This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, we guide you through integrating Amazon Bedrock Agents with enterprise data APIs to create more personalized and effective customer support experiences. An automotive retailer might use inventory management APIs to track stock levels and catalog APIs for vehicle compatibility and specifications.
Amazon Bedrock announces the preview launch of Session Management APIs, a new capability that enables developers to simplify state and context management for generative AI applications built with popular open source frameworks such as LangGraph and LlamaIndex. Building generative AI applications requires more than model API calls.
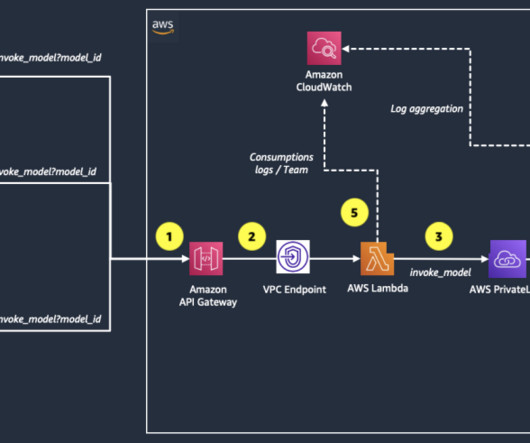
The custom Google Chat app, configured for HTTP integration, sends an HTTP request to an API Gateway endpoint. Before processing the request, a Lambda authorizer function associated with the API Gateway authenticates the incoming message. The following figure illustrates the high-level design of the solution.
It also uses a number of other AWS services such as Amazon API Gateway , AWS Lambda , and Amazon SageMaker. API Gateway is serverless and hence automatically scales with traffic. API Gateway also provides a WebSocket API. As a result, building such a solution is often a significant undertaking for IT teams.
In addition, they use the developer-provided instruction to create an orchestration plan and then carry out the plan by invoking company APIs and accessing knowledge bases using Retrieval Augmented Generation (RAG) to provide an answer to the users request. This differs from confirmation flows where the agent directly executes API calls.
In this post, we present a solution that takes a TDD approach to guardrail development, allowing you to improve your guardrails over time. This diagram presents the main workflow (Steps 1–4) and the optional automated workflow (Steps 5–7). Solution overview In this solution, you use a TDD approach to improve your guardrails.
This post presents a solution where you can upload a recording of your meeting (a feature available in most modern digital communication services such as Amazon Chime ) to a centralized video insights and summarization engine. With Lambda integration, we can create a web API with an endpoint to the Lambda function.
This innovative feature empowers viewers to catch up with what is being presented, making it simpler to grasp key points and highlights, even if they have missed portions of the live stream or find it challenging to follow complex discussions. To launch the solution in a different Region, change the aws_region parameter accordingly.
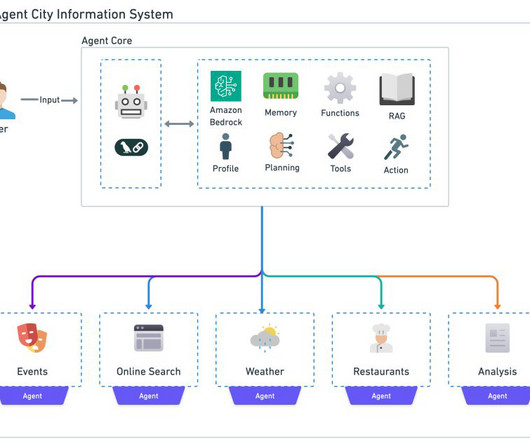
By using the power of LLMs and combining them with specialized tools and APIs, agents can tackle complex, multistep tasks that were previously beyond the reach of traditional AI systems. Whenever local database information is unavailable, it triggers an online search using the Tavily API. Its used by the weather_agent() function.
Amazon Bedrock Flows offers an intuitive visual builder and a set of APIs to seamlessly link foundation models (FMs), Amazon Bedrock features, and AWS services to build and automate user-defined generative AI workflows at scale. Present the information in a clear and engaging manner. Avoid any hallucinations or fabricated content.
