This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Amazon Bedrock announces the preview launch of Session Management APIs, a new capability that enables developers to simplify state and context management for generative AI applications built with popular open source frameworks such as LangGraph and LlamaIndex. Building generative AI applications requires more than model API calls.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. API Gateway is serverless and hence automatically scales with traffic. API Gateway also provides a WebSocket API. As a result, building such a solution is often a significant undertaking for IT teams.
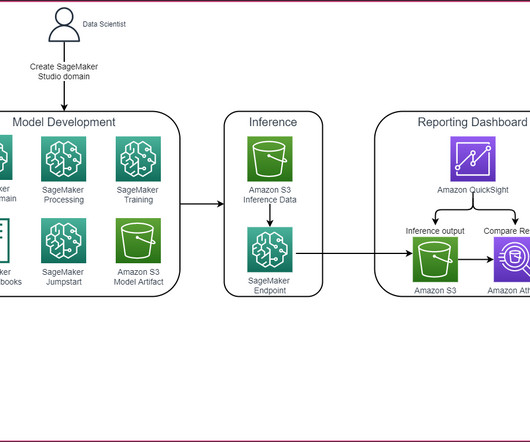
Customers can use the SageMaker Studio UI or APIs to specify the SageMaker Model Registry model to be shared and grant access to specific AWS accounts or to everyone in the organization. With this launch, customers can now seamlessly share and access ML models registered in SageMaker Model Registry between different AWS accounts.
Building generative AI applications presents significant challenges for organizations: they require specialized ML expertise, complex infrastructure management, and careful orchestration of multiple services. This includes setting up Amazon API Gateway , AWS Lambda functions, and Amazon Athena to enable querying the structured sales data.
The rapid advancement of generative AI promises transformative innovation, yet it also presents significant challenges. For automatic model evaluation jobs, you can either use built-in datasets across three predefined metrics (accuracy, robustness, toxicity) or bring your own datasets.
This post presents a solution where you can upload a recording of your meeting (a feature available in most modern digital communication services such as Amazon Chime ) to a centralized video insights and summarization engine. All of this data is centralized and can be used to improve metrics in scenarios such as sales or call centers.
The scale down to zero feature presents new opportunities for how businesses can approach their cloud-based ML operations. Use faster auto scaling metrics – Take advantage of more granular auto scaling metrics like ConcurrentRequestsPerCopy to more accurately monitor and react to changes in inference traffic.
Current RAG pipelines frequently employ similarity-based metrics such as ROUGE , BLEU , and BERTScore to assess the quality of the generated responses, which is essential for refining and enhancing the models capabilities. More sophisticated metrics are needed to evaluate factual alignment and accuracy.
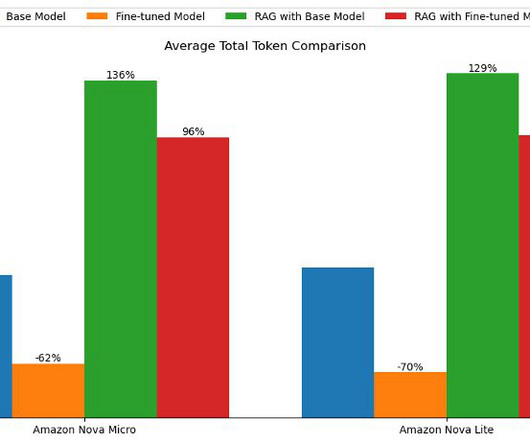
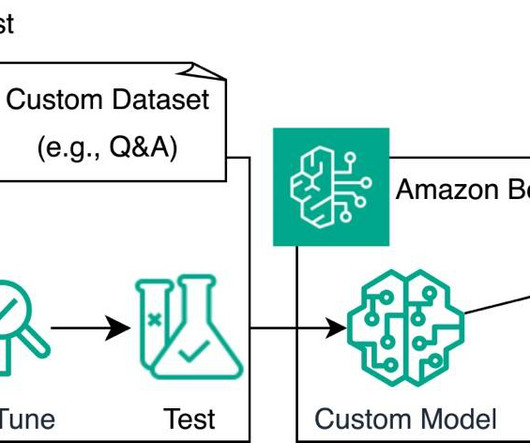
Approach and base model overview In this section, we discuss the differences between a fine-tuning and RAG approach, present common use cases for each approach, and provide an overview of the base model used for experiments. To do so, we create a knowledge base. The following diagram illustrates the solution architecture.
adds new APIs to customize GraphStorm pipelines: you now only need 12 lines of code to implement a custom node classification training loop. Based on customer feedback for the experimental APIs we released in GraphStorm 0.2, introduces refactored graph ML pipeline APIs. Specifically, GraphStorm 0.3 In addition, GraphStorm 0.3
For instance, Pixtral Large is highly effective at spotting irregularities or insightful trends within training loss curves or performance metrics, enhancing the accuracy of data-driven decision-making. By choosing View API , you can also access the model using code examples in the AWS Command Line Interface (AWS CLI) and AWS SDKs.
