This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
How do Amazon Nova Micro and Amazon Nova Lite perform against GPT-4o mini in these same metrics? Amazon Bedrock APIs make it straightforward to use Amazon Titan Text Embeddings V2 for embedding data. Vector database FloTorch selected Amazon OpenSearch Service as a vector database for its high-performance metrics.
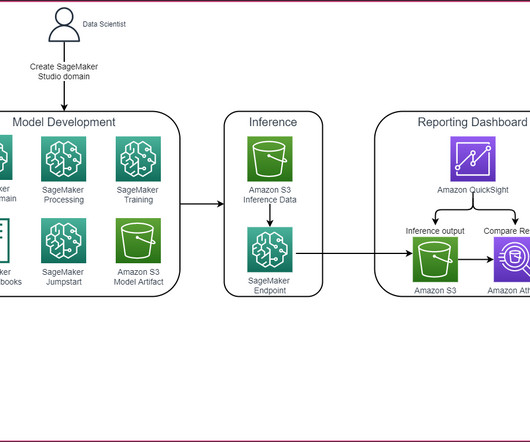
Customers can use the SageMaker Studio UI or APIs to specify the SageMaker Model Registry model to be shared and grant access to specific AWS accounts or to everyone in the organization. We will start by using the SageMaker Studio UI and then by using APIs.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
The goal was to refine customer service scripts, provide coaching opportunities for agents, and improve call handling processes. Frontend and API The CQ application offers a robust search interface specially crafted for call quality agents, equipping them with powerful auditing capabilities for call analysis.
Amazon Bedrock agents use LLMs to break down tasks, interact dynamically with users, run actions through API calls, and augment knowledge using Amazon Bedrock Knowledge Bases. In this post, we demonstrate how to use Amazon Bedrock Agents with a web search API to integrate dynamic web content in your generative AI application.
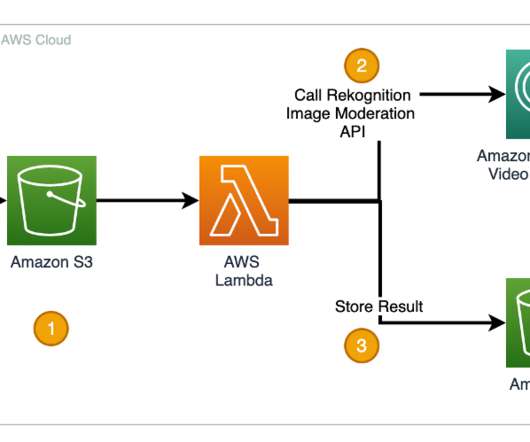
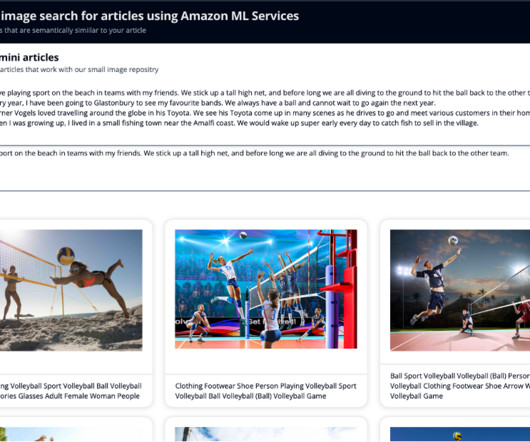
Amazon Rekognition has two sets of APIs that help you moderate images or videos to keep digital communities safe and engaged. Some customers have asked if they could use this approach to moderate videos by sampling image frames and sending them to the Amazon Rekognition image moderation API.
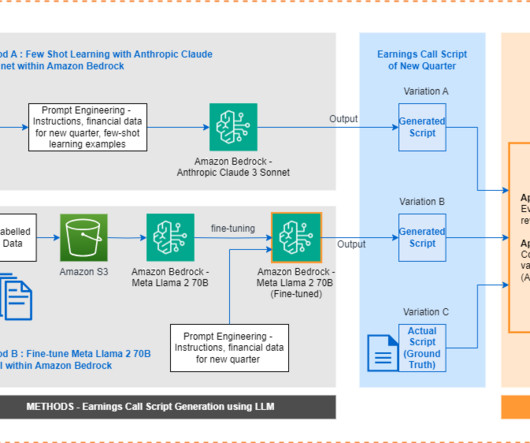
Investors and analysts closely watch key metrics like revenue growth, earnings per share, margins, cash flow, and projections to assess performance against peers and industry trends. Traditionally, earnings call scripts have followed similar templates, making it a repeatable task to generate them from scratch each time.