Building generative AI applications presents significant challenges for organizations: they require specialized ML expertise, complex infrastructure management, and careful orchestration of multiple services. This includes setting up Amazon API Gateway , AWS Lambda functions, and Amazon Athena to enable querying the structured sales data.
adds new APIs to customize GraphStorm pipelines: you now only need 12 lines of code to implement a custom node classification training loop. Based on customer feedback for the experimental APIs we released in GraphStorm 0.2, introduces refactored graph ML pipeline APIs. Specifically, GraphStorm 0.3 In addition, GraphStorm 0.3
For more information, see Redacting PII entities with asynchronous jobs (API). After the user is authenticated, they are logged in to the web application, where an AI assistant UI is presented to the user. The query is then forwarded using a REST API call to an Amazon API Gateway endpoint along with the access tokens in the header.
Enabling Global Resiliency for an Amazon Lex bot is straightforward using the AWS Management Console , AWS Command Line Interface (AWS CLI), or APIs. You can see that the new Global Resiliency enabled version (Version 2) is replicated and the new alias BookHotelDemoAlias_GR is also present.
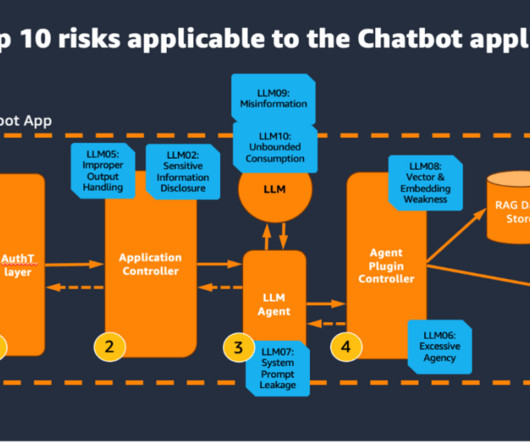
These steps might involve both the use of an LLM and external data sources and APIs. Agent plugin controller This component is responsible for the API integration to external data sources and APIs. The LLM agent is an orchestrator of a set of steps that might be necessary to complete the desired request.
The rapid advancement of generative AI promises transformative innovation, yet it also presents significant challenges. Simply upload an image to the Amazon Bedrock console, and the API will detect watermarks embedded in images generated by the Amazon Titan model, including both the base model and customized versions.
Solution overview Our solution implements a verified semantic cache using the Amazon Bedrock Knowledge Bases Retrieve API to reduce hallucinations in LLM responses while simultaneously improving latency and reducing costs. The function checks the semantic cache (Amazon Bedrock Knowledge Bases) using the Retrieve API.
The scale down to zero feature presents new opportunities for how businesses can approach their cloud-based ML operations. You can retrieve the number of copies of an inference component at any time by making the DescribeInferenceComponent API call and checking the CurrentCopyCount. import json scheduler = boto3.client('scheduler')
Customers can use the SageMaker Studio UI or APIs to specify the SageMaker Model Registry model to be shared and grant access to specific AWS accounts or to everyone in the organization. We will start by using the SageMaker Studio UI and then by using APIs.
Amazon Bedrock agents use LLMs to break down tasks, interact dynamically with users, run actions through API calls, and augment knowledge using Amazon Bedrock Knowledge Bases. In this post, we demonstrate how to use Amazon Bedrock Agents with a web search API to integrate dynamic web content in your generative AI application.
