This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
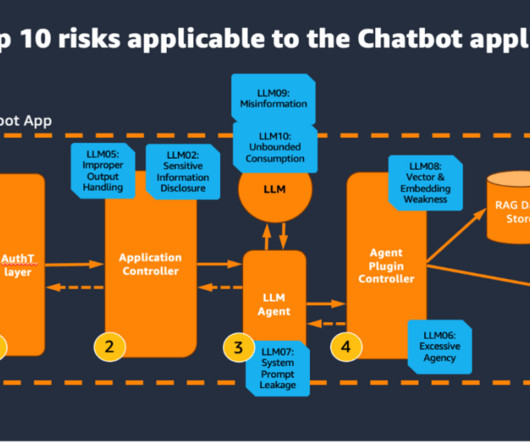
The custom Google Chat app, configured for HTTP integration, sends an HTTP request to an API Gateway endpoint. Before processing the request, a Lambda authorizer function associated with the API Gateway authenticates the incoming message. The following figure illustrates the high-level design of the solution.
This innovative feature empowers viewers to catch up with what is being presented, making it simpler to grasp key points and highlights, even if they have missed portions of the live stream or find it challenging to follow complex discussions. To launch the solution in a different Region, change the aws_region parameter accordingly.
Enterprise-scale data presents specific challenges for NL2SQL, including the following: Complex schemas optimized for storage (and not retrieval) Enterprise databases are often distributed in nature and optimized for storage and not for retrieval. Depending on the use case, this can be a static or dynamically generated script.
These steps might involve both the use of an LLM and external data sources and APIs. Agent plugin controller This component is responsible for the API integration to external data sources and APIs. The LLM agent is an orchestrator of a set of steps that might be necessary to complete the desired request.
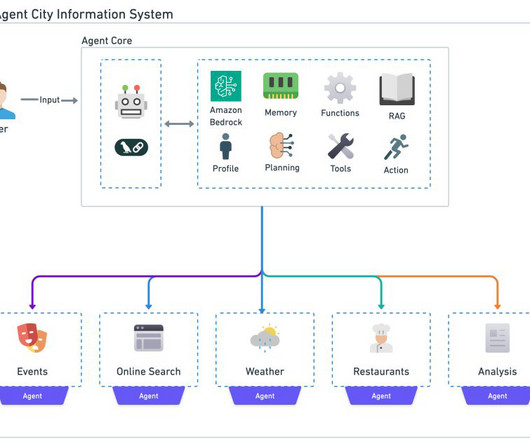
By using the power of LLMs and combining them with specialized tools and APIs, agents can tackle complex, multistep tasks that were previously beyond the reach of traditional AI systems. Whenever local database information is unavailable, it triggers an online search using the Tavily API. Its used by the weather_agent() function.
Customers can use the SageMaker Studio UI or APIs to specify the SageMaker Model Registry model to be shared and grant access to specific AWS accounts or to everyone in the organization. We will start by using the SageMaker Studio UI and then by using APIs.
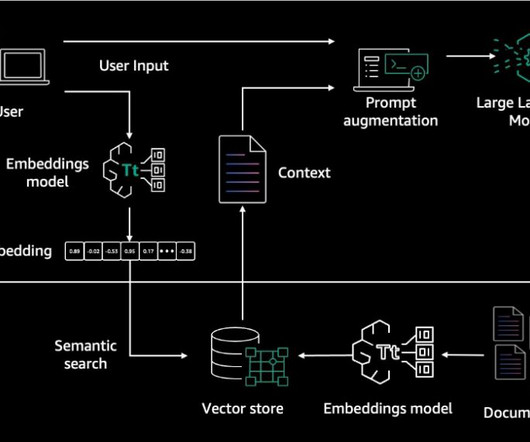
The rapid advancement of generative AI promises transformative innovation, yet it also presents significant challenges. For early detection, implement custom testing scripts that run toxicity evaluations on new data and model outputs continuously. Amazon Bedrock Knowledge Bases manages the end-to-end RAG workflow for you.
