This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
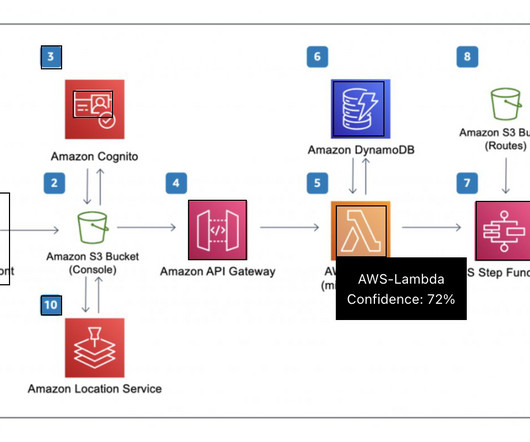
The solution also uses Amazon Cognito user pools and identity pools for managing authentication and authorization of users, Amazon API Gateway REST APIs, AWS Lambda functions, and an Amazon Simple Storage Service (Amazon S3) bucket. To launch the solution in a different Region, change the aws_region parameter accordingly.
The Amazon Nova family of models includes Amazon Nova Micro, Amazon Nova Lite, and Amazon Nova Pro, which support text, image, and video inputs while generating text-based outputs. Amazon Bedrock APIs make it straightforward to use Amazon Titan Text Embeddings V2 for embedding data. get("message", {}).get("content")
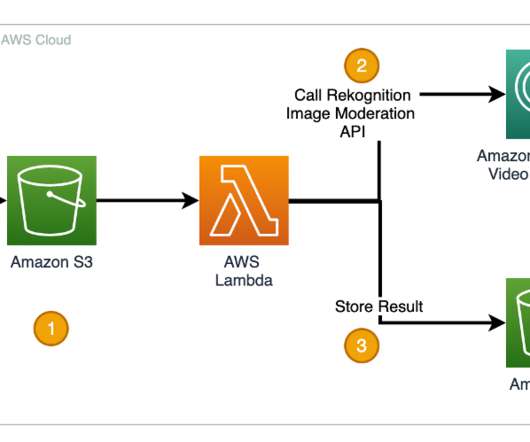
In a recent survey, 79% of consumers stated they rely on user videos, comments, and reviews more than ever and 78% of them said that brands are responsible for moderating such content. Amazon Rekognition has two sets of APIs that help you moderate images or videos to keep digital communities safe and engaged.
Video generation has become the latest frontier in AI research, following the success of text-to-image models. This text-to-videoAPI generates high-quality, realistic videos quickly from text and images. Luma AI’s recently launched Dream Machine represents a significant advancement in this field.
Video dubbing, or content localization, is the process of replacing the original spoken language in a video with another language while synchronizing audio and video. Video dubbing has emerged as a key tool in breaking down linguistic barriers, enhancing viewer engagement, and expanding market reach.
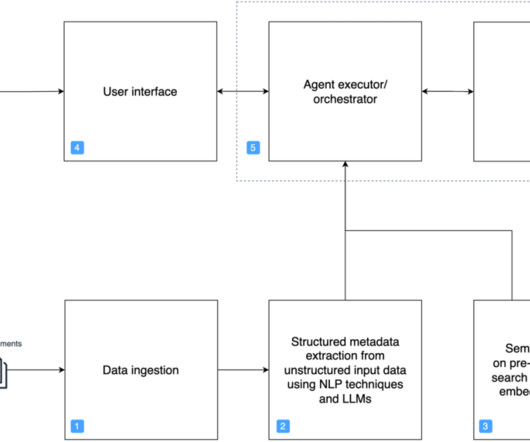
Amazon Bedrock agents use LLMs to break down tasks, interact dynamically with users, run actions through API calls, and augment knowledge using Amazon Bedrock Knowledge Bases. In this post, we demonstrate how to use Amazon Bedrock Agents with a web search API to integrate dynamic web content in your generative AI application.
