This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this post, we explore how you can use Amazon Bedrock to generate high-quality categorical ground truth data, which is crucial for training machine learning (ML) models in a cost-sensitive environment. This results in an imbalanced class distribution for training and test datasets.
Customers can use the SageMaker Studio UI or APIs to specify the SageMaker Model Registry model to be shared and grant access to specific AWS accounts or to everyone in the organization. We will start by using the SageMaker Studio UI and then by using APIs.
Recent advances in generative AI have led to the rapid evolution of natural language to SQL (NL2SQL) technology, which uses pre-trained large language models (LLMs) and natural language to generate database queries in the moment. Depending on the use case, this can be a static or dynamically generated script.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Contrast that with Scope 4/5 applications, where not only do you build and secure the generative AI application yourself, but you are also responsible for fine-tuning and training the underlying large language model (LLM). These steps might involve both the use of an LLM and external data sources and APIs.
This allowed Intact to transcribe customer calls accurately, train custom language models, simplify the call auditing process, and extract valuable customer insights more efficiently. The goal was to refine customer service scripts, provide coaching opportunities for agents, and improve call handling processes.
By utilizing sparse expert subnetworks that process different subsets of tokens, MoE models can effectively increase the number of parameters while requiring less computation per token during training and inference. This enables more cost-effective training of larger models within fixed compute budgets compared to dense architectures.
In this blog post and open source project , we show you how you can pre-train a genomics language model, HyenaDNA , using your genomic data in the AWS Cloud. Amazon SageMaker Amazon SageMaker is a fully managed ML service offered by AWS, designed to reduce the time and cost associated with training and tuning ML models at scale.
Amazon SageMaker JumpStart is the machine learning (ML) hub of SageMaker that offers over 350 built-in algorithms, pre-trained models, and pre-built solution templates to help you get started with ML fast. Perform the training step to fine-tune the pre-trained model using transfer learning. Create the model. Register the model.
Organizations typically counter these hurdles by investing in extensive training programs or hiring specialized personnel, which often leads to increased costs and delayed migration timelines. Traditionally, cloud engineers learning IaC would manually sift through documentation and best practices to write compliant IaC scripts.
Today, a lot of customers are using TensorFlow to train deep learning models for their clickthrough rate in advertising and personalization recommendations in ecommerce. Model iteration is one of a data scientist’s daily jobs, but they face the problem of taking too long to train on large datasets. Automatic mixed precision training.
Key features include: Signed Business Associate Agreement (BAA) Secure data storage Role-based access to patient data Regular staff training on HIPAA policies Ask prospective call center partners: What safeguards are in place to protect patient data? How often do you perform security audits? Do you offer client-specific performance reviews?
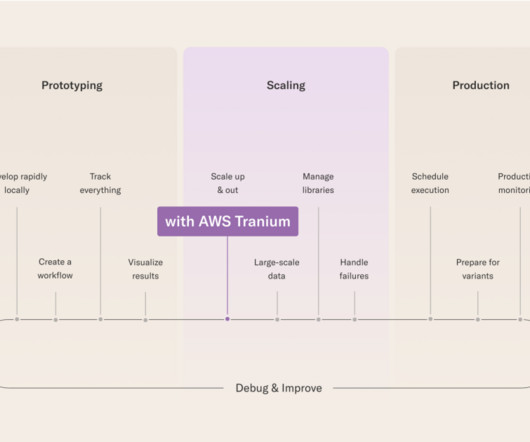
This often means the method of using a third-party LLM API won’t do for security, control, and scale reasons. First, the AWS Trainium accelerator provides a high-performance, cost-effective, and readily available solution for training and fine-tuning large models. The following figure illustrates this workflow.
In recent years, large language models (LLMs) have gained attention for their effectiveness, leading various industries to adapt general LLMs to their data for improved results, making efficient training and hardware availability crucial. In this post, we show you how efficient we make our continual pre-training by using Trainium chips.