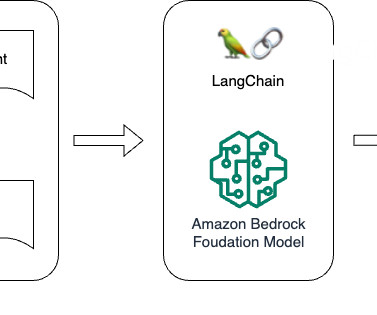
Amazon Bedrock agents use LLMs to break down tasks, interact dynamically with users, run actions through API calls, and augment knowledge using Amazon Bedrock Knowledge Bases. In this post, we demonstrate how to use Amazon Bedrock Agents with a web search API to integrate dynamic web content in your generative AI application.
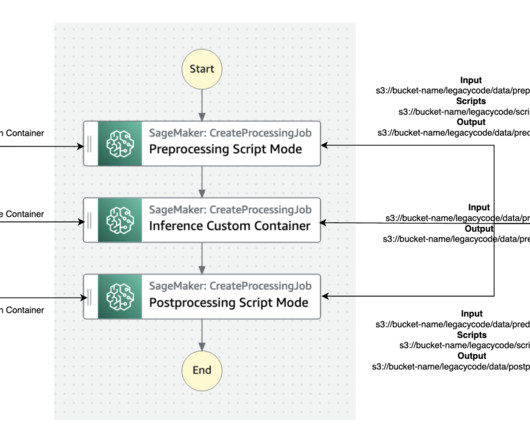
The best practice for migration is to refactor these legacy codes using the Amazon SageMaker API or the SageMaker Python SDK. SageMaker runs the legacy script inside a processing container. Step Functions is a serverless workflow service that can control SageMaker APIs directly through the use of the Amazon States Language.
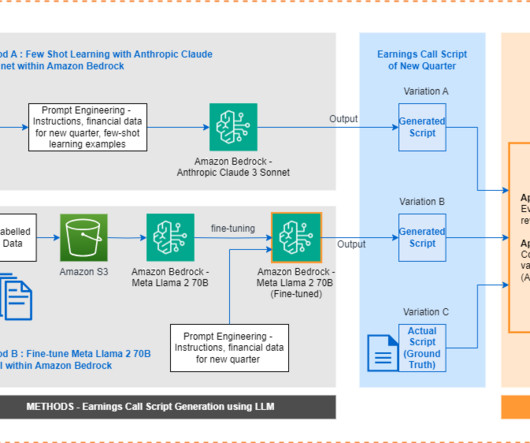
Earnings calls are live conferences where executives present an overview of results, discuss achievements and challenges, and provide guidance for upcoming periods. Traditionally, earnings call scripts have followed similar templates, making it a repeatable task to generate them from scratch each time.
The first allows you to run a Python script from any server or instance including a Jupyter notebook; this is the quickest way to get started. In the following sections, we first describe the script solution, followed by the AWS CDK construct solution. The following diagram illustrates the sequence of events within the script.
The retrieve_and_generate API does both the retrieval and a call to an FM (Amazon Titan or Anthropic’s Claude family of models on Amazon Bedrock ), for a fully managed solution. When the quotation-checking function fails to find a quotation in the documents, it means only that the quotation isn’t present verbatim in the text.
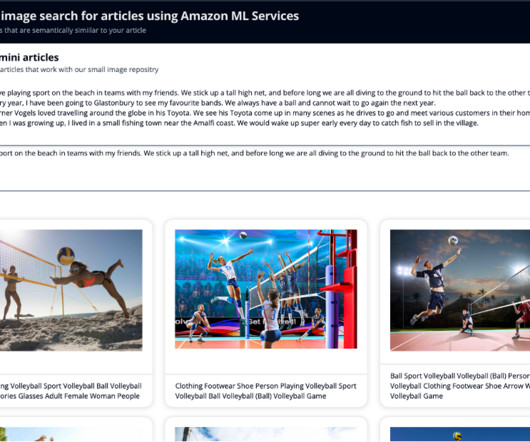
You then perform a search against OpenSearch Service with the names and the embedding from the article to retrieve images that are semantically similar with the presence of the given celebrity, if present. The result from the multimodal model scores the images with a scarf present higher.
Amazon Rekognition makes it easy to add image analysis capability to your applications without any machine learning (ML) expertise and comes with various APIs to fulfil use cases such as object detection, content moderation, face detection and analysis, and text and celebrity recognition, which we use in this example.