If you’re a Zendesk user in a Contact Center environment, you’ll want to be using our Zendesk Agent Scripting app. Pause and Resume: If a ticket is transferred, the supervisor or new agent is taken to the last place in the script, and can see the history of the previous steps taken. Demo Video.
If you’re a Zendesk user in a Contact Center environment, you’ll want to be using our Zendesk Agent Scripting app. Benefits of the Zendesk Agent Scripting App. Demo Video. Installing the Agent Scripting App into Zendesk. Installing the Agent Scripting App into Zendesk. Contents of this Article.
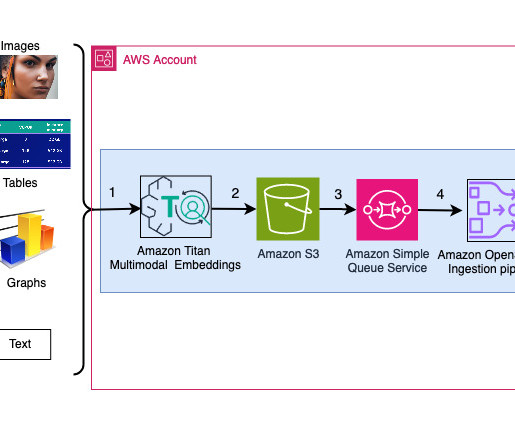
Multimodal models can understand and analyze data in multiple modalities such as text, image, video, and audio. Amazon Rekognition automatically recognizes tens of thousands of well-known personalities in images and videos using ML. Amazon Titan has recently added a new embedding model to its collection, Titan Multimodal Embeddings.
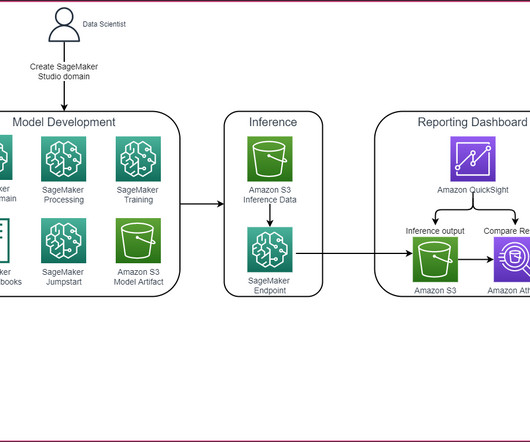
We explore two ways of obtaining the same result: via JumpStart’s graphical interface on Amazon SageMaker Studio , and programmatically through JumpStart APIs. If you want to jump straight into the JumpStart API code we go through in this post, you can refer to the following sample Jupyter notebook: Introduction to JumpStart – Text to Image.
And testingRTC offers multiple ways to export these metrics, from direct collection from webhooks, to downloading results in CSV format using the REST API. It also shows an aggregation graph underneath showing information for both voice and video performance. You can check framerate information for video here too. Happy days!
We explore two ways of obtaining the same result: via JumpStart’s graphical interface on Amazon SageMaker Studio , and programmatically through JumpStart APIs. Review training videos and blogs – JumpStart also provides numerous blog posts and videos that teach you how to use different functionalities within SageMaker.
We explore two ways of obtaining the same result: via JumpStart’s graphical interface on Amazon SageMaker Studio , and programmatically through JumpStart APIs. Review training videos and blogs – JumpStart also provides numerous blog posts and videos that teach you how to use different functionalities within SageMaker.
Have you ever inadvertently searched a content title that wasn’t available in a video streaming platform? This event frequently occurs in video streaming platforms that constantly purchase a variety of content from multiple vendors and production companies for a limited time. Background. That’s an out-of-catalog search experience!
Amazon Rekognition supports adding image and video analysis to your applications. To recap how the solution works Traffic intersection video footage is uploaded to your SageMaker environment from an external device. A Python function uses CV2 to split the video footage into image frames. See the following figure.
This real-time accessibility ensures that customers can receive assistance they immediately understand through images or video. They say that images (and videos) are worth a thousand words. Furthermore, TechSee’s technology can be integrated anywhere through APIs or SDKs. Already have a mobile app?
