This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. This results in an imbalanced class distribution for training and test datasets.
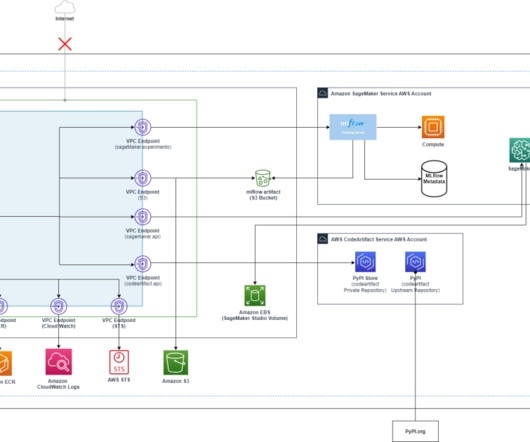
Customers can use the SageMaker Studio UI or APIs to specify the SageMaker Model Registry model to be shared and grant access to specific AWS accounts or to everyone in the organization. We will start by using the SageMaker Studio UI and then by using APIs.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. API Gateway is serverless and hence automatically scales with traffic. API Gateway also provides a WebSocket API. Incoming requests to the gateway go through this point.
Similarly, maintaining detailed information about the datasets used for training and evaluation helps identify potential biases and limitations in the models knowledge base. Evaluation algorithm Computes evaluation metrics to model outputs. Different algorithms have different metrics to be specified.
With access to a wide range of generative AI foundation models (FM) and the ability to build and train their own machine learning (ML) models in Amazon SageMaker , users want a seamless and secure way to experiment with and select the models that deliver the most value for their business. config_yaml = f""" SchemaVersion: '1.0'
Demystifying RAG and model customization RAG is a technique to enhance the capability of pre-trained models by allowing the model access to external domain-specific data sources. Unlike fine-tuning, in RAG, the model doesnt undergo any training and the model weights arent updated to learn the domain knowledge.
Current RAG pipelines frequently employ similarity-based metrics such as ROUGE , BLEU , and BERTScore to assess the quality of the generated responses, which is essential for refining and enhancing the models capabilities. More sophisticated metrics are needed to evaluate factual alignment and accuracy.
All of this data is centralized and can be used to improve metrics in scenarios such as sales or call centers. For integration between services, we use API Gateway as an event trigger for our Lambda function, and DynamoDB as a highly scalable database to store our customer details.
GraphStorm is a low-code enterprise graph machine learning (GML) framework to build, train, and deploy graph ML solutions on complex enterprise-scale graphs in days instead of months. allows you to define multiple training targets on different nodes and edges within a single training loop. Specifically, GraphStorm 0.3
This approach allows organizations to assess their AI models effectiveness using pre-defined metrics, making sure that the technology aligns with their specific needs and objectives. The introduction of an LLM-as-a-judge framework represents a significant step forward in simplifying and streamlining the model evaluation process.
In this post, we describe the enhancements to the forecasting capabilities of SageMaker Canvas and guide you on using its user interface (UI) and AutoML APIs for time-series forecasting. While the SageMaker Canvas UI offers a code-free visual interface, the APIs empower developers to interact with these features programmatically.
Discover how the fully managed infrastructure of SageMaker enables high-performance, low cost ML throughout the ML lifecycle, from building and training to deploying and managing models at scale. AWS Trainium and AWS Inferentia deliver high-performance AI training and inference while reducing your costs by up to 50%.
In this blog post and open source project , we show you how you can pre-train a genomics language model, HyenaDNA , using your genomic data in the AWS Cloud. Amazon SageMaker Amazon SageMaker is a fully managed ML service offered by AWS, designed to reduce the time and cost associated with training and tuning ML models at scale.
In recent years, large language models (LLMs) have gained attention for their effectiveness, leading various industries to adapt general LLMs to their data for improved results, making efficient training and hardware availability crucial. In this post, we show you how efficient we make our continual pre-training by using Trainium chips.