Performance metrics and benchmarks Pixtral 12B is trained to understand both natural images and documents, achieving 52.5% You can find detailed usage instructions, including sample API calls and code snippets for integration. To begin using Pixtral 12B, choose Deploy. We use the following input image. We use the following input image.
During these live events, F1 IT engineers must triage critical issues across its services, such as network degradation to one of its APIs. This impacts downstream services that consume data from the API, including products such as F1 TV, which offer live and on-demand coverage of every race as well as real-time telemetry.
As attendees circulate through the GAIZ, subject matter experts and Generative AI Innovation Center strategists will be on-hand to share insights, answer questions, present customer stories from an extensive catalog of reference demos, and provide personalized guidance for moving generative AI applications into production.
The solution uses the FMs tool use capabilities, accessed through the Amazon Bedrock Converse API. This enables the FMs to not just process text, but to actively engage with various external tools and APIs to perform complex document analysis tasks. For more details on how tool use works, refer to The complete tool use workflow.
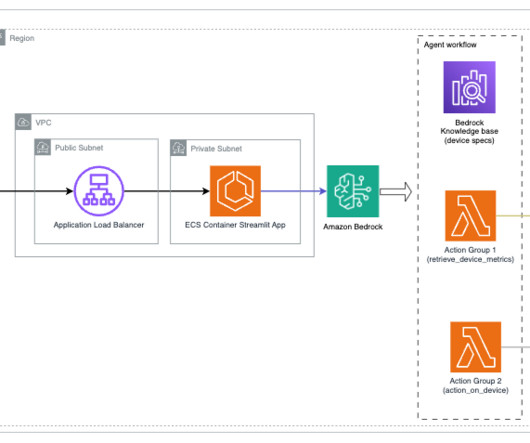
Amazon Bedrock agents use LLMs to break down tasks, interact dynamically with users, run actions through API calls, and augment knowledge using Amazon Bedrock Knowledge Bases. In this post, we demonstrate how to use Amazon Bedrock Agents with a web search API to integrate dynamic web content in your generative AI application.
The user’s request is sent to AWS API Gateway , which triggers a Lambda function to interact with Amazon Bedrock using Anthropic’s Claude Instant V1 FM to process the user’s request and generate a natural language response of the place location. These features are presented in a web UI that was designed as a one-stop solution for our users.
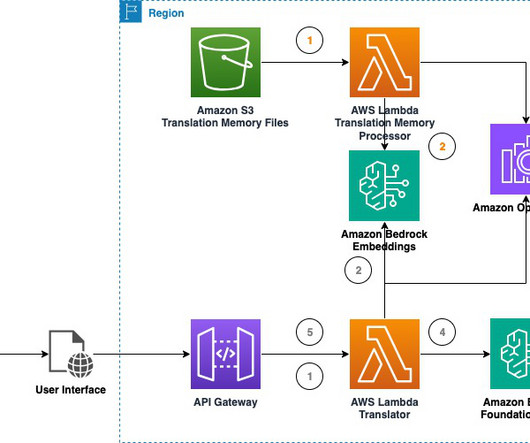
This blog post with accompanying code presents a solution to experiment with real-time machine translation using foundation models (FMs) available in Amazon Bedrock. Also note the completion metrics on the left pane, displaying latency, input/output tokens, and quality scores.
The retrieve_and_generate API does both the retrieval and a call to an FM (Amazon Titan or Anthropic’s Claude family of models on Amazon Bedrock ), for a fully managed solution. Mean Reciprocal Rank (MRR) – This metric considers the ranking of the retrieved documents. Adding guardrails against such behavior is essential.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Where discrete outcomes with labeled data exist, standard ML methods such as precision, recall, or other classic ML metrics can be used. These metrics provide high precision but are limited to specific use cases due to limited ground truth data. If the use case doesnt yield discrete outputs, task-specific metrics are more appropriate.
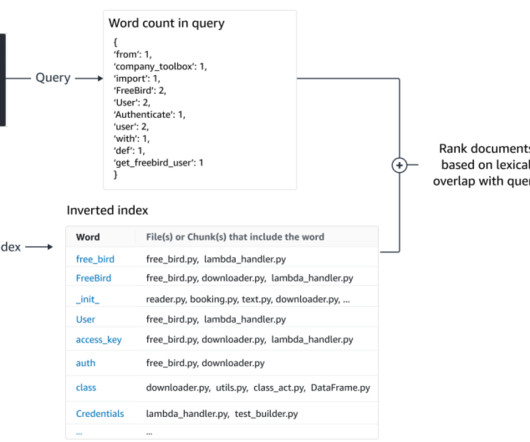
A seamless search journey not only enhances the overall user experience, but also directly impacts key business metrics such as conversion rates, average order value, and customer loyalty. However, combining keyword search and semantic search presents significant complexity because different query types provide scores on different scales.