This real-time accessibility ensures that customers can receive assistance they immediately understand through images or video. They say that images (and videos) are worth a thousand words. Furthermore, TechSee’s technology can be integrated anywhere through APIs or SDKs. Already have a mobile app?
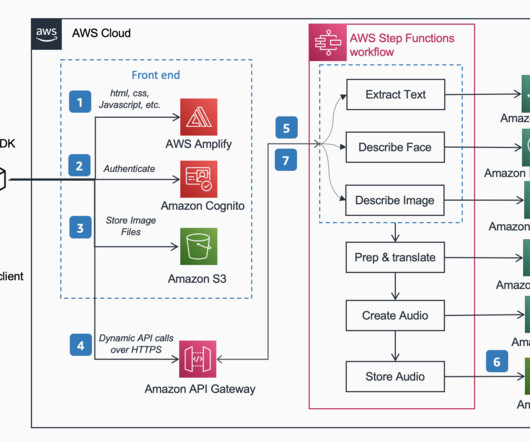
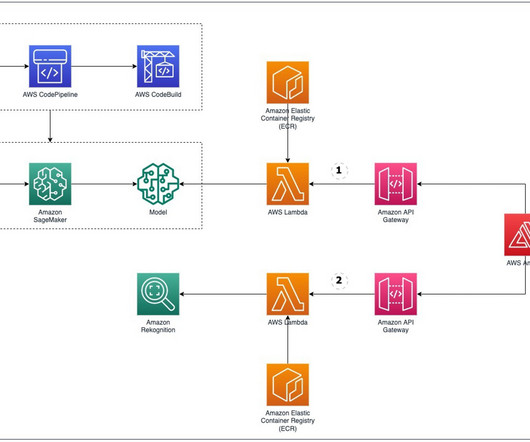
Amazon API Gateway hosts a REST API with various endpoints to handle user requests that are authenticated using Amazon Cognito. Finally, the response is sent back to the user via a HTTPs request through the Amazon API Gateway REST API integration response. The web application front-end is hosted on AWS Amplify.
Applications and services can call the deployed endpoint directly or through a deployed serverless Amazon API Gateway architecture. To learn more about real-time endpoint architectural best practices, refer to Creating a machine learning-powered REST API with Amazon API Gateway mapping templates and Amazon SageMaker.
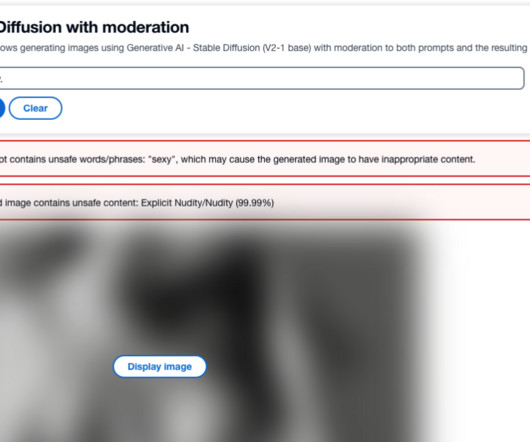
In this post, we present a comprehensive guide on deploying and running inference using the Stable Diffusion inpainting model in two methods: through JumpStart’s user interface (UI) in Amazon SageMaker Studio , and programmatically through JumpStart APIs available in the SageMaker Python SDK.
Amazon API Gateway with AWS Lambda integration that converts the input text to the target language using the Amazon Translate SDK. The following steps set up API Gateway, Lambda, and Amazon Translate resources using the AWS CDK. Take note of the API key and the API endpoint created during the deployment. Prerequisites.
Solution overview Amazon Rekognition and Amazon Comprehend are managed AI services that provide pre-trained and customizable ML models via an API interface, eliminating the need for machine learning (ML) expertise. Amazon Rekognition Content Moderation automates and streamlines image and video moderation.
Amazon Kendra is an intelligent search service powered by ML, and Amazon Rekognition is an ML service that can identify objects, people, text, scenes, and activities from images or videos. The first aspect is performed by Amazon Rekognition, which can identify objects, people, text, scenes, and activities from images or videos.