This text-to-video API generates high-quality, realistic videos quickly from text and images. Trained on the Amazon SageMaker HyperPod , Dream Machine excels in creating consistent characters, smooth motion, and dynamic camera movements. Luma AI’s recently launched Dream Machine represents a significant advancement in this field.
Language Support : Chat GPT can be trained in multiple languages, enabling contact centers to provide support to customers globally without the need for multilingual agents. In the end, writing scripts, using it for marketing or content and other simple tasks appear to be the main use cases right now.” says Fred.
Look for a service that has: Encrypted data storage Secure call recording Staff trained in handling PHI (Protected Health Information) Internal audits and compliance reporting 3. Trained Medical Receptionists and Agents Your patients should be speaking with knowledgeable and compassionate representatives.
Pre-trained models and fully managed NLP services have democratised access and adoption of NLP. Amazon SageMaker is a fully managed service that provides developers and data scientists the ability to build, train, and deploy machine learning (ML) models quickly. Build your trainingscript for the Hugging Face SageMaker estimator.
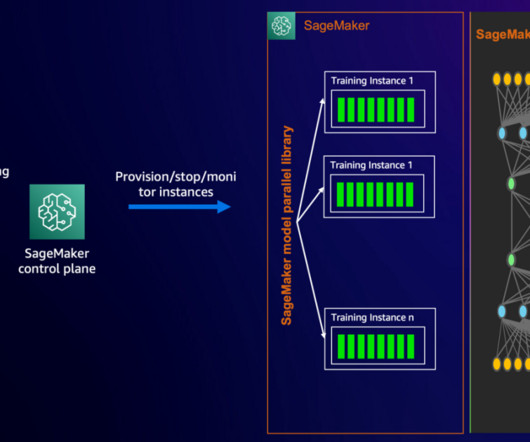
Amazon SageMaker is a fully-managed service for ML, and SageMaker model training is an optimized compute environment for high-performance training at scale. SageMaker model training offers a remote training experience with a seamless control plane to easily train and reproduce ML models at high performance and low cost.
Large language model (LLM) training has surged in popularity over the last year with the release of several popular models such as Llama 2, Falcon, and Mistral. Training performant models at this scale can be a challenge. These features improve the usability of the library, expand functionality, and accelerate training.
Many use cases involve using pre-trained large language models (LLMs) through approaches like Retrieval Augmented Generation (RAG). Fine-tuning is a supervised training process where labeled prompt and response pairs are used to further train a pre-trained model to improve its performance for a particular use case.
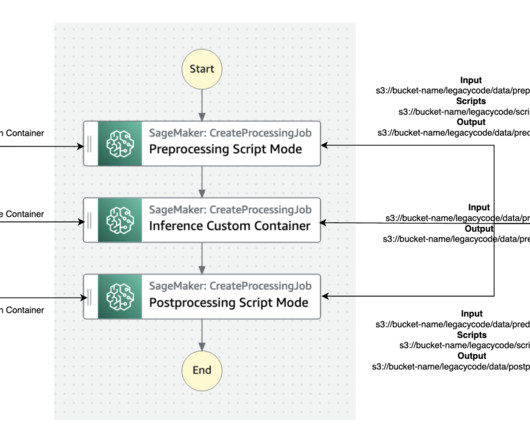
The best practice for migration is to refactor these legacy codes using the Amazon SageMaker API or the SageMaker Python SDK. SageMaker runs the legacy script inside a processing container. Step Functions is a serverless workflow service that can control SageMaker APIs directly through the use of the Amazon States Language.
SageMaker JumpStart provides one-click fine-tuning and deployment of a wide variety of pre-trained models across popular ML tasks, as well as a selection of end-to-end solutions that solve common business problems. In this post, we’re excited to announce that all trainable JumpStart models now support incremental training.