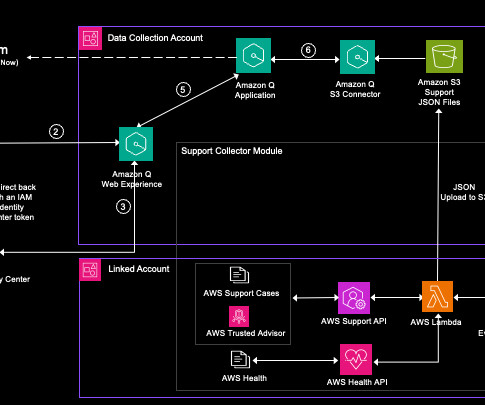
In this post, we’re using the APIs for AWS Support , AWS Trusted Advisor , and AWS Health to programmatically access the support datasets and use the Amazon Q Business native Amazon Simple Storage Service (Amazon S3) connector to index support data and provide a prebuilt chatbot web experience. Synchronize the data source to index the data.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API. The scripts for fine-tuning and evaluation are available on the GitHub repository.
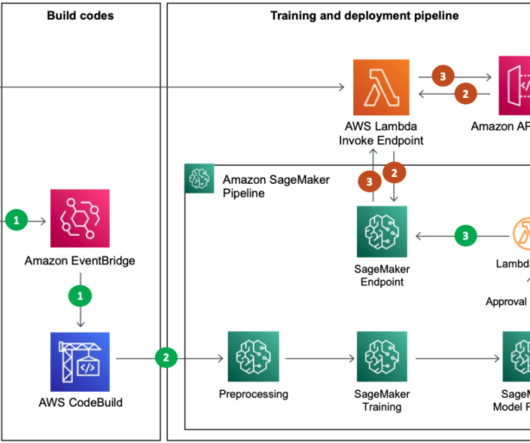
The main AWS services used are SageMaker, Amazon EMR , AWS CodeBuild , Amazon Simple Storage Service (Amazon S3), Amazon EventBridge , AWS Lambda , and Amazon API Gateway. Real-time recommendation inference The inference phase consists of the following steps: The client application makes an inference request to the API gateway.
Refer to Getting started with the API to set up your environment to make Amazon Bedrock requests through the AWS API. Test the code using the native inference API for Anthropics Claude The following code uses the native inference API to send a text message to Anthropics Claude. client = boto3.client("bedrock-runtime",
Chatbots also offer valuable data-driven insights into customer behavior while scaling effortlessly as the user base grows; therefore, they present a cost-effective solution for engaging customers. Clone the GitHub repo The solution presented in this post is available in the following GitHub repo. model in Amazon Bedrock.
Streamline content creation – Amazon Q can assist in generating drafts, outlines, and even complete content pieces (such as reports, articles, or presentations) by drawing on the knowledge and data stored in SharePoint. Any additional mappings need to be set in the user store using the user store APIs.
You can fine-tune and deploy JumpStart models using the UI in Amazon SageMaker Studio or using the SageMaker Python SDK extension for JumpStart APIs. This post focuses on how we can implement MLOps with JumpStart models using JumpStart APIs, Amazon SageMaker Pipelines , and Amazon SageMaker Projects. sm_client = boto3.client("sagemaker")
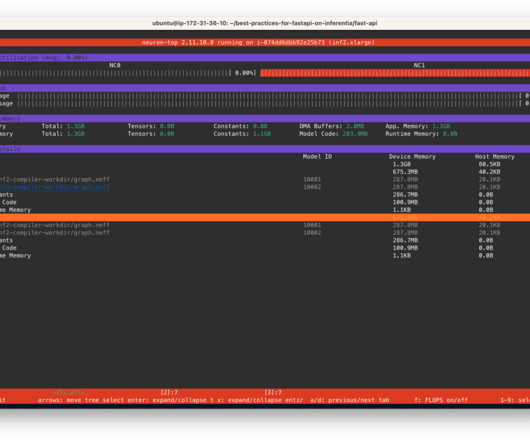
If the model changes on the server side, the client has to know and change its API call to the new endpoint accordingly. Clone the Github repository The GitHub repo provides all the scripts necessary to deploy models using FastAPI on NeuronCores on AWS Inferentia instances. code as the entry point. compiled-model-bs-{batch_size}.pt')
Continuous integration and continuous delivery (CI/CD) pipeline – Using the customer’s GitHub repository enabled code versioning and automated scripts to launch pipeline deployment whenever new versions of the code are committed. Wipro has used the input filter and join functionality of SageMaker batch transformation API.