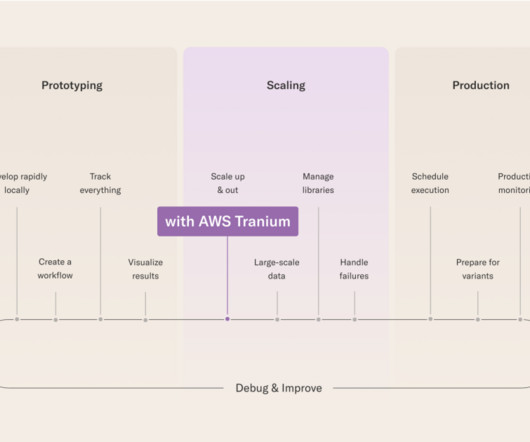
This often means the method of using a third-party LLM API won’t do for security, control, and scale reasons. First, the AWS Trainium accelerator provides a high-performance, cost-effective, and readily available solution for training and fine-tuning large models. The following figure illustrates this workflow.
Amazon Lookout for Metrics is a fully managed service that uses machine learning (ML) to detect anomalies in virtually any time-series business or operational metrics—such as revenue performance, purchase transactions, and customer acquisition and retention rates—with no ML experience required. To learn more, see the documentation.
The Amazon Bedrock single API access, regardless of the models you choose, gives you the flexibility to use different FMs and upgrade to the latest model versions with minimal code changes. Amazon Titan FMs provide customers with a breadth of high-performing image, multimodal, and text model choices, through a fully managed API.
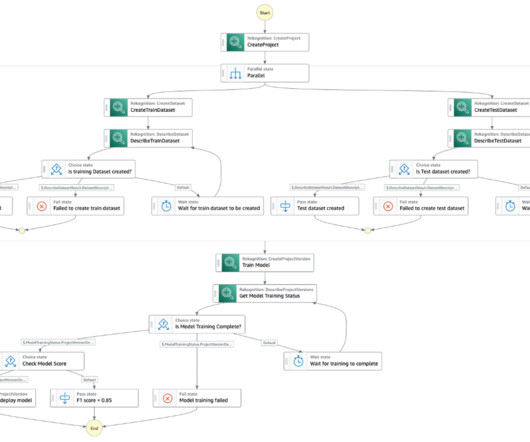
With Amazon Rekognition Custom Labels , you can have Amazon Rekognition train a custom model for object detection or image classification specific to your business needs. Rekognition Custom Labels builds off of the existing capabilities of Amazon Rekognition, which is already trained on tens of millions of images across many categories.
Large language models (LLMs) are generally trained on large publicly available datasets that are domain agnostic. For example, Meta’s Llama models are trained on datasets such as CommonCrawl , C4 , Wikipedia, and ArXiv. The resulting LLM outperforms LLMs trained on non-domain-specific datasets when tested on finance-specific tasks.
For instance, Pixtral Large is highly effective at spotting irregularities or insightful trends within training loss curves or performance metrics, enhancing the accuracy of data-driven decision-making. By choosing View API , you can also access the model using code examples in the AWS Command Line Interface (AWS CLI) and AWS SDKs.
Performance metrics and benchmarks According to Mistral, the instruction-tuned version of the model achieves over 81% accuracy on Massive Multitask Language Understanding (MMLU) with 150 tokens per second latency, making it currently the most efficient model in its category. It doesnt support Converse APIs or other Amazon Bedrock tooling.
The vision encoder was specifically trained to natively handle variable image sizes, enabling Pixtral to accurately interpret high-resolution diagrams, charts, and documents while maintaining fast inference speeds for smaller images such as icons, clipart, and equations. To begin using Pixtral 12B, choose Deploy.
To effectively optimize AI applications for responsiveness, we need to understand the key metrics that define latency and how they impact user experience. These metrics differ between streaming and nonstreaming modes and understanding them is crucial for building responsive AI applications.
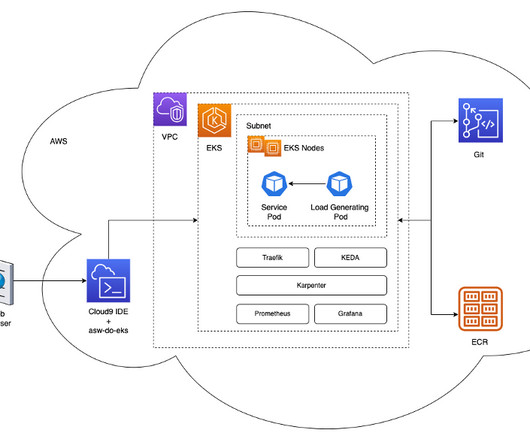
In this post, we focus on how we used Karpenter on Amazon Elastic Kubernetes Service (Amazon EKS) to scale AI training and inference, which are core elements of the Iambic discovery platform. We wanted to build a scalable system to support AI training and inference. Here we use the number of requests per second as a custom metric.