Where discrete outcomes with labeled data exist, standard ML methods such as precision, recall, or other classic ML metrics can be used. These metrics provide high precision but are limited to specific use cases due to limited ground truth data. If the use case doesnt yield discrete outputs, task-specific metrics are more appropriate.
The retrieve_and_generate API does both the retrieval and a call to an FM (Amazon Titan or Anthropic’s Claude family of models on Amazon Bedrock ), for a fully managed solution. Mean Reciprocal Rank (MRR) – This metric considers the ranking of the retrieved documents. More advanced models such as Anthropic’s Claude Sonnet 3.5
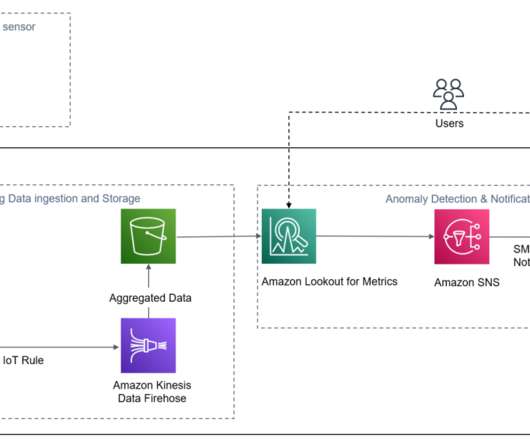
This post shows you how to use an integrated solution with Amazon Lookout for Metrics and Amazon Kinesis Data Firehose to break these barriers by quickly and easily ingesting streaming data, and subsequently detecting anomalies in the key performance indicators of your interest. You don’t need ML experience to use Lookout for Metrics.
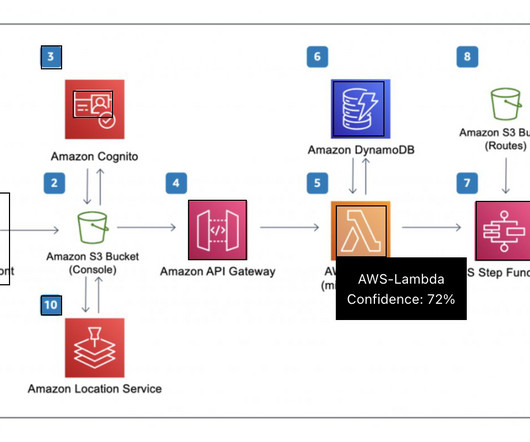
AWS Prototyping successfully delivered a scalable prototype, which solved CBRE’s business problem with a high accuracy rate (over 95%) and supported reuse of embeddings for similar NLQs, and an API gateway for integration into CBRE’s dashboards. The following diagram illustrates the web interface and API management layer.
Image 2: Hugging Face NLP model inference performance improvement with torch.compile on AWS Graviton3-based c7g instance using Hugging Face example scripts. This section shows how to run inference in eager and torch.compile modes using torch Python wheels and benchmarking scripts from Hugging Face and TorchBench repos.
Consequently, no other testing solution can provide the range and depth of testing metrics and analytics. And testingRTC offers multiple ways to export these metrics, from direct collection from webhooks, to downloading results in CSV format using the REST API. Happy days! You can check framerate information for video here too.
The first allows you to run a Python script from any server or instance including a Jupyter notebook; this is the quickest way to get started. In the following sections, we first describe the script solution, followed by the AWS CDK construct solution. The following diagram illustrates the sequence of events within the script.
All the training and evaluation metrics were inspected manually from Amazon Simple Storage Service (Amazon S3). The code to invoke the pipeline script is available in the Studio notebooks, and we can change the hyperparameters and input/output when invoking the pipeline.
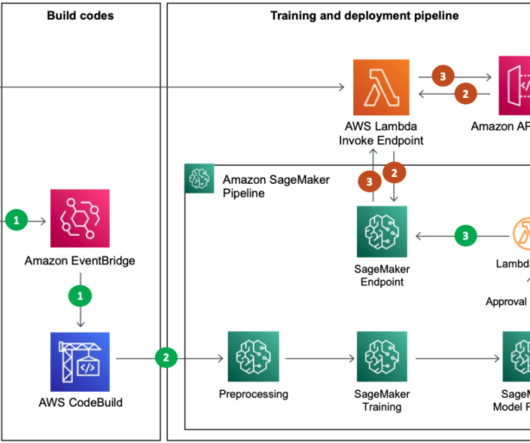
The main AWS services used are SageMaker, Amazon EMR , AWS CodeBuild , Amazon Simple Storage Service (Amazon S3), Amazon EventBridge , AWS Lambda , and Amazon API Gateway. Real-time recommendation inference The inference phase consists of the following steps: The client application makes an inference request to the API gateway.