The device further processes this response, including text-to-speech (TTS) conversion for voice agents, before presenting it to the user. They enable applications requiring very low latency or local data processing using familiar APIs and tool sets. Each request contains a random prompt with a mean token count of 250 tokens.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Then we dive into the two key metrics used to evaluate a biometric system’s accuracy: the false match rate (also known as false acceptance rate) and false non-match rate (also known as false rejection rate). We use FMR and FNMR as our two key metrics to evaluate facial biometric systems. False non-match rate.
Challenge 2: Integration with Wearables and Third-Party APIs Many people use smartwatches and heart rate monitors to measure sleep, stress, and physical activity, which may affect mental health. Third-party APIs may link apps to healthcare and meditation services. However, integrating these diverse sources is not straightforward.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon using a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
Building document processing and understanding solutions for financial and research reports, medical transcriptions, contracts, media articles, and so on requires extraction of information present in titles, headers, paragraphs, and so on. Text – Text that is present typically as a part of paragraphs in documents.
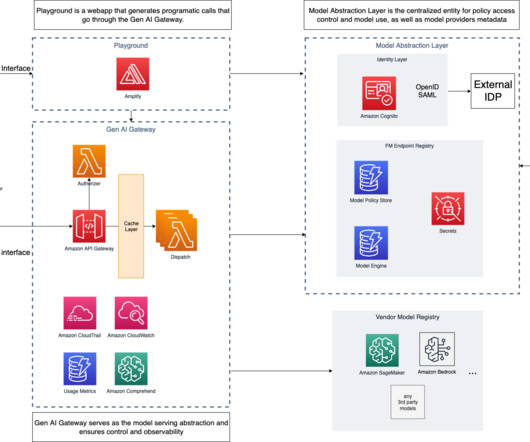
A Generative AI Gateway can help large enterprises control, standardize, and govern FM consumption from services such as Amazon Bedrock , Amazon SageMaker JumpStart , third-party model providers (such as Anthropic and their APIs), and other model providers outside of the AWS ecosystem. What is a Generative AI Gateway?
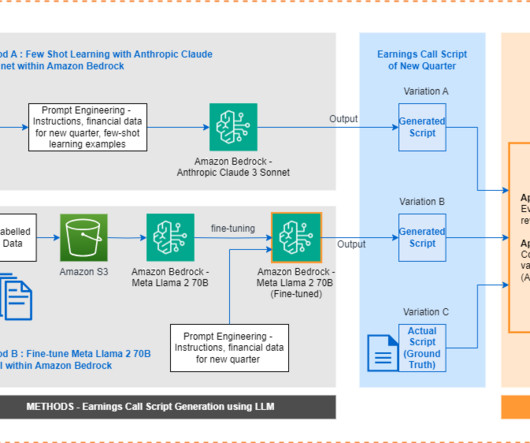
Earnings calls are live conferences where executives present an overview of results, discuss achievements and challenges, and provide guidance for upcoming periods. Draft a comprehensive earnings call script that covers the key financial metrics, business highlights, and future outlook for the given quarter.
This benefits enterprise software development and helps overcome the following challenges: Sparse documentation or information for internal libraries and APIs that forces developers to spend time examining previously written code to replicate usage. Inadvertent use of deprecated code and APIs by developers.
It provides a unified interface for logging parameters, code versions, metrics, and artifacts, making it easier to compare experiments and manage the model lifecycle. From our experience, artifact server has some limitations, such as limits on artifact size (because of sending it using REST API).
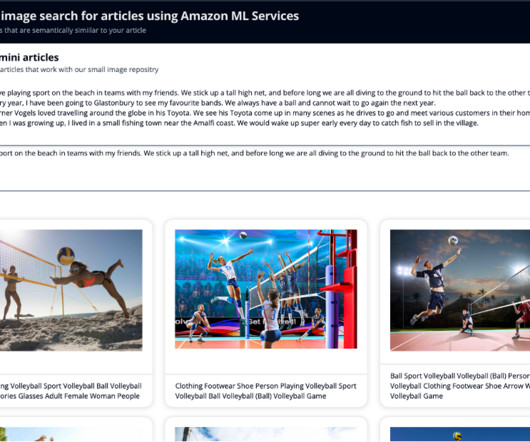
Amazon Rekognition makes it easy to add image analysis capability to your applications without any machine learning (ML) expertise and comes with various APIs to fulfil use cases such as object detection, content moderation, face detection and analysis, and text and celebrity recognition, which we use in this example.