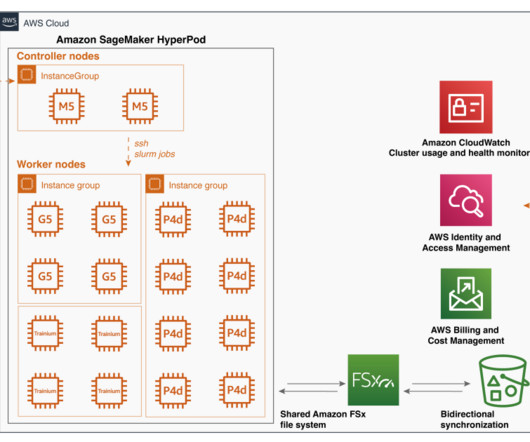
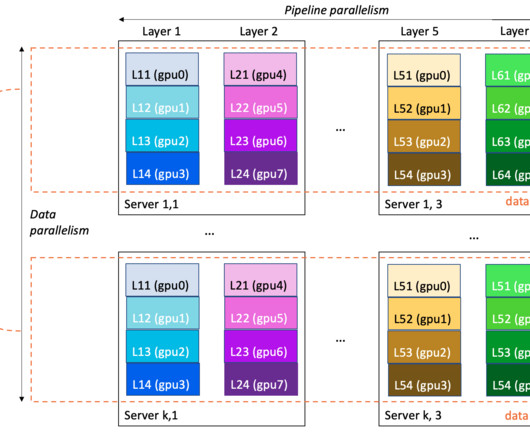
Modern model pre-training often calls for larger cluster deployment to reduce time and cost. At the server level, such training workloads demand faster compute and increased memory allocation. As models grow to hundreds of billions of parameters, they require a distributed training mechanism that spans multiple nodes (instances).
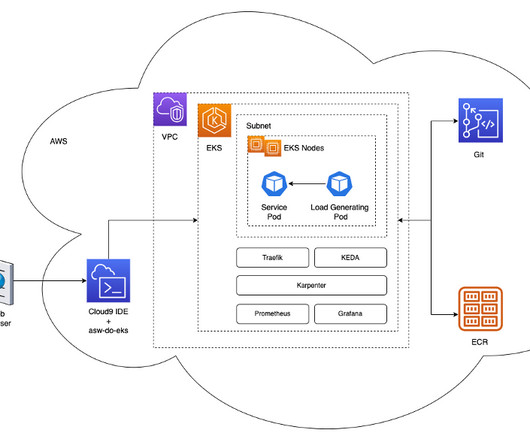
In this post, we focus on how we used Karpenter on Amazon Elastic Kubernetes Service (Amazon EKS) to scale AI training and inference, which are core elements of the Iambic discovery platform. We wanted to build a scalable system to support AI training and inference. The service is exposed behind a reverse-proxy using Traefik.
Distributed deep learning model training is becoming increasingly important as data sizes are growing in many industries. Many applications in computer vision and natural language processing now require training of deep learning models, which are growing exponentially in complexity and are often trained with hundreds of terabytes of data.
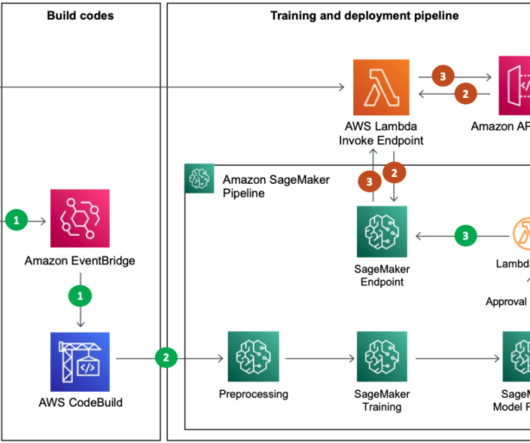
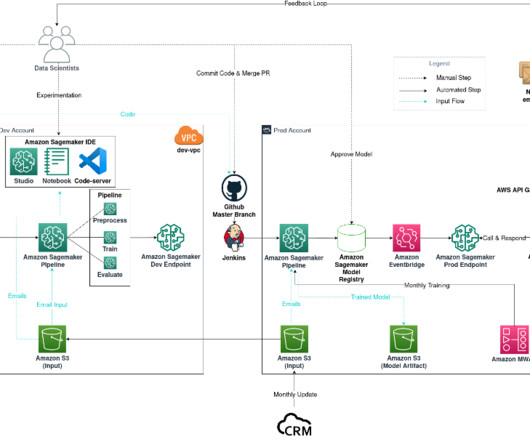
The main AWS services used are SageMaker, Amazon EMR , AWS CodeBuild , Amazon Simple Storage Service (Amazon S3), Amazon EventBridge , AWS Lambda , and Amazon API Gateway. The SageMaker pipeline predefined in CodeBuild runs, and sequentially runs steps such as preprocessing including provisioning, model training, and model registration.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API. The scripts for fine-tuning and evaluation are available on the GitHub repository.