Instead of presenting each facet individually as a list, hierarchical facets enable defining a parent-child relationship between facets to shape the scope of the search results. If you just want to read about this feature without running it yourself, you can refer to the Python script facet-search-query.py Solution overview.
JumpStart APIs allow you to programmatically deploy and fine-tune a vast selection of JumpStart-supported pre-trained models on your own datasets. In this post, we present a methodology to easily run multiple models and compare their outputs on three dimensions of interest: model accuracy, training time, and inference time.
We explore two ways of obtaining the same result: via JumpStart’s graphical interface on Amazon SageMaker Studio , and programmatically through JumpStart APIs. If you want to jump straight into the JumpStart API code we go through in this post, you can refer to the following sample Jupyter notebook: Introduction to JumpStart – Text to Image.
Retrieval Augmented Generation (RAG) is a popular paradigm that provides additional knowledge to large language models (LLMs) from an external source of data that wasn’t present in their training corpus. Python script that serves as the entry point. expand(token_embeddings.size()).float() tolist()} After creating the inference.py
In this post, we present a comprehensive guide on deploying and running inference using the Stable Diffusion inpainting model in two methods: through JumpStart’s user interface (UI) in Amazon SageMaker Studio , and programmatically through JumpStart APIs available in the SageMaker Python SDK.
We explore two ways of obtaining the same result: via JumpStart’s graphical interface on Amazon SageMaker Studio , and programmatically through JumpStart APIs. The following sections provide a step-by-step demo to perform inference, both via the Studio UI and via JumpStart APIs. JumpStart overview. Solution overview.
We explore two ways of obtaining the same result: via JumpStart’s graphical interface on Amazon SageMaker Studio , and programmatically through JumpStart APIs. The following sections provide a step-by-step demo to perform semantic segmentation with JumpStart, both via the Studio UI and via JumpStart APIs. Solution overview.
In this post, we provide an overview of how to deploy and run inference with the Stable Diffusion upscaler model in two ways: via JumpStart’s user interface (UI) in Amazon SageMaker Studio , and programmatically through JumpStart APIs available in the SageMaker Python SDK.
The solution also uses Amazon Bedrock , a fully managed service that makes foundation models (FMs) from Amazon and third-party model providers accessible through the AWS Management Console and APIs. For this post, we use the Amazon Bedrock API via the AWS SDK for Python. The script instantiates the Amazon Bedrock client using Boto3.
The SageMakerMigration class consists of high-level abstractions over SageMaker APIs that significantly reduce the steps needed to deploy your model to SageMaker, as illustrated in the following figure. Prepare your trained model and inference script. pth,pkl, and so on) and an inference script.
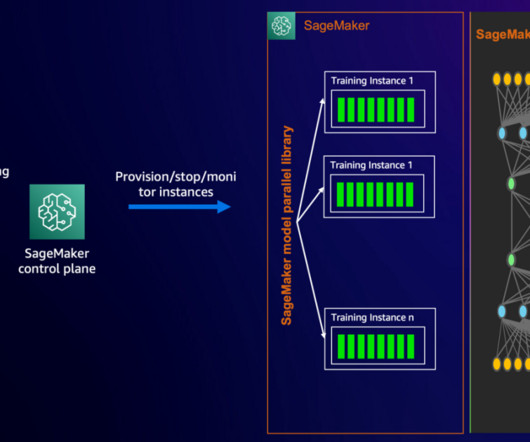
Despite their computational benefits, training and fine-tuning large MoE models efficiently presents some challenges. The SMP library uses NVIDIA Megatron to implement expert parallelism and support training MoE models, and runs on top of PyTorch Fully Sharded Data Parallel (FSDP) APIs. In this example, we use SageMaker training jobs.