Its the kind of ambitious mission that excites me, not just because of its bold vision, but because of the incredible technical challenges it presents. Theyve taken on a technology most of us now take for granted: search. The results speak for themselvestheir inference stack achieves up to 3.1
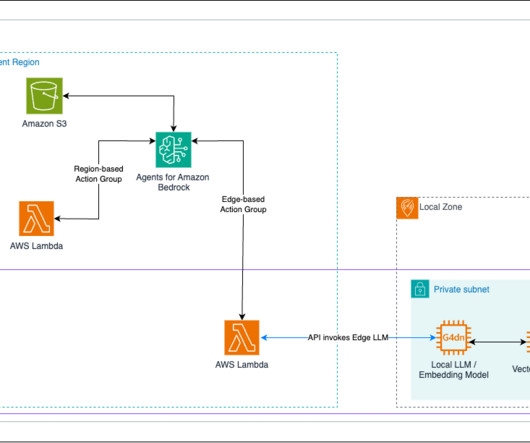
The embedding model, which is hosted on the same EC2 instance as the local LLM API inference server, converts the text chunks into vector representations. The prompt is forwarded to the local LLM API inference server instance, where the prompt is tokenized and is converted into a vector representation using the local embedding model.
You can find detailed usage instructions, including sample API calls and code snippets for integration. However, to invoke the deployed model programmatically with Amazon Bedrock APIs, you need to use the endpoint ARN as model-id in the Amazon Bedrock SDK. To begin using Pixtral 12B, choose Deploy. We use the following input image.
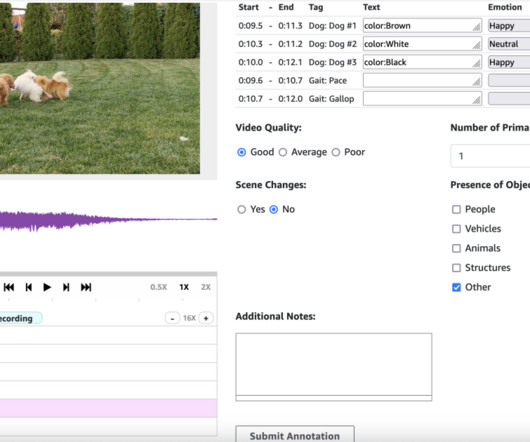
The path to creating effective AI models for audio and video generation presents several distinct challenges. The pre-annotation Lambda function can process the input manifest file before data is presented to annotators, enabling any necessary formatting or modifications. Extending Wavesurfer.js
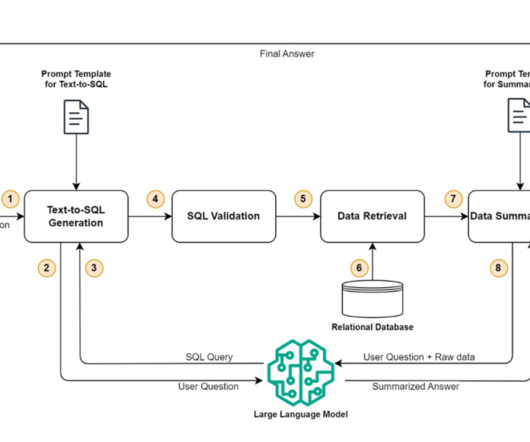
Enterprise-scale data presents specific challenges for NL2SQL, including the following: Complex schemas optimized for storage (and not retrieval) Enterprise databases are often distributed in nature and optimized for storage and not for retrieval. The end-user sends their natural language queries to the NL2SQL solution using a REST API.
This capability significantly broadens its usability, allowing it to support varied scenariosfrom explaining visual contexts in presentations to automating content moderation and contextual image retrieval. By choosing View API , you can also access the model using code examples in the AWS Command Line Interface (AWS CLI) and AWS SDKs.
The user’s request is sent to AWS API Gateway , which triggers a Lambda function to interact with Amazon Bedrock using Anthropic’s Claude Instant V1 FM to process the user’s request and generate a natural language response of the place location. These features are presented in a web UI that was designed as a one-stop solution for our users.
The solution uses the FMs tool use capabilities, accessed through the Amazon Bedrock Converse API. This enables the FMs to not just process text, but to actively engage with various external tools and APIs to perform complex document analysis tasks. For more details on how tool use works, refer to The complete tool use workflow.