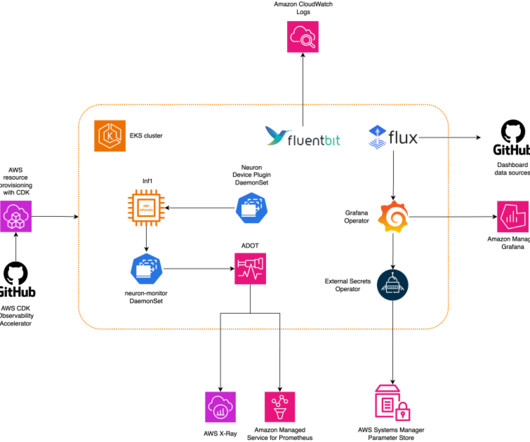
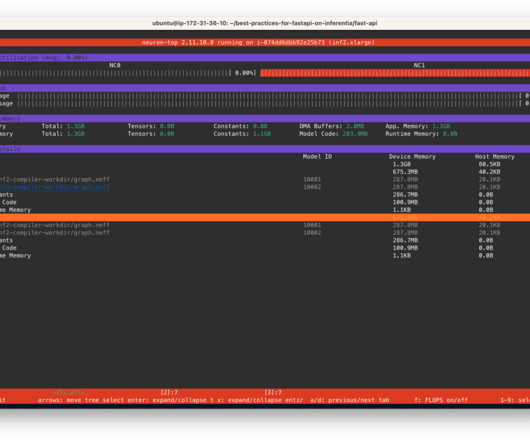
Metrics allow teams to understand workload behavior and optimize resource allocation and utilization, diagnose anomalies, and increase overall infrastructure efficiency. Metrics are exposed to Amazon Managed Service for Prometheus by the neuron-monitor DaemonSet, which deploys a minimal container, with the Neuron tools installed.
Here are some features which we will cover: AWS CloudFormation support Private network policies for Amazon OpenSearch Serverless Multiple S3 buckets as data sources Service Quotas support Hybrid search, metadata filters, custom prompts for the RetreiveAndGenerate API, and maximum number of retrievals.
Amazon Rekognition makes it easy to add image analysis capability to your applications without any machine learning (ML) expertise and comes with various APIs to fulfil use cases such as object detection, content moderation, face detection and analysis, and text and celebrity recognition, which we use in this example.
Lastly the model is tested against a set of known genome sequences using some inference API calls. Training on SageMaker We use PyTorch and Amazon SageMaker script mode to train this model. Script mode’s compatibility with PyTorch was crucial, allowing us to use our existing scripts with minimal modifications.
Continuous integration and continuous delivery (CI/CD) pipeline – Using the customer’s GitHub repository enabled code versioning and automated scripts to launch pipeline deployment whenever new versions of the code are committed. Wipro has used the input filter and join functionality of SageMaker batch transformation API.
Amazon Q Business only provides metric information that you can use to monitor your data source sync jobs. We recommend running similar scripts only on your own data sources after consulting with the team who manages them, or be sure to follow the terms of service for the sources that youre trying to fetch data from.
For a quantitative analysis of the generated impression, we use ROUGE (Recall-Oriented Understudy for Gisting Evaluation), the most commonly used metric for evaluating summarization. This metric compares an automatically produced summary against a reference or a set of references (human-produced) summary or translation.
Solution overview In this section, we present a generic architecture that is similar to the one we use for our own workloads, which allows elastic deployment of models using efficient auto scaling based on custom metrics. The reverse proxy collects metrics about calls to the service and exposes them via a standard metricsAPI to Prometheus.
From there, we dive into how you can track and understand the metrics and performance of the SageMaker endpoint utilizing Amazon CloudWatch metrics. Metrics to track. Before we can get into load testing, it’s essential to understand what metrics to track to understand the performance breakdown of your SageMaker endpoint.
Together with the implementation details in a corresponding example Jupyter notebook , you will have tools available to perform model selection by exploring pareto frontiers, where improving one performance metric, such as accuracy, is not possible without worsening another metric, such as throughput.
An asynchronous API and Amazon OpenSearch Service connector make it easy to integrate the model into your neural search applications. Before you can write scripts that use the Amazon Bedrock API, you need to install the appropriate version of the AWS SDK in your environment. The vectors power speedy, accurate search experiences.