This allowed Intact to transcribe customer calls accurately, train custom language models, simplify the call auditing process, and extract valuable customer insights more efficiently. This efficiency has allowed for more effective use of auditors’ time in devising coaching strategies, improving scripts, and agent training.
During these live events, F1 IT engineers must triage critical issues across its services, such as network degradation to one of its APIs. This impacts downstream services that consume data from the API, including products such as F1 TV, which offer live and on-demand coverage of every race as well as real-time telemetry.
Fine-tuning pre-trained language models allows organizations to customize and optimize the models for their specific use cases, providing better performance and more accurate outputs tailored to their unique data and requirements. Model customization in Amazon Bedrock involves the following actions: Create training and validation datasets.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
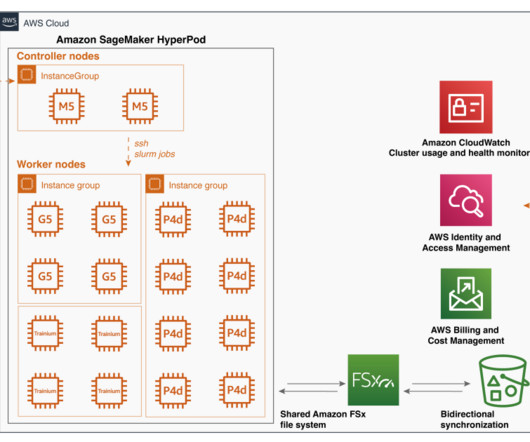
This text-to-video API generates high-quality, realistic videos quickly from text and images. Trained on the Amazon SageMaker HyperPod , Dream Machine excels in creating consistent characters, smooth motion, and dynamic camera movements. Luma AI’s recently launched Dream Machine represents a significant advancement in this field.
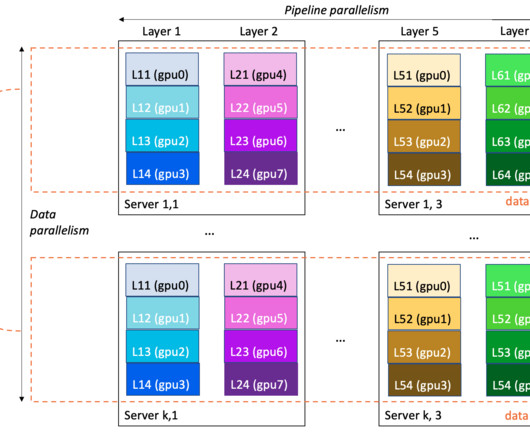
Large language models (LLMs) are neural network-based language models with hundreds of millions ( BERT ) to over a trillion parameters ( MiCS ), and whose size makes single-GPU training impractical. The size of an LLM and its training data is a double-edged sword: it brings modeling quality, but entails infrastructure challenges.
NVIDIA Nemotron-4 is now available on Amazon SageMaker JumpStart , significantly expanding the range of high-quality, pre-trained models available to our customers. 70B-Instruct : a 70-billion-parameter pre-trained, instruction-tuned model optimized for multilingual dialogue. Mixtral 8x7B Instruct v0.1:
In this post, we discuss the key elements needed to evaluate the performance aspect of a content moderation service in terms of various accuracy metrics, and a provide an example using Amazon Rekognition Content Moderation API’s. Understanding such distribution can help you define your actual metric goals. What to evaluate.
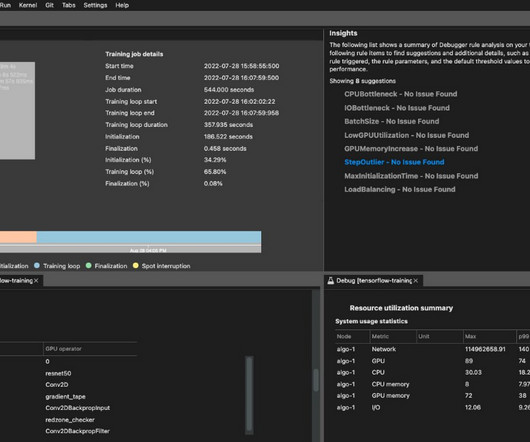
Model training forms the core of any machine learning (ML) project, and having a trained ML model is essential to adding intelligence to a modern application. Generally speaking, training a model from scratch is time-consuming and compute intensive. Model training in Studio. This post showcases the results of the study.