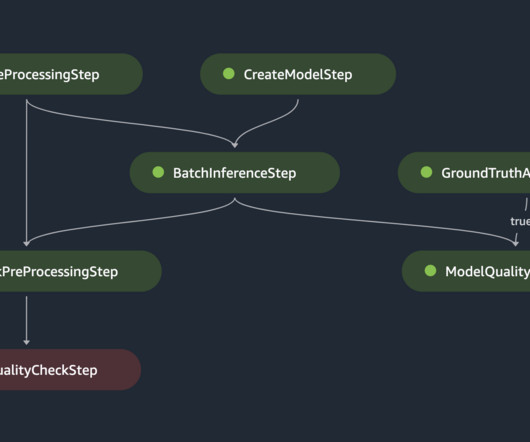
The presented MLOps workflow provides a reusable template for managing the ML lifecycle through automation, monitoring, auditability, and scalability, thereby reducing the complexities and costs of maintaining batch inference workloads in production.
In this post, we provide an overview of how to fine-tune the Stable Diffusion model in two ways: programmatically through JumpStart APIs available in the SageMaker Python SDK , and JumpStart’s user interface (UI) in Amazon SageMaker Studio. Fine-tuning large models like Stable Diffusion usually requires you to provide training scripts.
Users can also interact with data with ODBC, JDBC, or the Amazon Redshift Data API. However, working with data in the cloud can present challenges, such as the need to remove organizational data silos, maintain security and compliance, and reduce complexity by standardizing tooling. Solution overview.
For data scientists, moving machine learning (ML) models from proof of concept to production often presents a significant challenge. FastAPI is a modern, high-performance web framework for building APIs with Python. It can be cumbersome to manage the process, but with the right tool, you can significantly reduce the required effort.
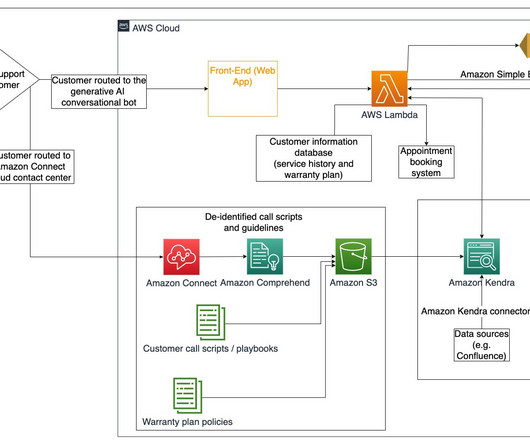
Amazon API Gateway hosts a REST API with various endpoints to handle user requests that are authenticated using Amazon Cognito. The service analyzes the text and identifies any PII entities present within the query. The web application front-end is hosted on AWS Amplify. Confluence, Microsoft SharePoint, Google Drive, Jira, etc.)
Gramener’s GeoBox solution empowers users to effortlessly tap into and analyze public geospatial data through its powerful API, enabling seamless integration into existing workflows. With the SearchRasterDataCollection API, SageMaker provides a purpose-built functionality to facilitate the retrieval of satellite imagery.
In order to run inference through SageMaker API, make sure to pass the Predictor class. pre_trained_model = Model( image_uri=deploy_image_uri, model_data=pre_trained_model_uri, role=aws_role, predictor_cls=Predictor, name=pre_trained_name, env=large_model_env, ) # Deploy the pre-trained model.
In this post, we present a solution to handle OOC situations through knowledge graph-based embedding search using the k-nearest neighbor (kNN) search capabilities of OpenSearch Service. Creates an API Gateway that adds an additional layer of security between the web app user interface and Lambda. Solution overview. from your terminal.
This notebook presents an end-to-end example of how to compile a Stable Diffusion model, save the compiled Neuron models, and load it into the runtime for inference. We compile the UNet for one batch (by using input tensors with one batch), then use the torch_neuronx.DataParallel API to load this single batch model onto each core.
Lifecycle configurations (LCCs) are shell scripts to automate customization for your Studio environments, such as installing JupyterLab extensions, preloading datasets, and setting up source code repositories. LCC scripts are triggered by Studio lifecycle events, such as starting a new Studio notebook. Apply the script (see below).
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content