Lets delve into a basic Colang script to see how it works: define user express greeting "hello" "hi" "what's up?" define flow greeting user express greeting bot express greeting bot ask how are you In this script, we see the three fundamental types of blocks in Colang: User Message Blocks (define user ): These define possible user inputs.
The ML components for data ingestion, preprocessing, and model training were available as disjointed Python scripts and notebooks, which required a lot of manual heavy lifting on the part of engineers. This step produces an expanded report containing the model’s metrics.
For this we use AWS Step Functions , a serverless workflow service that provides us with API integrations to quickly orchestrate and visualize the steps in our workflow. Use the scripts created in step one as part of the processing and training steps. We started by creating command line scripts from the experiment code.
Dataset collection We followed the methodology outlined in the PMC-Llama paper [6] to assemble our dataset, which includes PubMed papers sourced from the Semantic Scholar API and various medical texts cited within the paper, culminating in a comprehensive collection of 88 billion tokens. Create and launch ParallelCluster in the VPC.
If the model changes on the server side, the client has to know and change its API call to the new endpoint accordingly. Based on these metrics an informed decision can be made. Clone the Github repository The GitHub repo provides all the scripts necessary to deploy models using FastAPI on NeuronCores on AWS Inferentia instances.
Autopilot training jobs start their own dedicated SageMaker backend processes, and dedicated SageMaker API calls are required to start new training jobs, monitor training job statuses, and invoke trained Autopilot models. We use a Lambda step because the API call to Autopilot is lightweight. script creates an Autopilot job.
This often means the method of using a third-party LLM API won’t do for security, control, and scale reasons. It provides an approachable, robust Python API for the full infrastructure stack of ML/AI, from data and compute to workflows and observability. The following figure illustrates this workflow.
By uploading a small set of training images, Amazon Rekognition automatically loads and inspects the training data, selects the right ML algorithms, trains a model, and provides model performance metrics. A Python script is used to aid in the process of uploading the datasets and generating the manifest file.
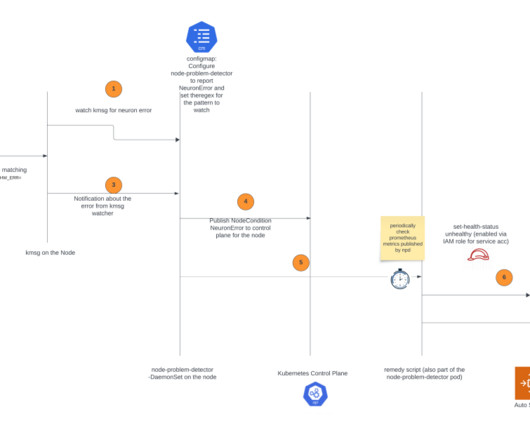
If it detects error messages specifically related to the Neuron device (which is the Trainium or AWS Inferentia chip), it will change NodeCondition to NeuronHasError on the Kubernetes API server. The node recovery agent is a separate component that periodically checks the Prometheus metrics exposed by the node problem detector.
SageMaker services, such as Processing, Training, and Hosting, collect metrics and logs from the running instances and push them to users’ Amazon CloudWatch accounts. One example is performing a metric query on the SageMaker job host’s utilization metrics when a job completion event is received.
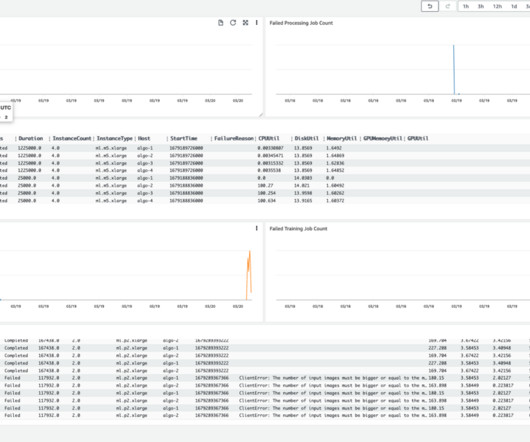
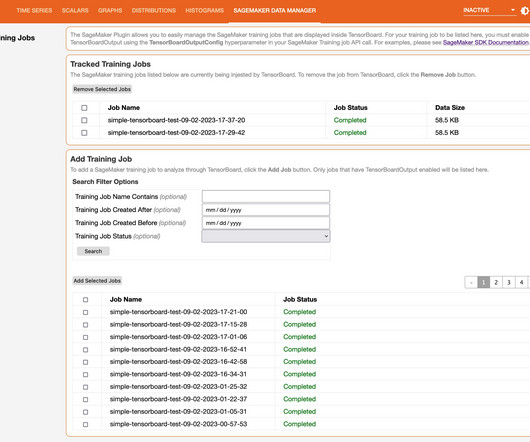
It provides a suite of tools for visualizing training metrics, examining model architectures, exploring embeddings, and more. When they create a SageMaker training job, domain users can use TensorBoard using the SageMaker Python SDK or Boto3 API. is your training script, and simple_tensorboard.ipynb launches the SageMaker training job.