Frontier large language models (LLMs) like Anthropic Claude on Amazon Bedrock are trained on vast amounts of data, allowing Anthropic Claude to understand and generate human-like text. Solution overview Fine-tuning is a technique in natural language processing (NLP) where a pre-trained language model is customized for a specific task.
By incorporating these human translations into the LLMs training or inference process, the LLM can learn from and reuse these high-quality translations, potentially improving its overall performance. Amazon Titan Text Embeddings V2 includes multilingual support for over 100 languages in pre-training.
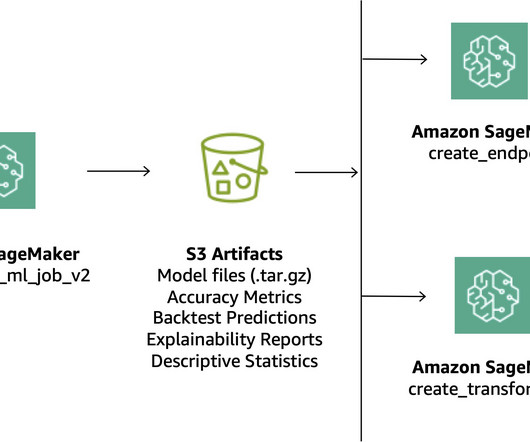
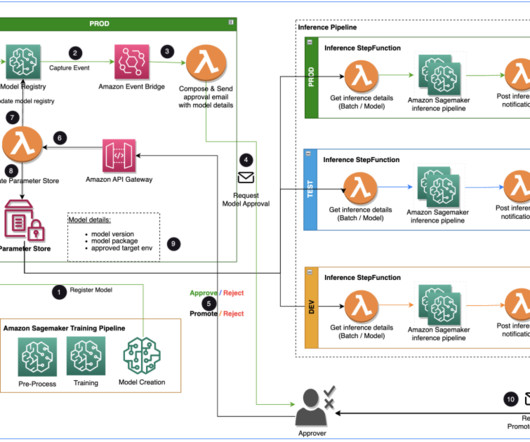
When a model is trained and ready to be used, it needs to be approved after being registered in the Amazon SageMaker Model Registry. Overview of solution This post focuses on a workflow solution that the ML model development lifecycle can use between the training pipeline and inferencing pipeline.
In this post, we show how to use Amazon Comprehend Custom to train and host an ML model to classify if the input email is an phishing attempt or not. Comprehend Custom builds customized NLP models on your behalf, using training data that you provide. For minimum training requirements, see General quotas for document classification.
It’s a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like Anthropic, Cohere, Meta, Mistral AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
In this post, we focus on SageMaker training jobs. With SageMaker training jobs, you can bring your own algorithm or choose from more than 25 built-in algorithms. The cost of a training job is based on the resources you use (instances and storage) for the duration (in seconds) that those instances are running.
Within hours, you can annotate your sample documents using the AWS Management Console and train an adapter. Adapters are components that plug in to the Amazon Textract pre-trained deep learning model, customizing its output based on your annotated documents. Adapters can be created via the console or programmatically via the API.
Trained on 1 trillion tokens, TII Falcon LLM boasts top-notch performance while remaining incredibly cost-effective. It’s available as open-source in two different sizes – Falcon-40B and Falcon-7B and was built from scratch using data preprocessing and model training jobs built on Amazon SageMaker. In 2022, Hoffman et al.
Trained on a large volume of datasets, these models incorporate memory components in their architectural design, allowing them to understand and comprehend textual context. RAG is the process of optimizing the output of an LLM so it references an authoritative knowledge base outside of its training data sources before generating a response.
The retrieve_and_generate API does both the retrieval and a call to an FM (Amazon Titan or Anthropic’s Claude family of models on Amazon Bedrock ), for a fully managed solution. Mean Reciprocal Rank (MRR) – This metric considers the ranking of the retrieved documents. External – Customers directly chat with a generative AI chatbot.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content