Large language models (LLMs) are neural network-based language models with hundreds of millions ( BERT ) to over a trillion parameters ( MiCS ), and whose size makes single-GPU training impractical. The size of an LLM and its training data is a double-edged sword: it brings modeling quality, but entails infrastructure challenges.
If you’re a Zendesk user in a Contact Center environment, you’ll want to be using our Zendesk Agent Scripting app. This makes it easy to guide, train and onboard agents and is a huge productivity booster for everyone. This two-minute video shows you how Agents interact with the Agent Scripting App: Getting Started.
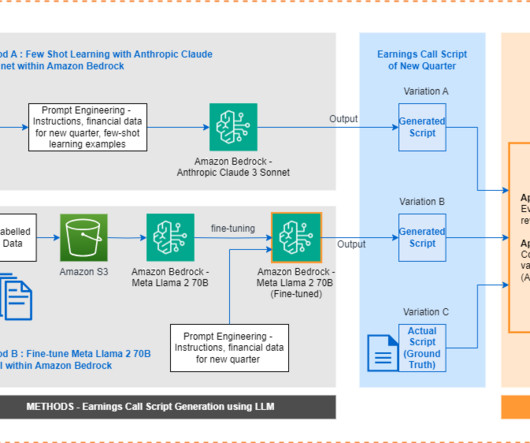
Traditionally, earnings call scripts have followed similar templates, making it a repeatable task to generate them from scratch each time. On the other hand, generative artificial intelligence (AI) models can learn these templates and produce coherent scripts when fed with quarterly financial data.
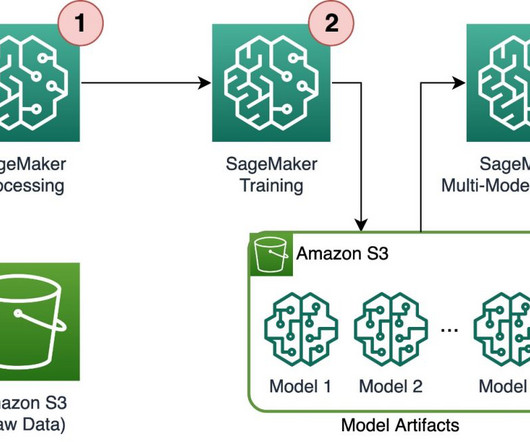
As machine learning (ML) becomes increasingly prevalent in a wide range of industries, organizations are finding the need to train and serve large numbers of ML models to meet the diverse needs of their customers. Training and serving thousands of models requires a robust and scalable infrastructure, which is where Amazon SageMaker can help.
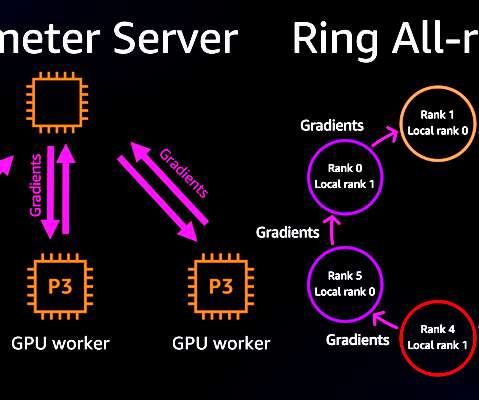
Training these gigantic models is challenging and requires complex distribution strategies. Data scientists and machine learning engineers are constantly looking for the best way to optimize their training compute, yet are struggling with the communication overhead that can increase along with the overall cluster size. on 256 GPUs.