The DescribeForMe web app invokes the backend AI services by sending the Amazon S3 object Key in the payload to Amazon API Gateway Amazon API Gateway instantiates an AWS Step Functions workflow. A pre-signed URL with the location of the audio file stored in Amazon S3 is sent back to the user’s browser through Amazon API Gateway.
Recently, we also announced the launch of easy-to-use JumpStart APIs as an extension of the SageMaker Python SDK, allowing you to programmatically deploy and fine-tune a vast selection of JumpStart-supported pre-trained models on your own datasets. JumpStart overview. The dataset has been downloaded from TensorFlow. Walkthrough overview.
To solve this problem, we propose the use of generative AI, a type of AI that can create new content and ideas, including conversations, stories, images, videos, and music. In order to run inference through SageMaker API, make sure to pass the Predictor class. from sagemaker import image_uris # Retrieve the inference docker image URI.
This solution uses an Amazon Cognito user pool as an OAuth-compatible identity provider (IdP), which is required in order to exchange a token with AWS IAM Identity Center and later on interact with the Amazon Q Business APIs. Amazon Q uses the chat_sync API to carry out the conversation. You can also find the script on the GitHub repo.
Hundreds of thousands of work hours are spent generating high-quality labels from images and videos for various CV use cases. However, it can be challenging, expensive, and time-consuming to label tens of thousands of miles of recorded video and LiDAR data for companies that are in the business of creating AV/ADAS systems.
Another driver behind RAG’s popularity is its ease of implementation and the existence of mature vector search solutions, such as those offered by Amazon Kendra (see Amazon Kendra launches Retrieval API ) and Amazon OpenSearch Service (see k-Nearest Neighbor (k-NN) search in Amazon OpenSearch Service ), among others.
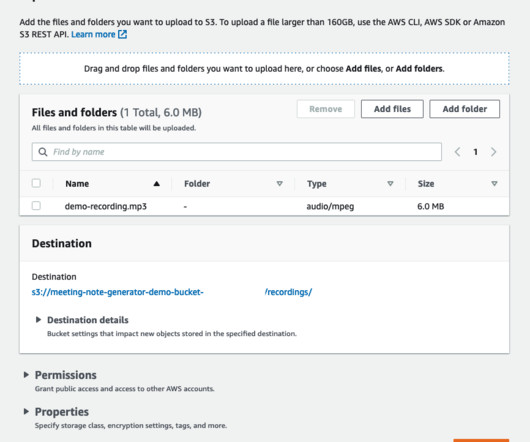
Solution overview The Meeting Notes Generator Solution creates an automated serverless pipeline using AWS Lambda for transcribing and summarizing audio and video recordings of meetings. The events trigger Lambda functions to make API calls to Amazon Transcribe and invoke the real-time endpoint hosting the Flan T5 XL model.
Although early large language models (LLMs) were limited to processing text inputs, the rapid evolution of these AI systems has enabled LLMs to expand their capabilities to handle a wide range of media types, including images, video, and audio, ushering in the era of multimodal models. script takes approximately 30 minutes to run.
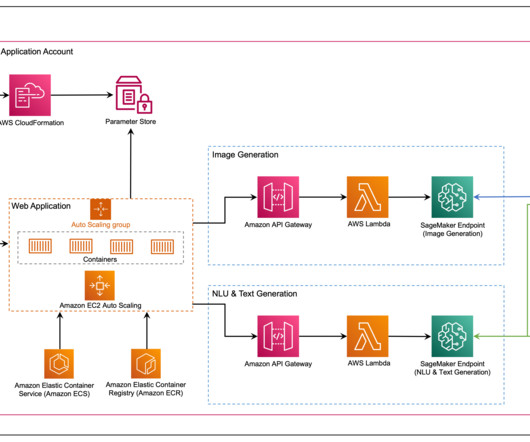
Generative AI is a type of AI that can create new content and ideas, including conversations, stories, images, videos, and music. The web application interacts with the models via Amazon API Gateway and AWS Lambda functions as shown in the following diagram. This simplifies the client application code that consumes the models.