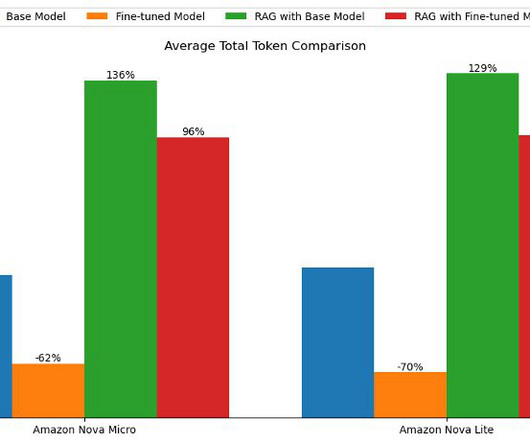
Approach and base model overview In this section, we discuss the differences between a fine-tuning and RAG approach, present common use cases for each approach, and provide an overview of the base model used for experiments. The following diagram illustrates the solution architecture.
Beyond Amazon Bedrock models, the service offers the flexible ApplyGuardrails API that enables you to assess text using your pre-configured guardrails without invoking FMs, allowing you to implement safety controls across generative AI applicationswhether running on Amazon Bedrock or on other systemsat both input and output levels.
As attendees circulate through the GAIZ, subject matter experts and Generative AI Innovation Center strategists will be on-hand to share insights, answer questions, present customer stories from an extensive catalog of reference demos, and provide personalized guidance for moving generative AI applications into production.
We use various AWS services to deploy a complete solution that you can use to interact with an API providing real-time weather information. In this post, we present a streamlined approach to deploying an AI-powered agent by combining Amazon Bedrock Agents and a foundation model (FM). In this solution, we use Amazon Bedrock Agents.
During these live events, F1 IT engineers must triage critical issues across its services, such as network degradation to one of its APIs. This impacts downstream services that consume data from the API, including products such as F1 TV, which offer live and on-demand coverage of every race as well as real-time telemetry.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon via a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Here are some examples of these metrics: Retrieval component Context precision Evaluates whether all of the ground-truth relevant items present in the contexts are ranked higher or not. Evaluate RAG components with Foundation models We can also use a Foundation Model as a judge to compute various metrics for both retrieval and generation.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a unified API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
At the core of the Aetion Evidence Platform (AEP) are Measureslogical building blocks used to flexibly capture complex patient variables, enabling scientists to customize their analyses to address the nuances and challenges presented by their research questions. The following diagram illustrates the solution architecture.
However, the journey from production-ready solutions to full-scale implementation can present distinct operational and technical considerations. For more information, you can watch the AWS Summit Milan 2024 presentation. This allowed them to quickly move their API-based backend services to a cloud-native environment.
Refer to Getting started with the API to set up your environment to make Amazon Bedrock requests through the AWS API. Test the code using the native inference API for Anthropics Claude The following code uses the native inference API to send a text message to Anthropics Claude. client = boto3.client("bedrock-runtime",
The Amazon Bedrock API returns the output Q&A JSON file to the Lambda function. The container image sends the REST API request to Amazon API Gateway (using the GET method). API Gateway communicates with the TakeExamFn Lambda function as a proxy. The JSON file is returned to API Gateway.
However, combining keyword search and semantic search presents significant complexity because different query types provide scores on different scales. Send the text, images, and metadata to Amazon Bedrock using its API to generate embeddings using the Amazon Titan Multimodal Embeddings G1 model.
Additionally, Q Business conversation APIs employ a layer of privacy protection by leveraging trusted identity propagation enabled by IAM Identity Center. Amazon Q Business comes with rich API support to perform administrative tasks or to build an AI-assistant with customized user experience for your enterprise.
In the architecture shown in the following diagram, users input text in the React -based web app, which triggers Amazon API Gateway , which in turn invokes an AWS Lambda function depending on the bias in the user text. Additionally, it highlights the specific parts of your input text related to each category of bias.
Next, we present the solution architecture and process flows for machine learning (ML) model building, deployment, and inferencing. Regarding the inference, customers using Amazon Ads now have a new API to receive these generated images. The Amazon API Gateway receives the PUT request (step 1). We end with lessons learned.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content