You can also either use the SageMaker Canvas UI, which provides a visual interface for building and deploying models without needing to write any code or have any ML expertise, or use its automated machine learning (AutoML) APIs for programmatic interactions.
Certain machine learning (ML) workloads, such as training computer vision models or reinforcement learning, often involve combining the GPU- or accelerator-intensive task of neural network model training with the CPU-intensive task of data preprocessing, like image augmentation. This post is co-written with Chaim Rand from Mobileye.
The plentiful and jointly trained parameters of DL models have a large representational capacity that brought improvements in numerous customer use cases, including image and speech analysis, natural language processing (NLP), time series processing, and more. The challenge with DL training.
If you’re a Zendesk user in a Contact Center environment, you’ll want to be using our Zendesk Agent Scripting app. This makes it easy to guide, train and onboard agents and is a huge productivity booster for everyone. Benefits of the Zendesk Agent Scripting App. Installing the Agent Scripting App into Zendesk.
With the increasing use of artificial intelligence (AI) and machine learning (ML) for a vast majority of industries (ranging from healthcare to insurance, from manufacturing to marketing), the primary focus shifts to efficiency when building and training models at scale. The steps are as follows: Open AWS Cloud9 on the console.
The data scientists in this team use Amazon SageMaker to build and train a credit risk prediction model using the shared credit risk data product from the consumer banking LoB. Build and train ML models using a data mesh architecture on AWS. Part 1: Data mesh set up and data product registration. Data exploration.
The first allows you to run a Python script from any server or instance including a Jupyter notebook; this is the quickest way to get started. In the following sections, we first describe the script solution, followed by the AWS CDK construct solution. The following diagram illustrates the sequence of events within the script.
The AWS portfolio of ML services includes a robust set of services that you can use to accelerate the development, training, and deployment of machine learning applications. Collaboration – Data scientists each worked on their own local Jupyter notebooks to create and train ML models.
However, training these gigantic networks from scratch requires a tremendous amount of data and compute. For smaller NLP datasets, a simple yet effective strategy is to use a pre-trained transformer, usually trained in an unsupervised fashion on very large datasets, and fine-tune it on the dataset of interest. trainingscript.
In this post, we share how Games24x7 improved their training pipelines for their responsible gaming platform using Amazon SageMaker. This step-function instantiated a cluster of instances to extract and process data from S3 and the further steps of pre-processing, training, evaluation would run on a single large EC2 instance.
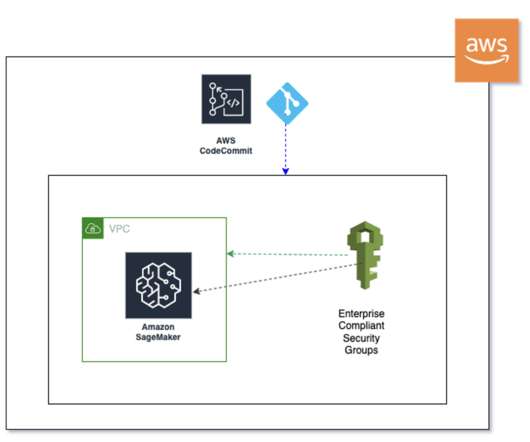
In this post, we demonstrate the technical benefits of using Hugging Face transformers deployed with Amazon SageMaker , such as training and experimentation at scale, and increased productivity and cost-efficiency. This merge event now triggers a SageMaker Pipelines job using production data for training purposes.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.







































Let's personalize your content