As a JumpStart model hub customer, you get improved performance without having to maintain the model script outside of the SageMaker SDK. The inference script is prepacked with the model artifact. A short demo to showcase the JumpStartOpenChatKitShell is shown in the following video. The deploy method may take a few minutes.
In this post, we provide an overview of how to deploy and run inference with the AlexaTM 20B model programmatically through JumpStart APIs, available in the SageMaker Python SDK. To use a large language model in SageMaker, you need an inferencing script specific for the model, which includes steps like model loading, parallelization and more.
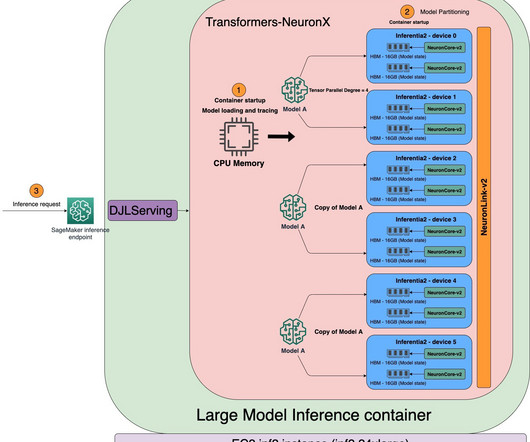
You can use ml.inf2 and ml.trn1 instances to run your ML applications on SageMaker for text summarization, code generation, video and image generation, speech recognition, personalization, fraud detection, and more. xlarge" ) Refer to Developer Flows for more details on typical development flows of Inf2 on SageMaker with sample scripts.
The JumpStart APIs allow you to programmatically deploy and fine-tune a vast selection of pre-trained models on your own datasets. In the following video, we show a walkthrough of the steps in this section. This includes all dependencies and scripts for model loading, inference handling, and more.
Imagine a surgeon taking video calls with patients across the globe without the need of a human translator. Amazon Translate: State-of-the-art, fully managed translation API. Amazon Polly: Fully managed text-to-speech API. What happens to your business when you’re no longer bound by language? Overview of solution. Conclusion.
The processing job queries the data via Athena and uses a script to split the data into training, testing, and validation datasets. Although the SageMaker Training API doesn’t include a parameter to configure an Athena data source, you can query data via Athena in the training script itself.
Today, generative AI models cover a variety of tasks from text summarization, Q&A, and image and video generation. Fine tune Falcon-7B on AWS services FAQs Now you can prepare the training script and define the training function train_fn and put @remote decorator on the function.
In addition, they use the developer-provided instruction to create an orchestration plan and then carry out the plan by invoking company APIs and accessing knowledge bases using Retrieval Augmented Generation (RAG) to provide an answer to the user’s request. In Part 1, we focus on creating accurate and reliable agents.
Complete the following steps: Download the bootstrap script from s3://emr-data-access-control- /customer-bootstrap-actions/gcsc/replace-rpms.sh , replacing region with your region. Your Studio user’s execution role needs to be updated to allow the GetClusterSessionCredentials API action. SNAPSHOT20221121212949.noarch.rpm. noarch.rpm.
However, real-world data exists in multiple modalities, such as text, images, video, and audio. script with llava_inference.py , and create a model.tar.gz script has additional code to allow reading an image file from Amazon S3 and running inference on it. Take a PowerPoint slide deck, for example. file for this model.
Amazon Rekognition is a fully managed service that can perform CV tasks like object detection, video segment detection, content moderation, and more to extract insights from data without the need of any prior ML experience. For each option, we host an AWS Lambda function behind an API Gateway that is exposed to our mock application.
We provide a corresponding YouTube video that demonstrates what is discussed here. Video playback will start midway to highlight the most salient point. We suggest you follow this reading with the video to reinforce and gain a richer understanding of the concept. script that matches the model’s expected input and output.
We organize all of the trending information in your field so you don't have to. Join 34,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content