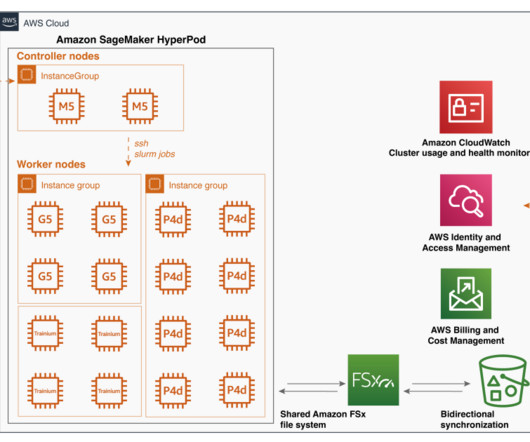
This text-to-video API generates high-quality, realistic videos quickly from text and images. Customizable environment – SageMaker HyperPod offers the flexibility to customize your cluster environment using lifecycle scripts. Video generation has become the latest frontier in AI research, following the success of text-to-image models.
Defining the right objective metric matching your task. When our tuning job is complete, we look at some of the methods available to explore the results, both via the AWS Management Console and programmatically via the AWS SDKs and APIs. Collects metrics and logs. Amazon SageMaker Automatic Model Tuning. Runs the training.
A new optional parameter TableFormat can be set either interactively using Amazon SageMaker Studio or through code using the API or the SDK. The following code snippet shows you how to create a feature group using the Iceberg format and FeatureGroup.create API of the SageMaker SDK. You can find the sample script in GitHub.
The goal of NAS is to find the optimal architecture for a given problem by searching over a large set of candidate architectures using techniques such as gradient-free optimization or by optimizing the desired metrics. The performance of the architecture is typically measured using metrics such as validation loss. training.py ).
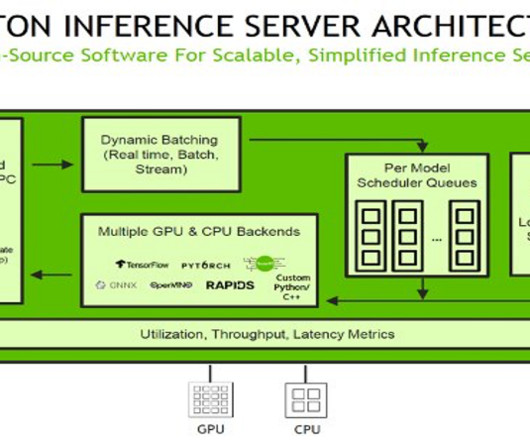
Triton with PyTorch backend The PyTorch backend is designed to run TorchScript models using the PyTorch C++ API. Alternatively, you can use ensemble models or business logic scripting. file in the workspace directory contains scripts to load and save a PyTorch model. client(service_name="sagemaker") runtime_sm_client = boto3.client("sagemaker-runtime")
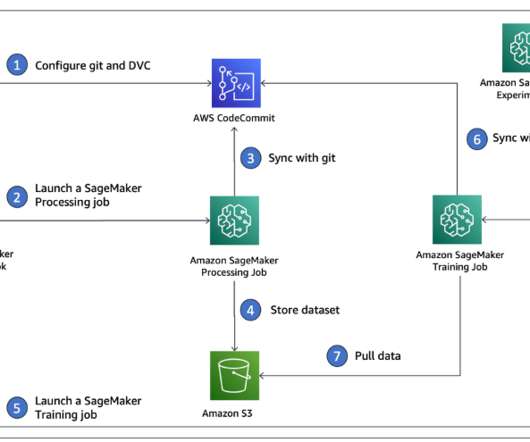
This post walks you through an example of how to track your experiments across code, data, artifacts, and metrics by using Amazon SageMaker Experiments in conjunction with Data Version Control (DVC). In each individual experiment, we track input and output artifacts, code, and metrics using SageMaker Experiments. SageMaker Experiments.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content