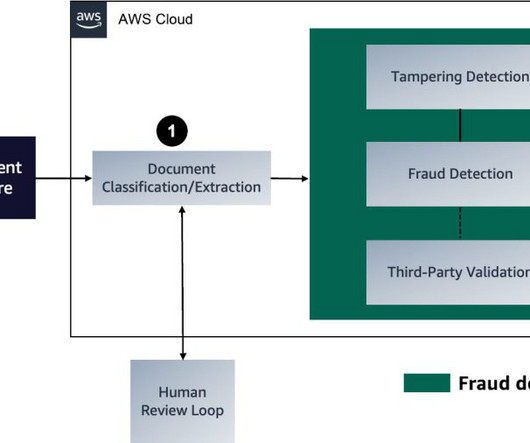
In the first post of this three-part series, we presented a solution that demonstrates how you can automate detecting document tampering and fraud at scale using AWS AI and machine learning (ML) services for a mortgage underwriting use case. Deploy the API to make predictions. Select your options and train the model. Create the model.
This is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API. These metrics will assess how well a machine-generated summary compares to one or more reference summaries.
Beyond model accuracy, other potential metrics of importance are model training time and inference time. JumpStart APIs allow you to programmatically deploy and fine-tune a vast selection of JumpStart-supported pre-trained models on your own datasets. In this section, we present the results from these 15 runs. Solution overview.
Query training results: This step calls the Lambda function to fetch the metrics of the completed training job from the earlier model training step. RMSE threshold: This step verifies the trained model metric (RMSE) against a defined threshold to decide whether to proceed towards endpoint deployment or reject this model.
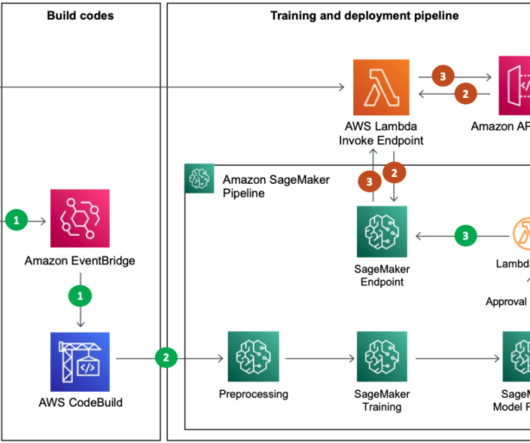
The main AWS services used are SageMaker, Amazon EMR , AWS CodeBuild , Amazon Simple Storage Service (Amazon S3), Amazon EventBridge , AWS Lambda , and Amazon API Gateway. Real-time recommendation inference The inference phase consists of the following steps: The client application makes an inference request to the API gateway.
For a quantitative analysis of the generated impression, we use ROUGE (Recall-Oriented Understudy for Gisting Evaluation), the most commonly used metric for evaluating summarization. This metric compares an automatically produced summary against a reference or a set of references (human-produced) summary or translation.
You can then compare the performance of the two versions using metrics such as latency and error rate. Optionally, you can monitor the variants through a built-in dashboard with a side-by-side comparison of the performance metrics. Please refer to the CreateModel API here. Pre-requisites. Step 1 – Create a shadow test.
However, delivering truly personalized recommendations presents several key challenges: Capturing diverse user interests – News can span many topics and even within specific topics, readers can have varied interests. For more information about these metrics, see Evaluating a solution version with metrics.
Validation loss and validation perplexity – Similar to the training metrics, but measured during the validation stage. Use the model You can access your fine-tuned LLM through the Amazon Bedrock console, API, CLI, or SDKs. He actively shares his expertise through his YouTube channel, blog posts, and presentations.
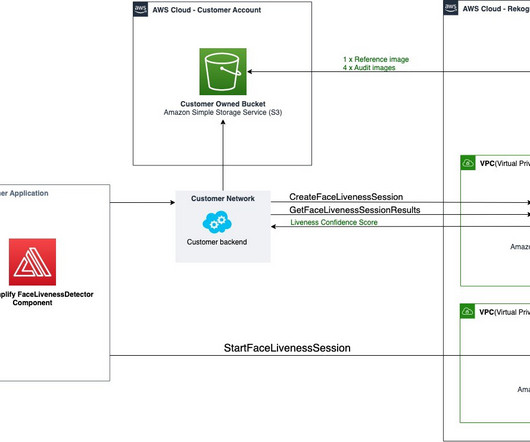
Some customers use third-party face liveness features that can only detect spoof attacks presented to the camera (such as printed or digital photos or videos on a screen), which work well for users in select geographies, and are often completely customer-managed. Spoof detection Face Liveness can deter presentation and bypass spoof attacks.
The deployment of agentic systems should focus on well-defined processes with clear success metrics and where there is potential for greater flexibility and less brittleness in process management. You can deploy or fine-tune models through an intuitive UI or APIs, providing flexibility for all skill levels.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content