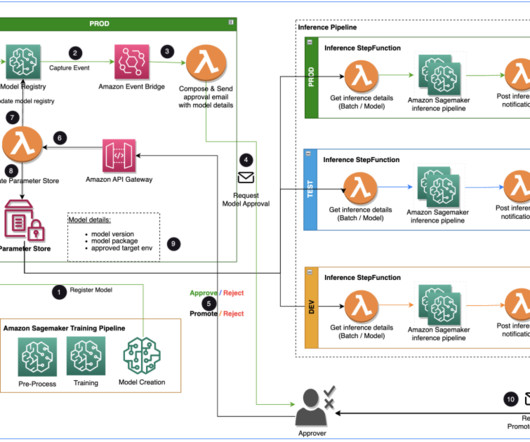
The solution uses AWS Lambda , Amazon API Gateway , Amazon EventBridge , and SageMaker to automate the workflow with human approval intervention in the middle. The approver approves the model by following the link in the email to an API Gateway endpoint. API Gateway invokes a Lambda function to initiate model updates.
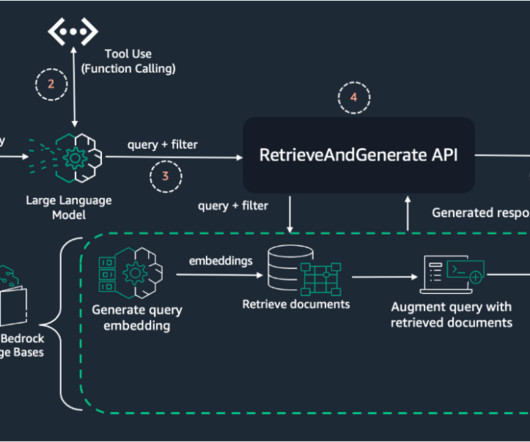
The retrieve_and_generate API does both the retrieval and a call to an FM (Amazon Titan or Anthropic’s Claude family of models on Amazon Bedrock ), for a fully managed solution. Mean Reciprocal Rank (MRR) – This metric considers the ranking of the retrieved documents. More advanced models such as Anthropic’s Claude Sonnet 3.5
The GenASL web app invokes the backend services by sending the S3 object key in the payload to an API hosted on Amazon API Gateway. API Gateway instantiates an AWS Step Functions The state machine orchestrates the AI/ML services Amazon Transcribe and Amazon Bedrock and the NoSQL data store Amazon DynamoDB using AWS Lambda functions.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content